 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning of Pre-trained Transformers for Hate, Offensive, and Profane Content Detection in English and Marathi
Paper and Code

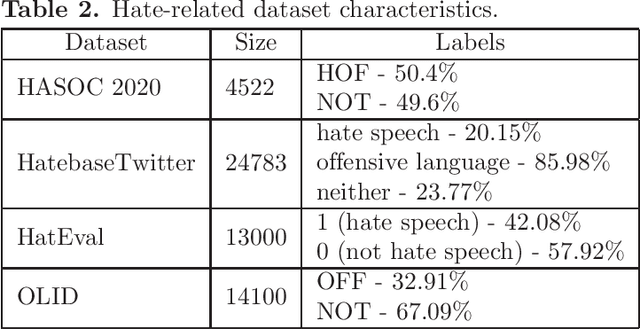
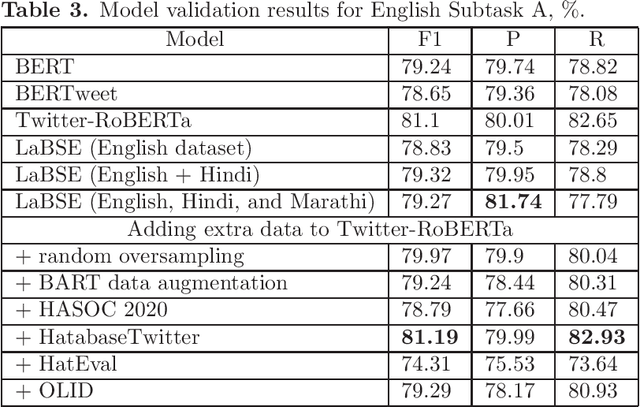

This paper describes neural models developed for the Hate Speech and Offensive Content Identification in English and Indo-Aryan Languages Shared Task 2021. Our team called neuro-utmn-thales participated in two tasks on binary and fine-grained classification of English tweets that contain hate, offensive, and profane content (English Subtasks A & B) and one task on identification of problematic content in Marathi (Marathi Subtask A). For English subtasks, we investigate the impact of additional corpora for hate speech detection to fine-tune transformer models. We also apply a one-vs-rest approach based on Twitter-RoBERTa to discrimination between hate, profane and offensive posts. Our models ranked third in English Subtask A with the F1-score of 81.99% and ranked second in English Subtask B with the F1-score of 65.77%. For the Marathi tasks, we propose a system based on the Language-Agnostic BERT Sentence Embedding (LaBSE). This model achieved the second result in Marathi Subtask A obtaining an F1 of 88.08%.