 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Play Ensemble Q-learning enabled Resource Allocation for Network Slicing
Aug 19, 2024


In 5G networks, network slicing has emerged as a pivotal paradigm to address diverse user demands and service requirements. To meet the requirements, reinforcement learning (RL) algorithms have been utilized widely, but this method has the problem of overestimation and exploration-exploitation trade-offs. To tackle these problems, this paper explores the application of self-play ensemble Q-learning, an extended version of the RL-based technique. Self-play ensemble Q-learning utilizes multiple Q-tables with various exploration-exploitation rates leading to different observations for choosing the most suitable action for each state. Moreover, through self-play, each model endeavors to enhance its performance compared to its previous iterations, boosting system efficiency, and decreasing the effect of overestimation. For performance evaluation, we consider three RL-based algorithms; self-play ensemble Q-learning, double Q-learning, and Q-learning, and compare their performance under different network traffic. Through simulations, we demonstrate the effectiveness of self-play ensemble Q-learning in meeting the diverse demands within 21.92% in latency, 24.22% in throughput, and 23.63\% in packet drop rate in comparison with the baseline methods. Furthermore, we evaluate the robustness of self-play ensemble Q-learning and double Q-learning in situations where one of the Q-tables is affected by a malicious user. Our results depicted that the self-play ensemble Q-learning method is more robust against adversarial users and prevents a noticeable drop in system performance, mitigating the impact of users manipulating policies.
Beam Selection for Energy-Efficient mmWave Network Using Advantage Actor Critic Learning
Feb 01, 2023
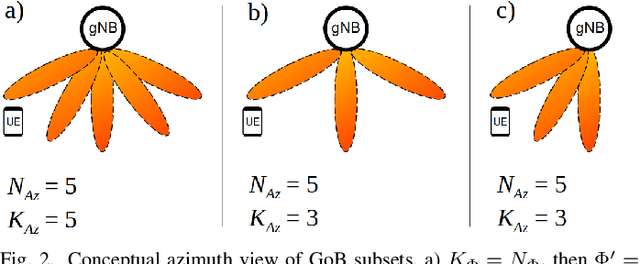


The growing adoption of mmWave frequency bands to realize the full potential of 5G, turns beamforming into a key enabler for current and next-generation wireless technologies. Many mmWave networks rely on beam selection with Grid-of-Beams (GoB) approach to handle user-beam association. In beam selection with GoB, users select the appropriate beam from a set of pre-defined beams and the overhead during the beam selection process is a common challenge in this area. In this paper, we propose an Advantage Actor Critic (A2C) learning-based framework to improve the GoB and the beam selection process, as well as optimize transmission power in a mmWave network. The proposed beam selection technique allows performance improvement while considering transmission power improves Energy Efficiency (EE) and ensures the coverage is maintained in the network. We further investigate how the proposed algorithm can be deployed in a Service Management and Orchestration (SMO) platform. Our simulations show that A2C-based joint optimization of beam selection and transmission power is more effective than using Equally Spaced Beams (ESB) and fixed power strategy, or optimization of beam selection and transmission power disjointly. Compared to the ESB and fixed transmission power strategy, the proposed approach achieves more than twice the average EE in the scenarios under test and is closer to the maximum theoretical EE.