 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchitectures of Meaning, A Systematic Corpus Analysis of NLP Systems
Jul 16, 2021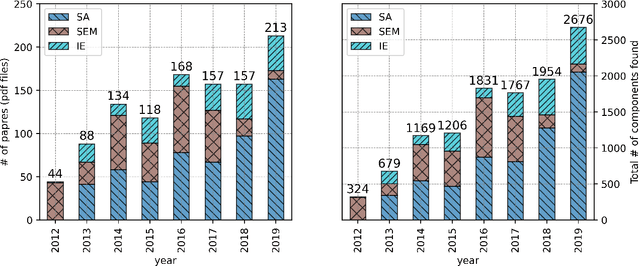
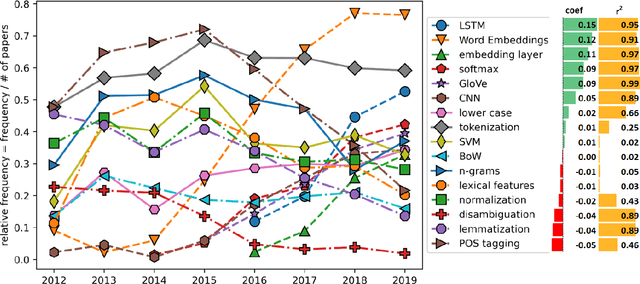
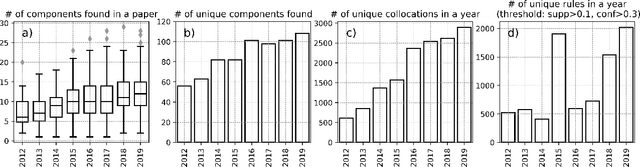
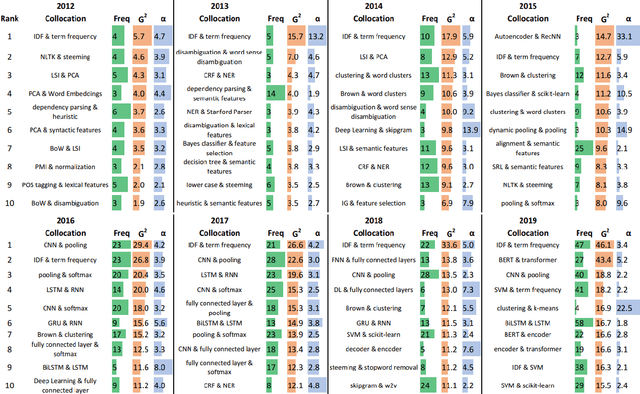
This paper proposes a novel statistical corpus analysis framework targeted towards the interpretation of Natural Language Processing (NLP) architectural patterns at scale. The proposed approach combines saturation-based lexicon construction, statistical corpus analysis methods and graph collocations to induce a synthesis representation of NLP architectural patterns from corpora. The framework is validated in the full corpus of Semeval tasks and demonstrated coherent architectural patterns which can be used to answer architectural questions on a data-driven fashion, providing a systematic mechanism to interpret a largely dynamic and exponentially growing field.
