 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning Between Different Architectures Via Weights Injection
Paper and Code
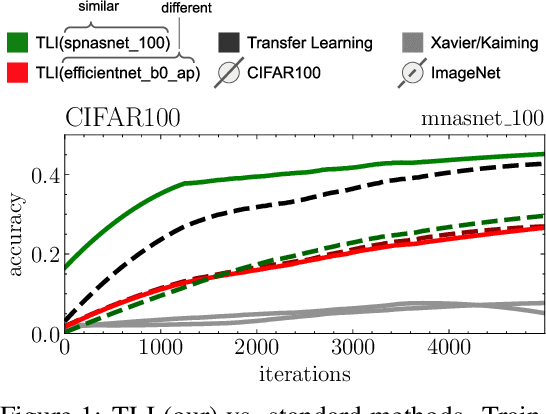
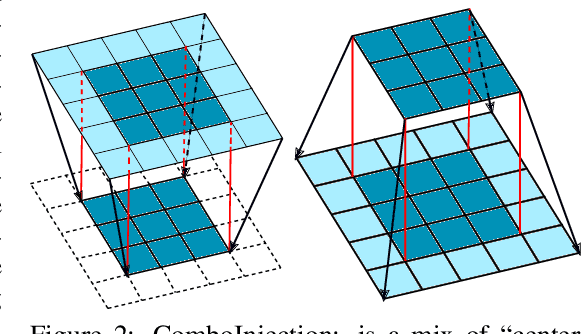
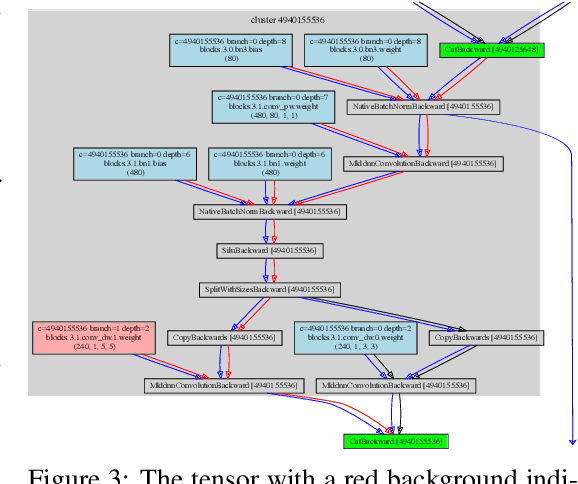
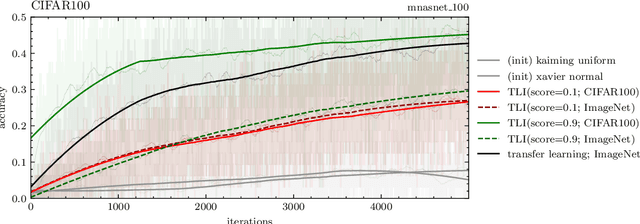
This work presents a naive algorithm for parameter transfer between different architectures with a computationally cheap injection technique (which does not require data). The primary objective is to speed up the training of neural networks from scratch. It was found in this study that transferring knowledge from any architecture was superior to Kaiming and Xavier for initialization. In conclusion, the method presented is found to converge faster, which makes it a drop-in replacement for classical methods. The method involves: 1) matching: the layers of the pre-trained model with the targeted model; 2) injection: the tensor is transformed into a desired shape. This work provides a comparison of similarity between the current SOTA architectures (ImageNet), by utilising TLI (Transfer Learning by Injection) score.