 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonitoring geometrical properties of word embeddings for detecting the emergence of new topics
Nov 05, 2021
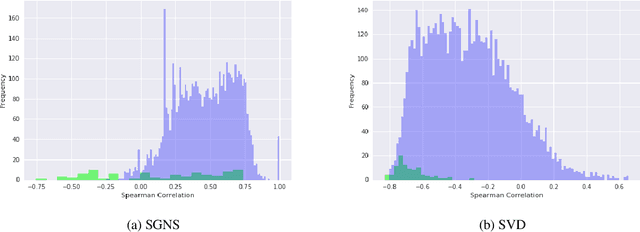


Slow emerging topic detection is a task between event detection, where we aggregate behaviors of different words on short period of time, and language evolution, where we monitor their long term evolution. In this work, we tackle the problem of early detection of slowly emerging new topics. To this end, we gather evidence of weak signals at the word level. We propose to monitor the behavior of words representation in an embedding space and use one of its geometrical properties to characterize the emergence of topics. As evaluation is typically hard for this kind of task, we present a framework for quantitative evaluation. We show positive results that outperform state-of-the-art methods on two public datasets of press and scientific articles.
How to detect novelty in textual data streams? A comparative study of existing methods
Sep 11, 2019


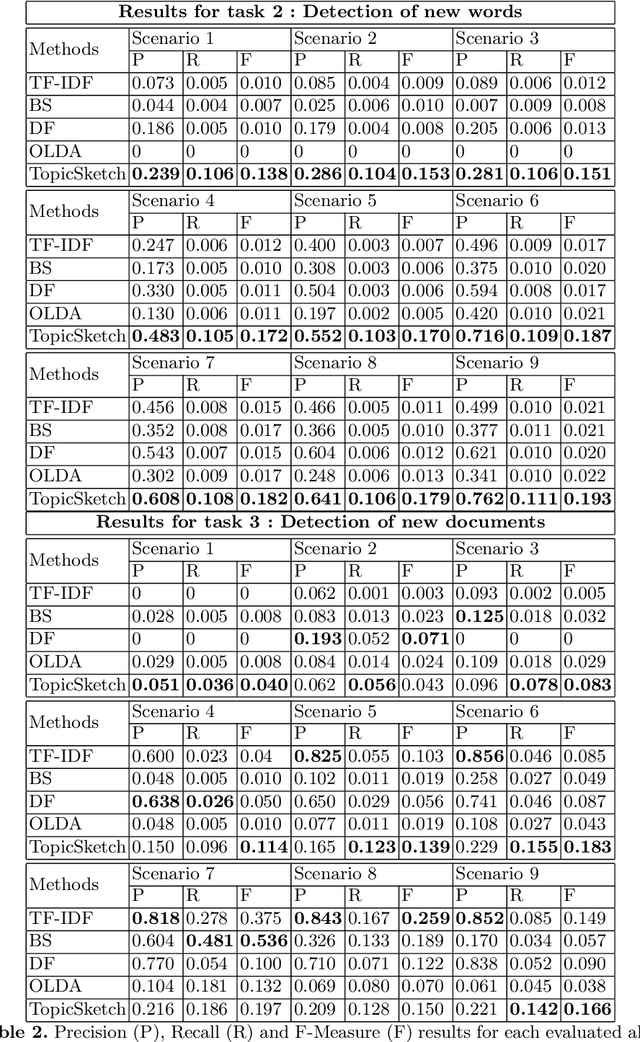
Since datasets with annotation for novelty at the document and/or word level are not easily available, we present a simulation framework that allows us to create different textual datasets in which we control the way novelty occurs. We also present a benchmark of existing methods for novelty detection in textual data streams. We define a few tasks to solve and compare several state-of-the-art methods. The simulation framework allows us to evaluate their performances according to a set of limited scenarios and test their sensitivity to some parameters. Finally, we experiment with the same methods on different kinds of novelty in the New York Times Annotated Dataset.