 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Generated Scientific Papers using an Ensemble of Transformer Models
Sep 17, 2022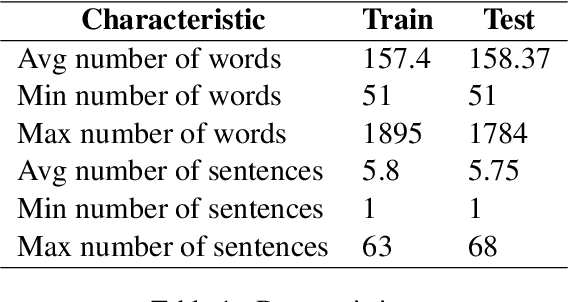
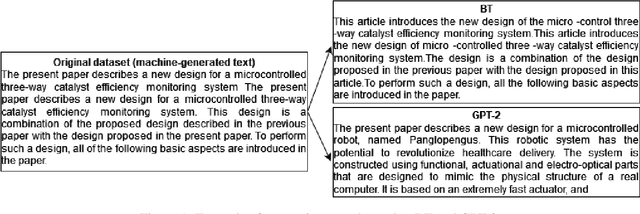

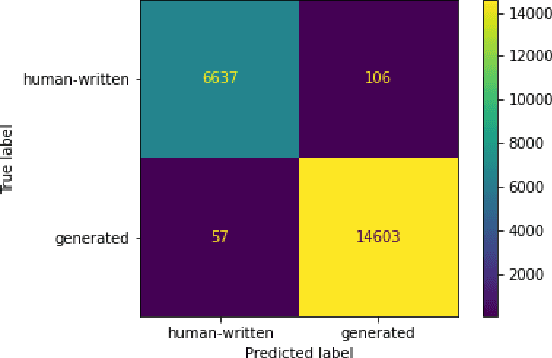
The paper describes neural models developed for the DAGPap22 shared task hosted at the Third Workshop on Scholarly Document Processing. This shared task targets the automatic detection of generated scientific papers. Our work focuses on comparing different transformer-based models as well as using additional datasets and techniques to deal with imbalanced classes. As a final submission, we utilized an ensemble of SciBERT, RoBERTa, and DeBERTa fine-tuned using random oversampling technique. Our model achieved 99.24% in terms of F1-score. The official evaluation results have put our system at the third place.
Fine-tuning of Pre-trained Transformers for Hate, Offensive, and Profane Content Detection in English and Marathi
Oct 25, 2021
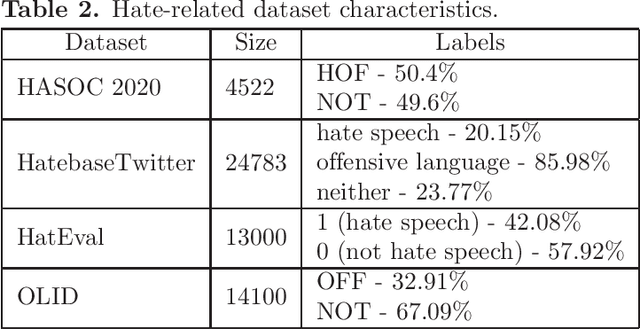
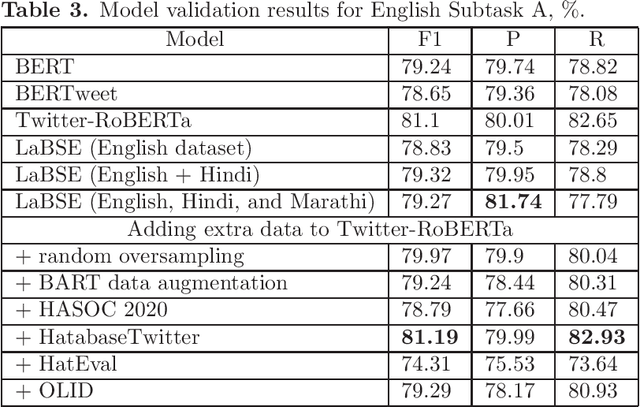

