 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Continuous-Time Markov Models
Dec 11, 2022
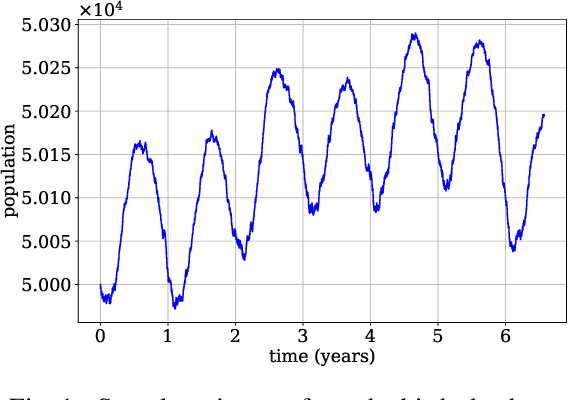
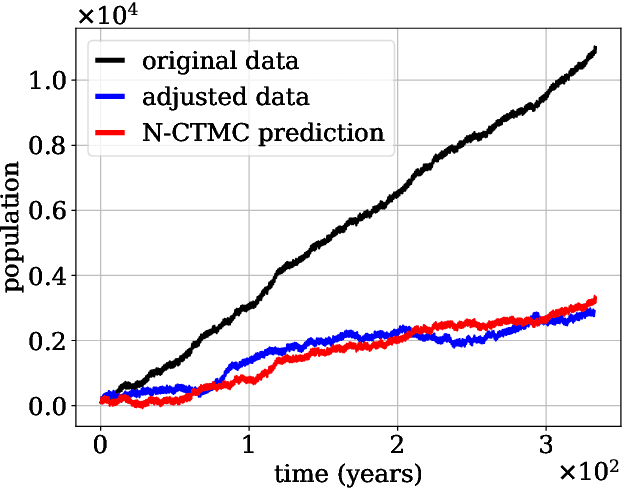
Continuous-time Markov chains are used to model stochastic systems where transitions can occur at irregular times, e.g., birth-death processes, chemical reaction networks, population dynamics, and gene regulatory networks. We develop a method to learn a continuous-time Markov chain's transition rate functions from fully observed time series. In contrast with existing methods, our method allows for transition rates to depend nonlinearly on both state variables and external covariates. The Gillespie algorithm is used to generate trajectories of stochastic systems where propensity functions (reaction rates) are known. Our method can be viewed as the inverse: given trajectories of a stochastic reaction network, we generate estimates of the propensity functions. While previous methods used linear or log-linear methods to link transition rates to covariates, we use neural networks, increasing the capacity and potential accuracy of learned models. In the chemical context, this enables the method to learn propensity functions from non-mass-action kinetics. We test our method with synthetic data generated from a variety of systems with known transition rates. We show that our method learns these transition rates with considerably more accuracy than log-linear methods, in terms of mean absolute error between ground truth and predicted transition rates. We also demonstrate an application of our methods to open-loop control of a continuous-time Markov chain.
