 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent Attacks and Defense Methods in Federated Learning-enabled Energy-Efficient Wireless Networks
Apr 25, 2025Federated learning (FL) is a promising technique for learning-based functions in wireless networks, thanks to its distributed implementation capability. On the other hand, distributed learning may increase the risk of exposure to malicious attacks where attacks on a local model may spread to other models by parameter exchange. Meanwhile, such attacks can be hard to detect due to the dynamic wireless environment, especially considering local models can be heterogeneous with non-independent and identically distributed (non-IID) data. Therefore, it is critical to evaluate the effect of malicious attacks and develop advanced defense techniques for FL-enabled wireless networks. In this work, we introduce a federated deep reinforcement learning-based cell sleep control scenario that enhances the energy efficiency of the network. We propose multiple intelligent attacks targeting the learning-based approach and we propose defense methods to mitigate such attacks. In particular, we have designed two attack models, generative adversarial network (GAN)-enhanced model poisoning attack and regularization-based model poisoning attack. As a counteraction, we have proposed two defense schemes, autoencoder-based defense, and knowledge distillation (KD)-enabled defense. The autoencoder-based defense method leverages an autoencoder to identify the malicious participants and only aggregate the parameters of benign local models during the global aggregation, while KD-based defense protects the model from attacks by controlling the knowledge transferred between the global model and local models.
Cooperation and Personalization on a Seesaw: Choice-based FL for Safe Cooperation in Wireless Networks
Nov 06, 2024



Federated learning (FL) is an innovative distributed artificial intelligence (AI) technique. It has been used for interdisciplinary studies in different fields such as healthcare, marketing and finance. However the application of FL in wireless networks is still in its infancy. In this work, we first overview benefits and concerns when applying FL to wireless networks. Next, we provide a new perspective on existing personalized FL frameworks by analyzing the relationship between cooperation and personalization in these frameworks. Additionally, we discuss the possibility of tuning the cooperation level with a choice-based approach. Our choice-based FL approach is a flexible and safe FL framework that allows participants to lower the level of cooperation when they feel unsafe or unable to benefit from the cooperation. In this way, the choice-based FL framework aims to address the safety and fairness concerns in FL and protect participants from malicious attacks.
Smart Jamming Attack and Mitigation on Deep Transfer Reinforcement Learning Enabled Resource Allocation for Network Slicing
Oct 07, 2024Network slicing is a pivotal paradigm in wireless networks enabling customized services to users and applications. Yet, intelligent jamming attacks threaten the performance of network slicing. In this paper, we focus on the security aspect of network slicing over a deep transfer reinforcement learning (DTRL) enabled scenario. We first demonstrate how a deep reinforcement learning (DRL)-enabled jamming attack exposes potential risks. In particular, the attacker can intelligently jam resource blocks (RBs) reserved for slices by monitoring transmission signals and perturbing the assigned resources. Then, we propose a DRL-driven mitigation model to mitigate the intelligent attacker. Specifically, the defense mechanism generates interference on unallocated RBs where another antenna is used for transmitting powerful signals. This causes the jammer to consider these RBs as allocated RBs and generate interference for those instead of the allocated RBs. The analysis revealed that the intelligent DRL-enabled jamming attack caused a significant 50% degradation in network throughput and 60% increase in latency in comparison with the no-attack scenario. However, with the implemented mitigation measures, we observed 80% improvement in network throughput and 70% reduction in latency in comparison to the under-attack scenario.
