 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Architecture Barrier: A Method for Efficient Knowledge Transfer Across Networks
Dec 28, 2022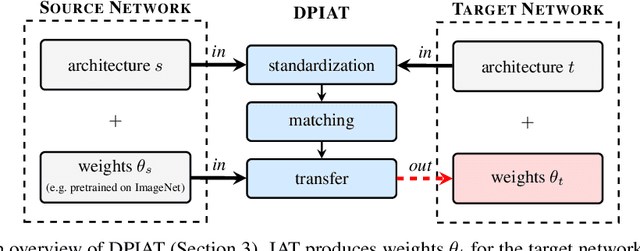
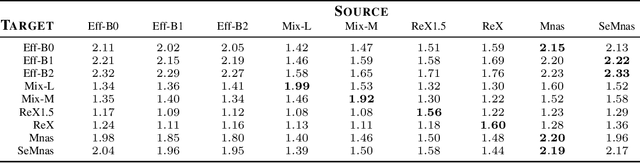

Transfer learning is a popular technique for improving the performance of neural networks. However, existing methods are limited to transferring parameters between networks with same architectures. We present a method for transferring parameters between neural networks with different architectures. Our method, called DPIAT, uses dynamic programming to match blocks and layers between architectures and transfer parameters efficiently. Compared to existing parameter prediction and random initialization methods, it significantly improves training efficiency and validation accuracy. In experiments on ImageNet, our method improved validation accuracy by an average of 1.6 times after 50 epochs of training. DPIAT allows both researchers and neural architecture search systems to modify trained networks and reuse knowledge, avoiding the need for retraining from scratch. We also introduce a network architecture similarity measure, enabling users to choose the best source network without any training.
Transfer Learning Between Different Architectures Via Weights Injection
Jan 07, 2021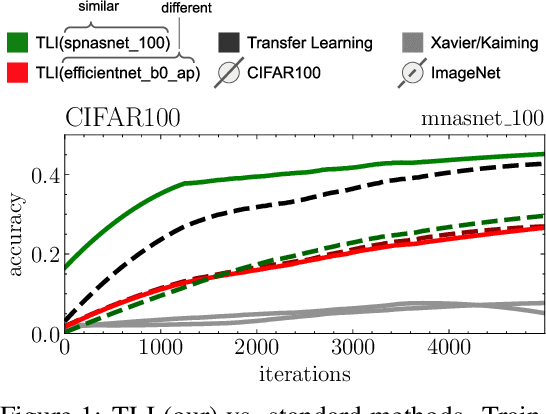
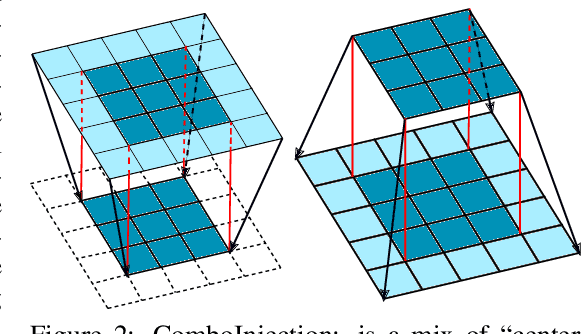
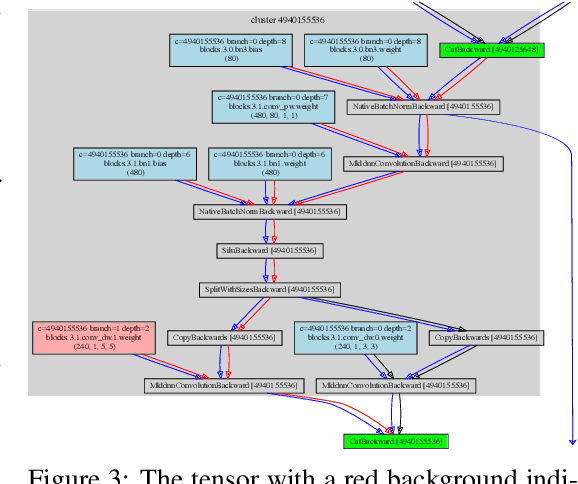
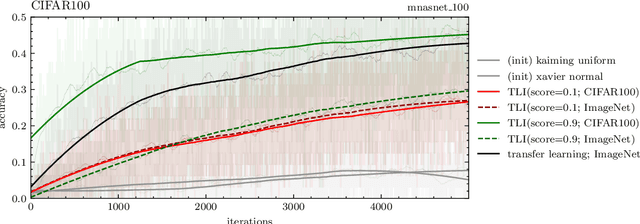
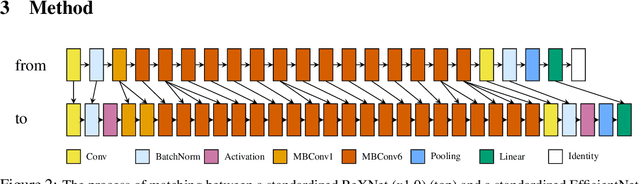
This work presents a naive algorithm for parameter transfer between different architectures with a computationally cheap injection technique (which does not require data). The primary objective is to speed up the training of neural networks from scratch. It was found in this study that transferring knowledge from any architecture was superior to Kaiming and Xavier for initialization. In conclusion, the method presented is found to converge faster, which makes it a drop-in replacement for classical methods. The method involves: 1) matching: the layers of the pre-trained model with the targeted model; 2) injection: the tensor is transformed into a desired shape. This work provides a comparison of similarity between the current SOTA architectures (ImageNet), by utilising TLI (Transfer Learning by Injection) score.
batchboost: regularization for stabilizing training with resistance to underfitting & overfitting
Jan 21, 2020


