 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgebatchboost: regularization for stabilizing training with resistance to underfitting & overfitting
Paper and Code



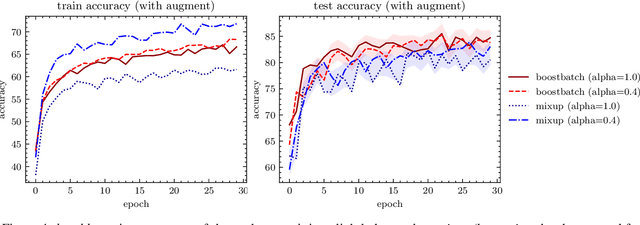
Overfitting & underfitting and stable training are an important challenges in machine learning. Current approaches for these issues are mixup, SamplePairing and BC learning. In our work, we state the hypothesis that mixing many images together can be more effective than just two. Batchboost pipeline has three stages: (a) pairing: method of selecting two samples. (b) mixing: how to create a new one from two samples. (c) feeding: combining mixed samples with new ones from dataset into batch (with ratio $\gamma$). Note that sample that appears in our batch propagates with subsequent iterations with less and less importance until the end of training. Pairing stage calculates the error per sample, sorts the samples and pairs with strategy: hardest with easiest one, than mixing stage merges two samples using mixup, $x_1 + (1-\lambda)x_2$. Finally, feeding stage combines new samples with mixed by ratio 1:1. Batchboost has 0.5-3% better accuracy than the current state-of-the-art mixup regularization on CIFAR-10 & Fashion-MNIST. Our method is slightly better than SamplePairing technique on small datasets (up to 5%). Batchboost provides stable training on not tuned parameters (like weight decay), thus its a good method to test performance of different architectures. Source code is at: https://github.com/maciejczyzewski/batchboost