Self-Play Ensemble Q-learning enabled Resource Allocation for Network Slicing
Aug 19, 2024


In 5G networks, network slicing has emerged as a pivotal paradigm to address diverse user demands and service requirements. To meet the requirements, reinforcement learning (RL) algorithms have been utilized widely, but this method has the problem of overestimation and exploration-exploitation trade-offs. To tackle these problems, this paper explores the application of self-play ensemble Q-learning, an extended version of the RL-based technique. Self-play ensemble Q-learning utilizes multiple Q-tables with various exploration-exploitation rates leading to different observations for choosing the most suitable action for each state. Moreover, through self-play, each model endeavors to enhance its performance compared to its previous iterations, boosting system efficiency, and decreasing the effect of overestimation. For performance evaluation, we consider three RL-based algorithms; self-play ensemble Q-learning, double Q-learning, and Q-learning, and compare their performance under different network traffic. Through simulations, we demonstrate the effectiveness of self-play ensemble Q-learning in meeting the diverse demands within 21.92% in latency, 24.22% in throughput, and 23.63\% in packet drop rate in comparison with the baseline methods. Furthermore, we evaluate the robustness of self-play ensemble Q-learning and double Q-learning in situations where one of the Q-tables is affected by a malicious user. Our results depicted that the self-play ensemble Q-learning method is more robust against adversarial users and prevents a noticeable drop in system performance, mitigating the impact of users manipulating policies.
Federated Learning with Dual Attention for Robust Modulation Classification under Attacks
Jan 19, 2024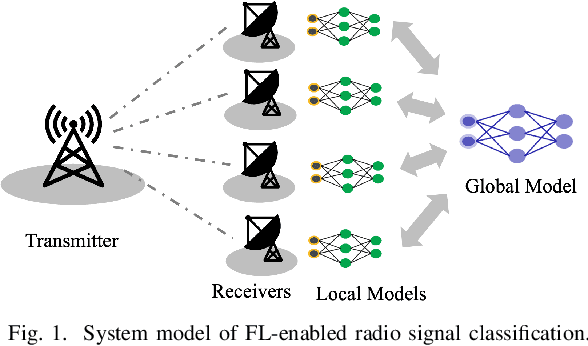
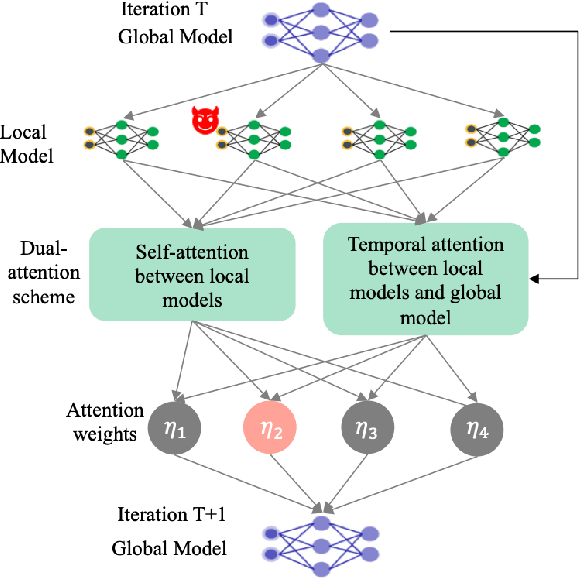

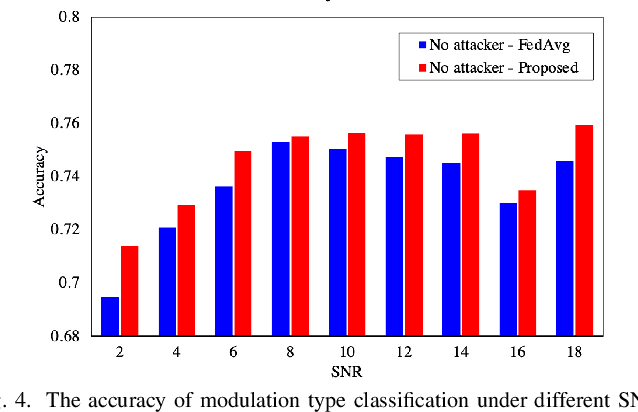
Federated learning (FL) allows distributed participants to train machine learning models in a decentralized manner. It can be used for radio signal classification with multiple receivers due to its benefits in terms of privacy and scalability. However, the existing FL algorithms usually suffer from slow and unstable convergence and are vulnerable to poisoning attacks from malicious participants. In this work, we aim to design a versatile FL framework that simultaneously promotes the performance of the model both in a secure system and under attack. To this end, we leverage attention mechanisms as a defense against attacks in FL and propose a robust FL algorithm by integrating the attention mechanisms into the global model aggregation step. To be more specific, two attention models are combined to calculate the amount of attention cast on each participant. It will then be used to determine the weights of local models during the global aggregation. The proposed algorithm is verified on a real-world dataset and it outperforms existing algorithms, both in secure systems and in systems under data poisoning attacks.