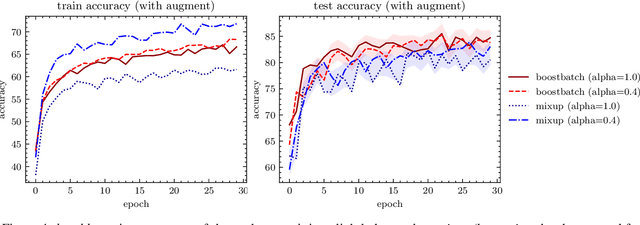
Overfitting & underfitting and stable training are an important challenges in machine learning. Current approaches for these issues are mixup, SamplePairing and BC learning. In our work, we state the hypothesis that mixing many images together can be more effective than just two. Batchboost pipeline has three stages: (a) pairing: method of selecting two samples. (b) mixing: how to create a new one from two samples. (c) feeding: combining mixed samples with new ones from dataset into batch (with ratio $\gamma$). Note that sample that appears in our batch propagates with subsequent iterations with less and less importance until the end of training. Pairing stage calculates the error per sample, sorts the samples and pairs with strategy: hardest with easiest one, than mixing stage merges two samples using mixup, $x_1 + (1-\lambda)x_2$. Finally, feeding stage combines new samples with mixed by ratio 1:1. Batchboost has 0.5-3% better accuracy than the current state-of-the-art mixup regularization on CIFAR-10 & Fashion-MNIST. Our method is slightly better than SamplePairing technique on small datasets (up to 5%). Batchboost provides stable training on not tuned parameters (like weight decay), thus its a good method to test performance of different architectures. Source code is at: https://github.com/maciejczyzewski/batchboost
Chessboard and chess piece recognition with the support of neural networks
Oct 16, 2018
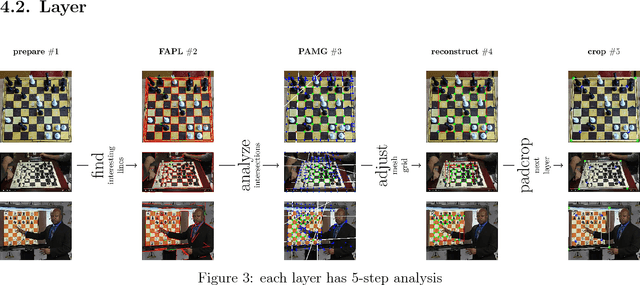

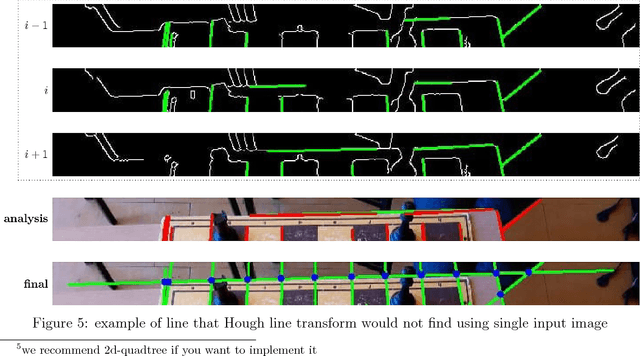
Chessboard and chess piece recognition is a computer vision problem that has not yet been efficiently solved. However, its solution is crucial for many experienced players who wish to compete against AI bots, but also prefer to make decisions based on the analysis of a physical chessboard. It is also important for organizers of chess tournaments who wish to digitize play for online broadcasting or ordinary players who wish to share their gameplay with friends. Typically, such digitization tasks are performed by humans or with the aid of specialized chessboards and pieces. However, neither solution is easy or convenient. To solve this problem, we propose a novel algorithm for digitizing chessboard configurations. We designed a method that is resistant to lighting conditions and the angle at which images are captured, and works correctly with numerous chessboard styles. The proposed algorithm processes pictures iteratively. During each iteration, it executes three major sub-processes: detecting straight lines, finding lattice points, and positioning the chessboard. Finally, we identify all chess pieces and generate a description of the board utilizing standard notation. For each of these steps, we designed our own algorithm that surpasses existing solutions. We support our algorithms by utilizing machine learning techniques whenever possible. The described method performs extraordinarily well and achieves an accuracy over $99.5\%$ for detecting chessboard lattice points (compared to the $74\%$ for the best alternative), $95\%$ (compared to $60\%$ for the best alternative) for positioning the chessboard in an image, and almost $95\%$ for chess piece recognition.