What is SemEval evaluating? A Systematic Analysis of Evaluation Campaigns in NLP
May 28, 2020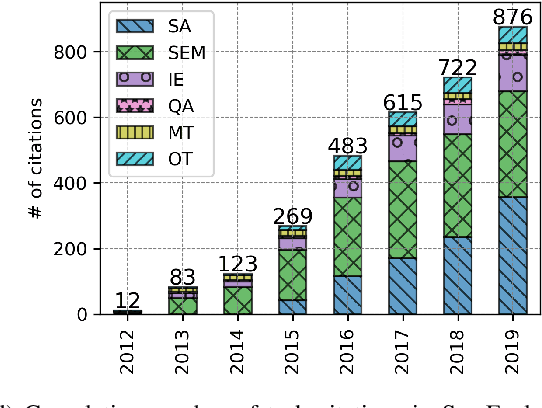
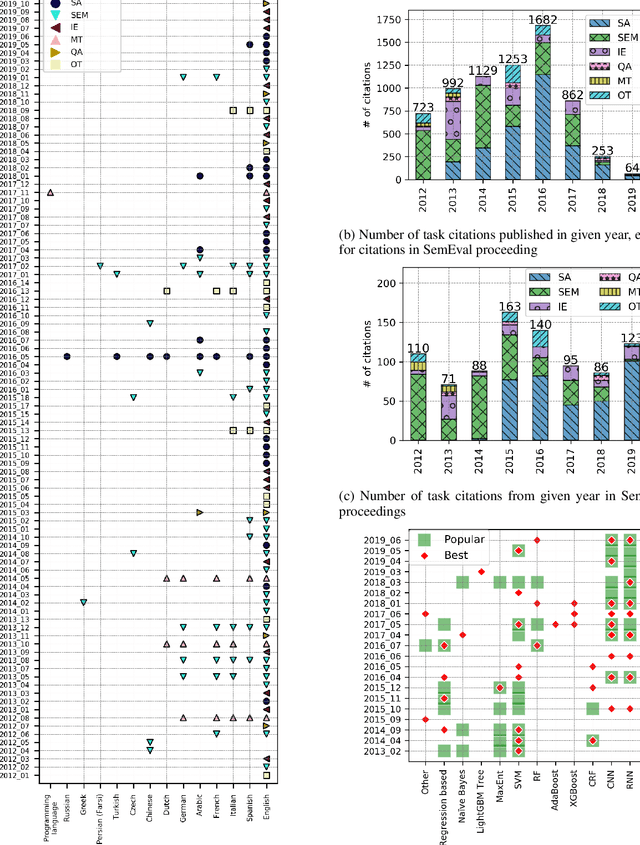
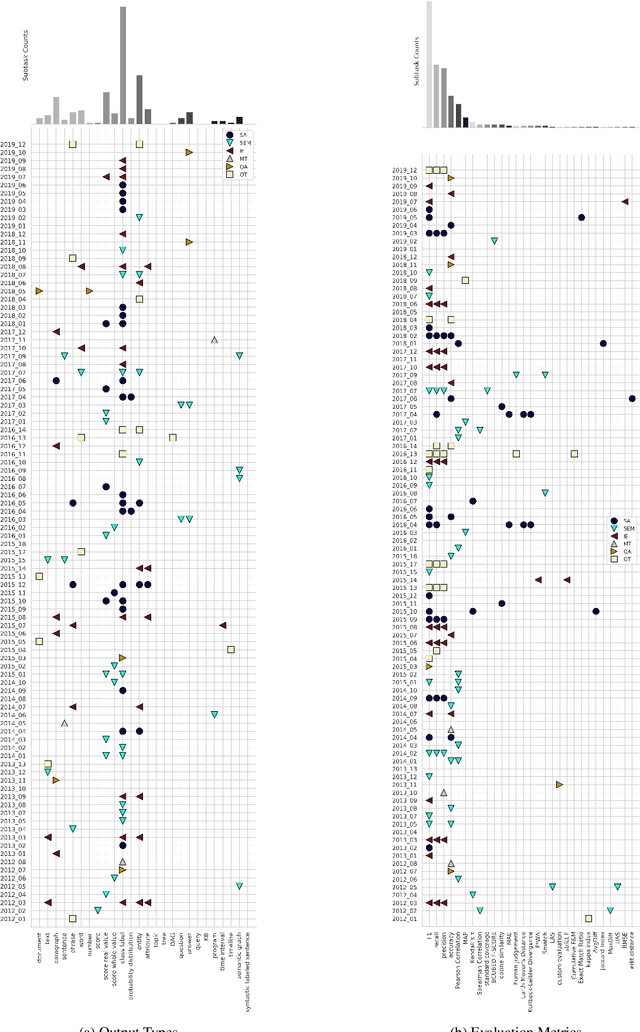
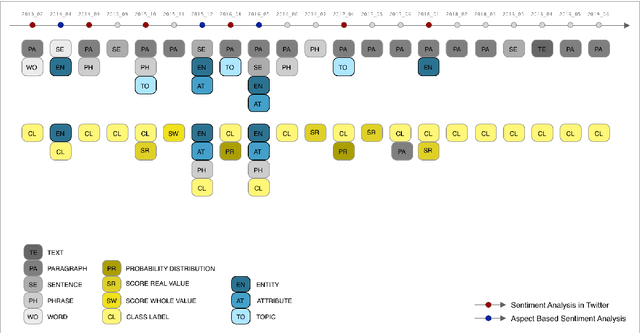
SemEval is the primary venue in the NLP community for the proposal of new challenges and for the systematic empirical evaluation of NLP systems. This paper provides a systematic quantitative analysis of SemEval aiming to evidence the patterns of the contributions behind SemEval. By understanding the distribution of task types, metrics, architectures, participation and citations over time we aim to answer the question on what is being evaluated by SemEval.