Beam Selection for Energy-Efficient mmWave Network Using Advantage Actor Critic Learning
Feb 01, 2023
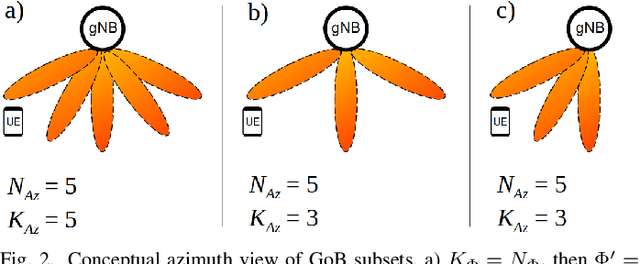


The growing adoption of mmWave frequency bands to realize the full potential of 5G, turns beamforming into a key enabler for current and next-generation wireless technologies. Many mmWave networks rely on beam selection with Grid-of-Beams (GoB) approach to handle user-beam association. In beam selection with GoB, users select the appropriate beam from a set of pre-defined beams and the overhead during the beam selection process is a common challenge in this area. In this paper, we propose an Advantage Actor Critic (A2C) learning-based framework to improve the GoB and the beam selection process, as well as optimize transmission power in a mmWave network. The proposed beam selection technique allows performance improvement while considering transmission power improves Energy Efficiency (EE) and ensures the coverage is maintained in the network. We further investigate how the proposed algorithm can be deployed in a Service Management and Orchestration (SMO) platform. Our simulations show that A2C-based joint optimization of beam selection and transmission power is more effective than using Equally Spaced Beams (ESB) and fixed power strategy, or optimization of beam selection and transmission power disjointly. Compared to the ESB and fixed transmission power strategy, the proposed approach achieves more than twice the average EE in the scenarios under test and is closer to the maximum theoretical EE.
Hierarchical Deep Q-Learning Based Handover in Wireless Networks with Dual Connectivity
Jan 13, 2023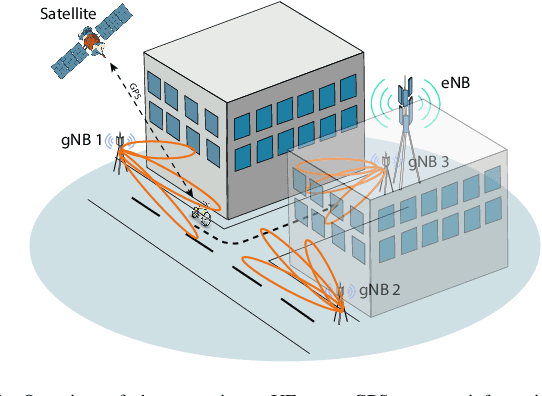
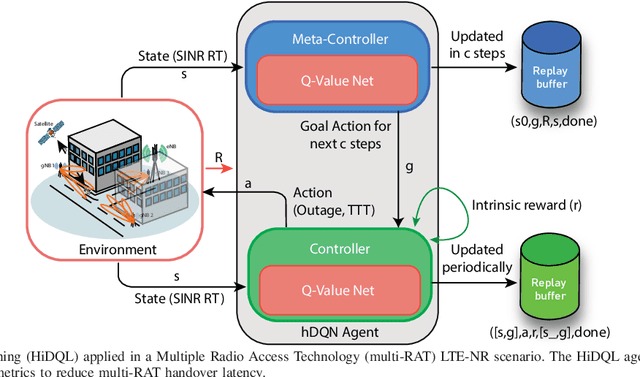
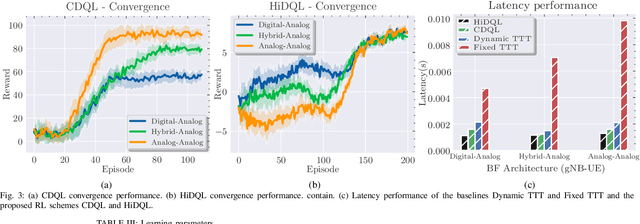
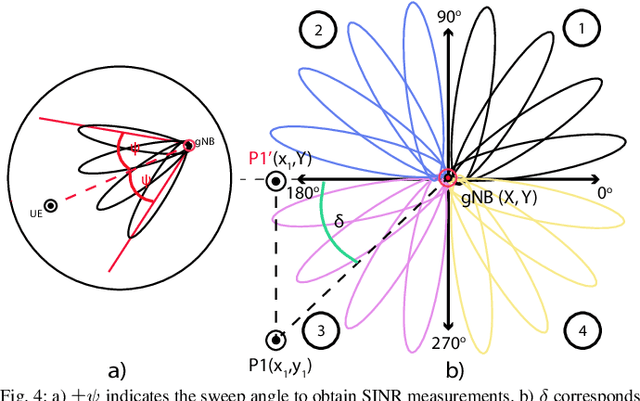
5G New Radio proposes the usage of frequencies above 10 GHz to speed up LTE's existent maximum data rates. However, the effective size of 5G antennas and consequently its repercussions in the signal degradation in urban scenarios makes it a challenge to maintain stable coverage and connectivity. In order to obtain the best from both