 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Architecture Barrier: A Method for Efficient Knowledge Transfer Across Networks
Dec 28, 2022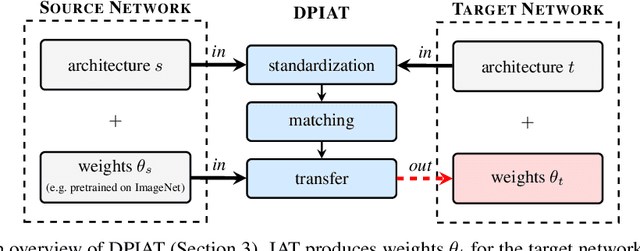
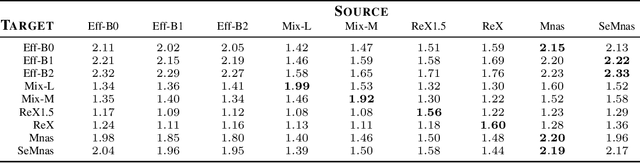
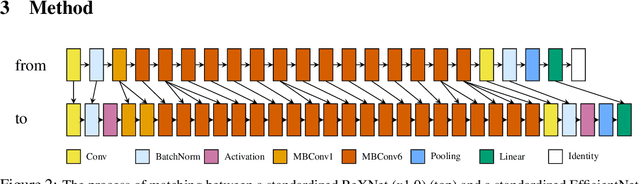

Transfer learning is a popular technique for improving the performance of neural networks. However, existing methods are limited to transferring parameters between networks with same architectures. We present a method for transferring parameters between neural networks with different architectures. Our method, called DPIAT, uses dynamic programming to match blocks and layers between architectures and transfer parameters efficiently. Compared to existing parameter prediction and random initialization methods, it significantly improves training efficiency and validation accuracy. In experiments on ImageNet, our method improved validation accuracy by an average of 1.6 times after 50 epochs of training. DPIAT allows both researchers and neural architecture search systems to modify trained networks and reuse knowledge, avoiding the need for retraining from scratch. We also introduce a network architecture similarity measure, enabling users to choose the best source network without any training.