 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Compositional Approaches for Focus and Sentiment Analysis
Aug 11, 2025

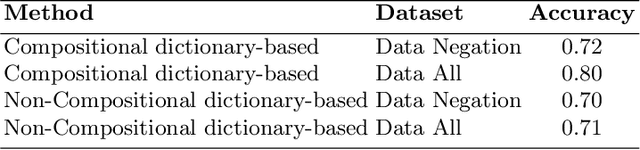

This paper summarizes the results of evaluating a compositional approach for Focus Analysis (FA) in Linguistics and Sentiment Analysis (SA) in Natural Language Processing (NLP). While quantitative evaluations of compositional and non-compositional approaches in SA exist in NLP, similar quantitative evaluations are very rare in FA in Linguistics that deal with linguistic expressions representing focus or emphasis such as "it was John who left". We fill this gap in research by arguing that compositional rules in SA also apply to FA because FA and SA are closely related meaning that SA is part of FA. Our compositional approach in SA exploits basic syntactic rules such as rules of modification, coordination, and negation represented in the formalism of Universal Dependencies (UDs) in English and applied to words representing sentiments from sentiment dictionaries. Some of the advantages of our compositional analysis method for SA in contrast to non-compositional analysis methods are interpretability and explainability. We test the accuracy of our compositional approach and compare it with a non-compositional approach VADER that uses simple heuristic rules to deal with negation, coordination and modification. In contrast to previous related work that evaluates compositionality in SA on long reviews, this study uses more appropriate datasets to evaluate compositionality. In addition, we generalize the results of compositional approaches in SA to compositional approaches in FA.
Unveiling factors influencing judgment variation in Sentiment Analysis with Natural Language Processing and Statistics
May 20, 2024TripAdvisor reviews and comparable data sources play an important role in many tasks in Natural Language Processing (NLP), providing a data basis for the identification and classification of subjective judgments, such as hotel or restaurant reviews, into positive or negative polarities. This study explores three important factors influencing variation in crowdsourced polarity judgments, focusing on TripAdvisor reviews in Spanish. Three hypotheses are tested: the role of Part Of Speech (POS), the impact of sentiment words such as "tasty", and the influence of neutral words like "ok" on judgment variation. The study's methodology employs one-word titles, demonstrating their efficacy in studying polarity variation of words. Statistical tests on mean equality are performed on word groups of our interest. The results of this study reveal that adjectives in one-word titles tend to result in lower judgment variation compared to other word types or POS. Sentiment words contribute to lower judgment variation as well, emphasizing the significance of sentiment words in research on polarity judgments, and neutral words are associated with higher judgment variation as expected. However, these effects cannot be always reproduced in longer titles, which suggests that longer titles do not represent the best data source for testing the ambiguity of single words due to the influence on word polarity by other words like negation in longer titles. This empirical investigation contributes valuable insights into the factors influencing polarity variation of words, providing a foundation for NLP practitioners that aim to capture and predict polarity judgments in Spanish and for researchers that aim to understand factors influencing judgment variation.
Experimenting with UD Adaptation of an Unsupervised Rule-based Approach for Sentiment Analysis of Mexican Tourist Texts
Sep 11, 2023This paper summarizes the results of experimenting with Universal Dependencies (UD) adaptation of an Unsupervised, Compositional and Recursive (UCR) rule-based approach for Sentiment Analysis (SA) submitted to the Shared Task at Rest-Mex 2023 (Team Olga/LyS-SALSA) (within the IberLEF 2023 conference). By using basic syntactic rules such as rules of modification and negation applied on words from sentiment dictionaries, our approach exploits some advantages of an unsupervised method for SA: (1) interpretability and explainability of SA, (2) robustness across datasets, languages and domains and (3) usability by non-experts in NLP. We compare our approach with other unsupervised approaches of SA that in contrast to our UCR rule-based approach use simple heuristic rules to deal with negation and modification. Our results show a considerable improvement over these approaches. We discuss future improvements of our results by using modality features as another shifting rule of polarity and word disambiguation techniques to identify the right sentiment words.