technologies, recent dual connectivity solutions have proved their capabilities to improve performance when compared with coexistent standalone 5G and 4G technologies. Reinforcement learning (RL) has shown its huge potential in wireless scenarios where parameter learning is required given the dynamic nature of such context. In this paper, we propose two reinforcement learning algorithms: a single agent RL algorithm named Clipped Double Q-Learning (CDQL) and a hierarchical Deep Q-Learning (HiDQL) to improve Multiple Radio Access Technology (multi-RAT) dual-connectivity handover. We compare our proposal with two baselines: a fixed parameter and a dynamic parameter solution. Simulation results reveal significant improvements in terms of latency with a gain of 47.6% and 26.1% for Digital-Analog beamforming (BF), 17.1% and 21.6% for Hybrid-Analog BF, and 24.7% and 39% for Analog-Analog BF when comparing the RL-schemes HiDQL and CDQL with the with the existent solutions, HiDQL presented a slower convergence time, however obtained a more optimal solution than CDQL. Additionally, we foresee the advantages of utilizing context-information as geo-location of the UEs to reduce the beam exploration sector, and thus improving further multi-RAT handover latency results.
Hierarchical Reinforcement Learning for RIS-Assisted Energy-Efficient RAN
Jan 07, 2023Reconfigurable intelligent surface (RIS) is emerging as a promising technology to boost the energy efficiency (EE) of 5G beyond and 6G networks. Inspired by this potential, in this paper, we investigate the RIS-assisted energy-efficient radio access networks (RAN). In particular, we combine RIS with sleep control techniques, and develop a hierarchical reinforcement learning (HRL) algorithm for network management. In HRL, the meta-controller decides the on/off status of the small base stations (SBSs) in heterogeneous networks, while the sub-controller can change the transmission power levels of SBSs to save energy. The simulations show that the RIS-assisted sleep control can achieve significantly lower energy consumption, higher throughput, and more than doubled energy efficiency than no-RIS conditions.