 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Policy Learning with Weight Clipping and Heaviside Composite Optimization
Jan 17, 2026Offline policy learning aims to use historical data to learn an optimal personalized decision rule. In the standard estimate-then-optimize framework, reweighting-based methods (e.g., inverse propensity weighting or doubly robust estimators) are widely used to produce unbiased estimates of policy values. However, when the propensity scores of some treatments are small, these reweighting-based methods suffer from high variance in policy value estimation, which may mislead the downstream policy optimization and yield a learned policy with inferior value. In this paper, we systematically develop an offline policy learning algorithm based on a weight-clipping estimator that truncates small propensity scores via a clipping threshold chosen to minimize the mean squared error (MSE) in policy value estimation. Focusing on linear policies, we address the bilevel and discontinuous objective induced by weight-clipping-based policy optimization by reformulating the problem as a Heaviside composite optimization problem, which provides a rigorous computational framework. The reformulated policy optimization problem is then solved efficiently using the progressive integer programming method, making practical policy learning tractable. We establish an upper bound for the suboptimality of the proposed algorithm, which reveals how the reduction in MSE of policy value estimation, enabled by our proposed weight-clipping estimator, leads to improved policy learning performance.
Online Resource Allocation with Non-Stationary Customers
Jan 30, 2024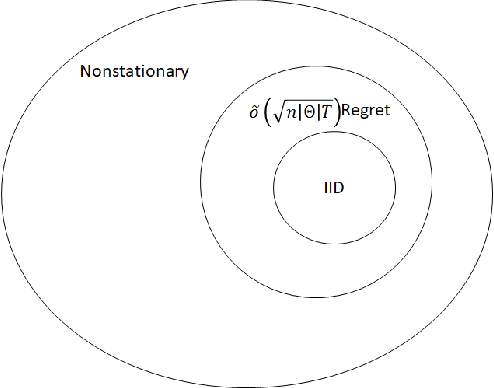
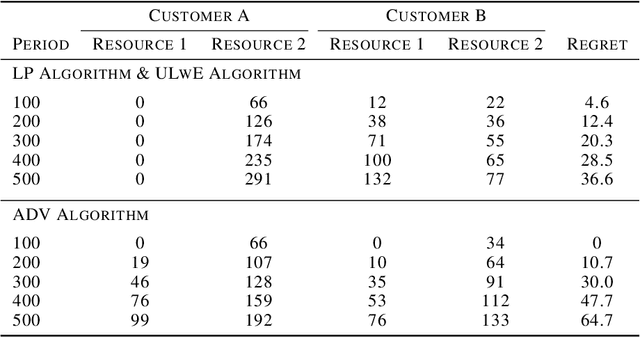
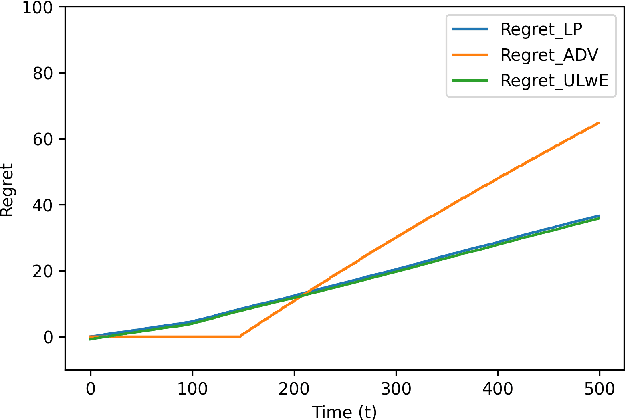
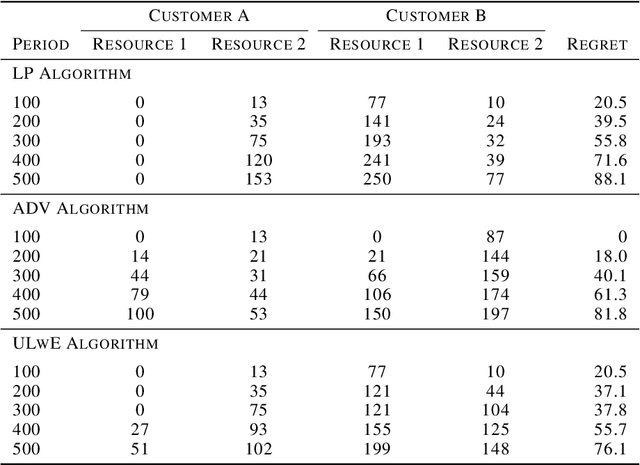
We propose a novel algorithm for online resource allocation with non-stationary customer arrivals and unknown click-through rates. We assume multiple types of customers arrive in a nonstationary stochastic fashion, with unknown arrival rates in each period, and that customers' click-through rates are unknown and can only be learned online. By leveraging results from the stochastic contextual bandit with knapsack and online matching with adversarial arrivals, we develop an online scheme to allocate the resources to nonstationary customers. We prove that under mild conditions, our scheme achieves a ``best-of-both-world'' result: the scheme has a sublinear regret when the customer arrivals are near-stationary, and enjoys an optimal competitive ratio under general (non-stationary) customer arrival distributions. Finally, we conduct extensive numerical experiments to show our approach generates near-optimal revenues for all different customer scenarios.