Estimating Vector Fields from Noisy Time Series
Dec 06, 2020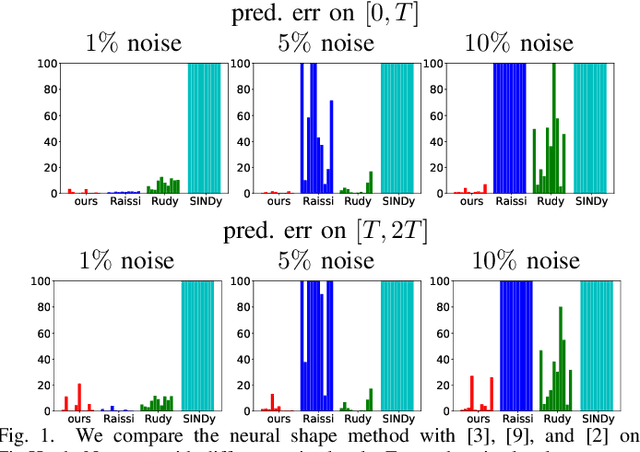
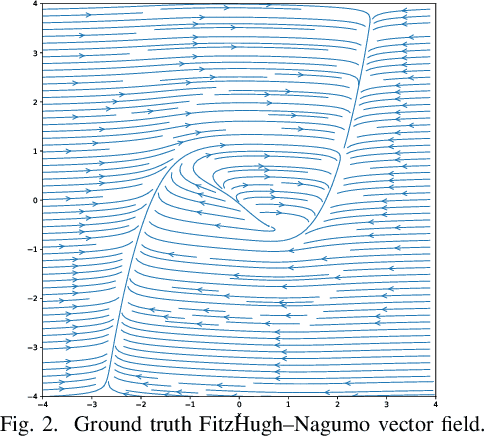
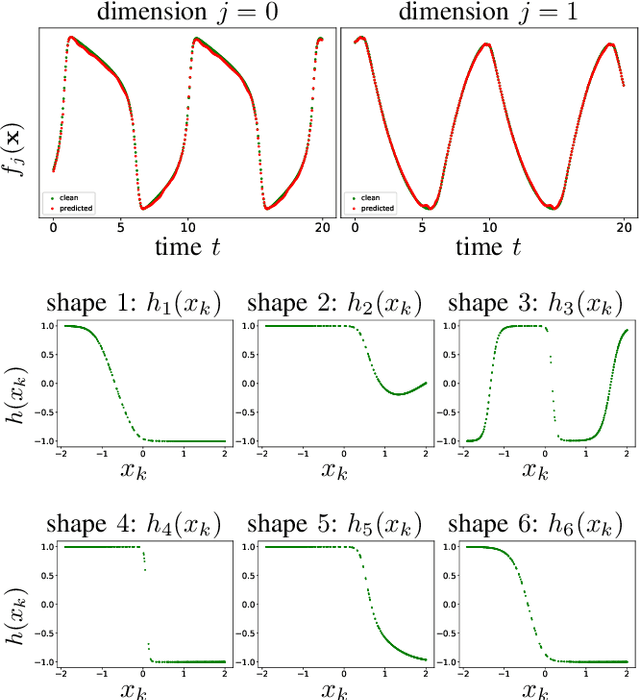
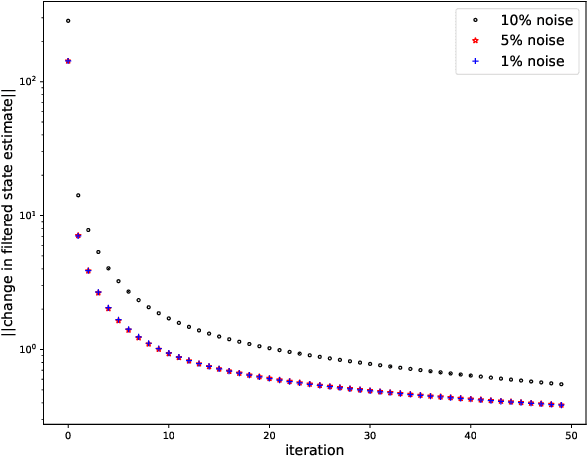
While there has been a surge of recent interest in learning differential equation models from time series, methods in this area typically cannot cope with highly noisy data. We break this problem into two parts: (i) approximating the unknown vector field (or right-hand side) of the differential equation, and (ii) dealing with noise. To deal with (i), we describe a neural network architecture consisting of tensor products of one-dimensional neural shape functions. For (ii), we propose an alternating minimization scheme that switches between vector field training and filtering steps, together with multiple trajectories of training data. We find that the neural shape function architecture retains the approximation properties of dense neural networks, enables effective computation of vector field error, and allows for graphical interpretability, all for data/systems in any finite dimension $d$. We also study the combination of either our neural shape function method or existing differential equation learning methods with alternating minimization and multiple trajectories. We find that retrofitting any learning method in this way boosts the method's robustness to noise. While in their raw form the methods struggle with 1% Gaussian noise, after retrofitting, they learn accurate vector fields from data with 10% Gaussian noise.