Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to detect novelty in textual data streams? A comparative study of existing methods
Paper and Code



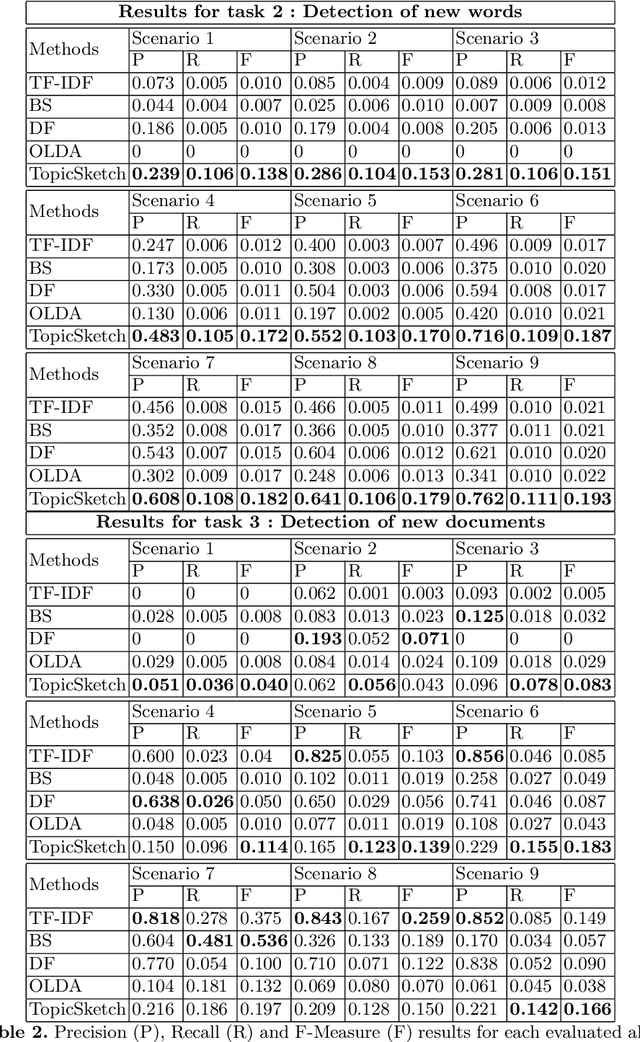
Since datasets with annotation for novelty at the document and/or word level are not easily available, we present a simulation framework that allows us to create different textual datasets in which we control the way novelty occurs. We also present a benchmark of existing methods for novelty detection in textual data streams. We define a few tasks to solve and compare several state-of-the-art methods. The simulation framework allows us to evaluate their performances according to a set of limited scenarios and test their sensitivity to some parameters. Finally, we experiment with the same methods on different kinds of novelty in the New York Times Annotated Dataset.
* 16 pages
View paper on