This paper describes neural models developed for the Hate Speech and Offensive Content Identification in English and Indo-Aryan Languages Shared Task 2021. Our team called neuro-utmn-thales participated in two tasks on binary and fine-grained classification of English tweets that contain hate, offensive, and profane content (English Subtasks A & B) and one task on identification of problematic content in Marathi (Marathi Subtask A). For English subtasks, we investigate the impact of additional corpora for hate speech detection to fine-tune transformer models. We also apply a one-vs-rest approach based on Twitter-RoBERTa to discrimination between hate, profane and offensive posts. Our models ranked third in English Subtask A with the F1-score of 81.99% and ranked second in English Subtask B with the F1-score of 65.77%. For the Marathi tasks, we propose a system based on the Language-Agnostic BERT Sentence Embedding (LaBSE). This model achieved the second result in Marathi Subtask A obtaining an F1 of 88.08%.
g2tmn at Constraint@AAAI2021: Exploiting CT-BERT and Ensembling Learning for COVID-19 Fake News Detection
Jan 13, 2021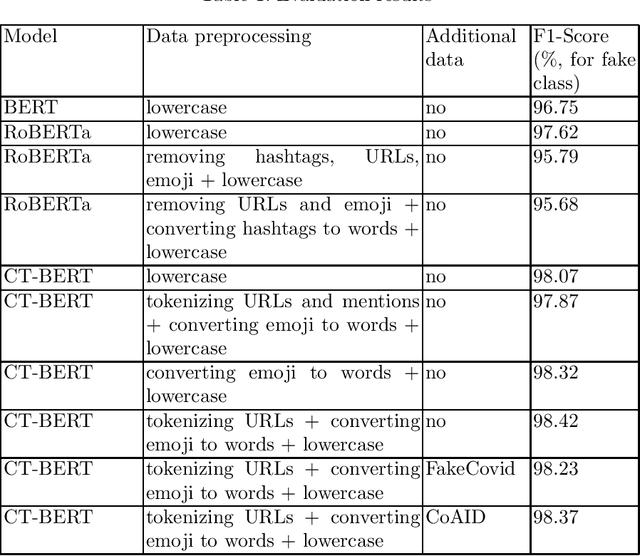
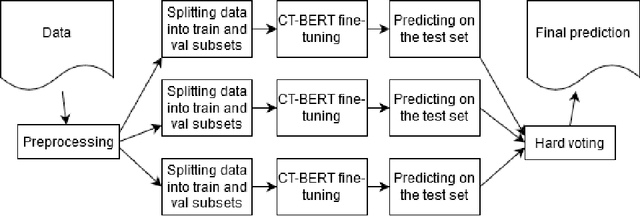

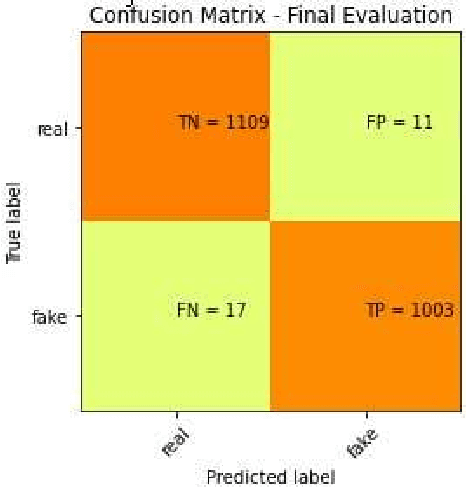
The COVID-19 pandemic has had a huge impact on various areas of human life. Hence, the coronavirus pandemic and its consequences are being actively discussed on social media. However, not all social media posts are truthful. Many of them spread fake news that cause panic among readers, misinform people and thus exacerbate the effect of the pandemic. In this paper, we present our results at the Constraint@AAAI2021 Shared Task: COVID-19 Fake News Detection in English. In particular, we propose our approach using the transformer-based ensemble of COVID-Twitter-BERT (CT-BERT) models. We describe the models used, the ways of text preprocessing and adding extra data. As a result, our best model achieved the weighted F1-score of 98.69 on the test set (the first place in the leaderboard) of this shared task that attracted 166 submitted teams in total.
A Comparative Study of Feature Types for Age-Based Text Classification
Sep 24, 2020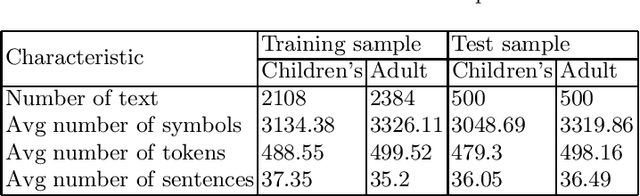
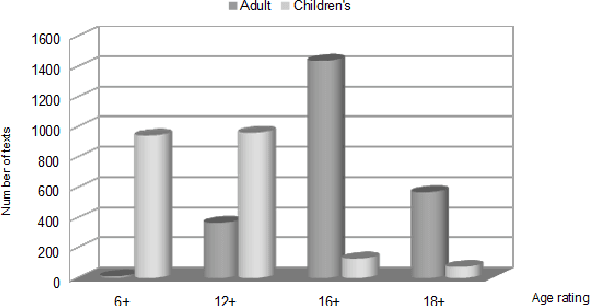

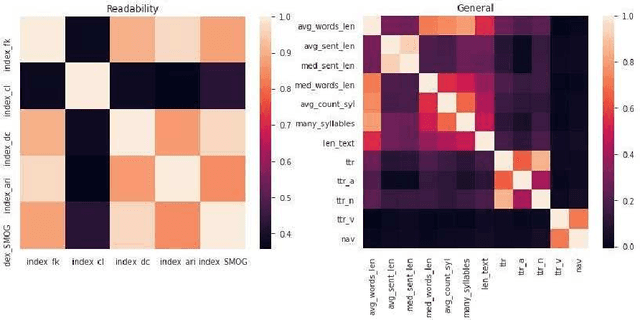
The ability to automatically determine the age audience of a novel provides many opportunities for the development of information retrieval tools. Firstly, developers of book recommendation systems and electronic libraries may be interested in filtering texts by the age of the most likely readers. Further, parents may want to select literature for children. Finally, it will be useful for writers and publishers to determine which features influence whether the texts are suitable for children. In this article, we compare the empirical effectiveness of various types of linguistic features for the task of age-based classification of fiction texts. For this purpose, we collected a text corpus of book previews labeled with one of two categories -- children's or adult. We evaluated the following types of features: readability indices, sentiment, lexical, grammatical and general features, and publishing attributes. The results obtained show that the features describing the text at the document level can significantly increase the quality of machine learning models.