 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Feature Types for Age-Based Text Classification
Paper and Code
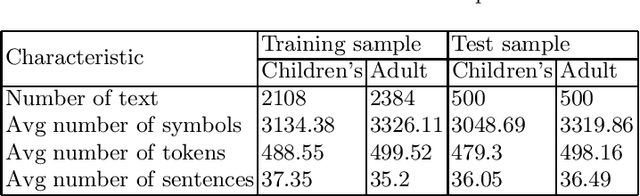
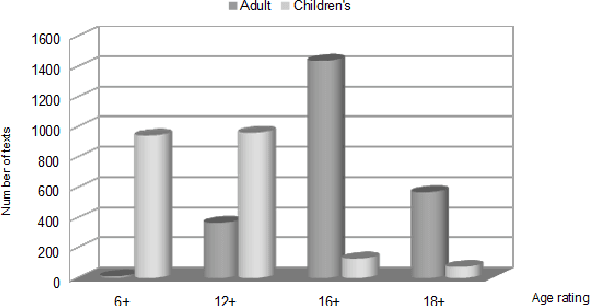

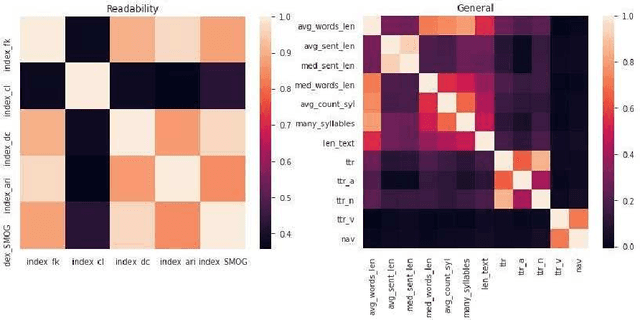
The ability to automatically determine the age audience of a novel provides many opportunities for the development of information retrieval tools. Firstly, developers of book recommendation systems and electronic libraries may be interested in filtering texts by the age of the most likely readers. Further, parents may want to select literature for children. Finally, it will be useful for writers and publishers to determine which features influence whether the texts are suitable for children. In this article, we compare the empirical effectiveness of various types of linguistic features for the task of age-based classification of fiction texts. For this purpose, we collected a text corpus of book previews labeled with one of two categories -- children's or adult. We evaluated the following types of features: readability indices, sentiment, lexical, grammatical and general features, and publishing attributes. The results obtained show that the features describing the text at the document level can significantly increase the quality of machine learning models.