 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Modelers with Semantic Autocompletion of Processes
May 24, 2021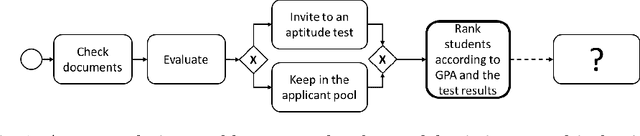

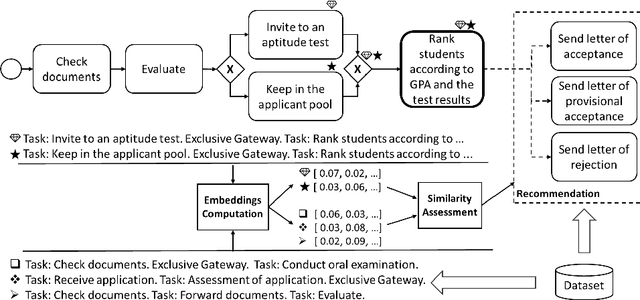

Business process modelers need to have expertise and knowledge of the domain that may not always be available to them. Therefore, they may benefit from tools that mine collections of existing processes and recommend element(s) to be added to a new process that they are constructing. In this paper, we present a method for process autocompletion at design time, that is based on the semantic similarity of sub-processes. By converting sub-processes to textual paragraphs and encoding them as numerical vectors, we can find semantically similar ones, and thereafter recommend the next element. To achieve this, we leverage a state-of-the-art technique for embedding natural language as vectors. We evaluate our approach on open source and proprietary datasets and show that our technique is accurate for processes in various domains.
Verifying Robustness of Gradient Boosted Models
Jun 26, 2019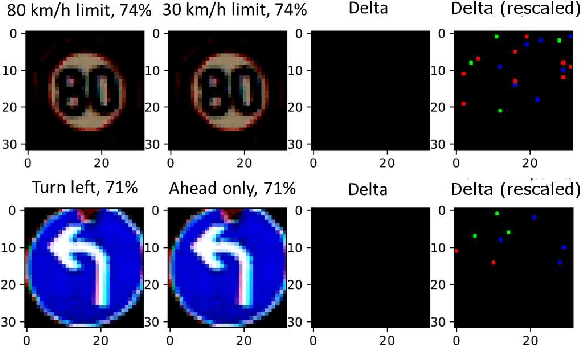
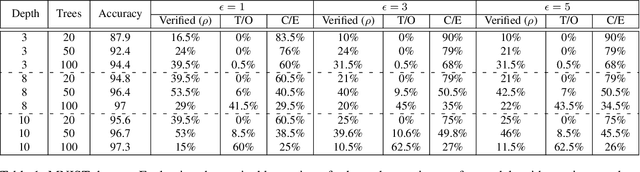
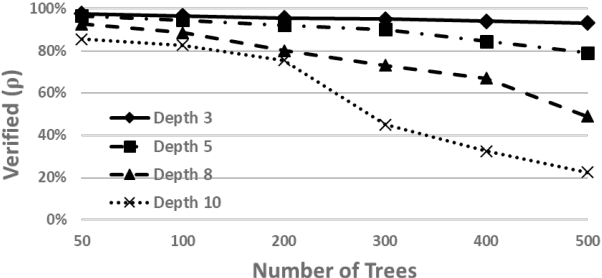
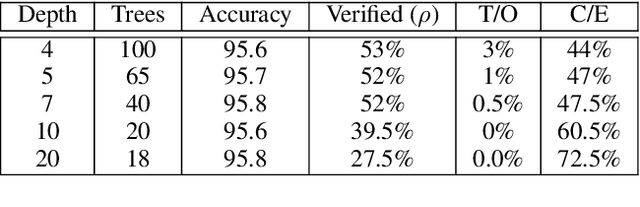
Gradient boosted models are a fundamental machine learning technique. Robustness to small perturbations of the input is an important quality measure for machine learning models, but the literature lacks a method to prove the robustness of gradient boosted models. This work introduces VeriGB, a tool for quantifying the robustness of gradient boosted models. VeriGB encodes the model and the robustness property as an SMT formula, which enables state of the art verification tools to prove the model's robustness. We extensively evaluate VeriGB on publicly available datasets and demonstrate a capability for verifying large models. Finally, we show that some model configurations tend to be inherently more robust than others.
Learning Software Constraints via Installation Attempts
Apr 24, 2018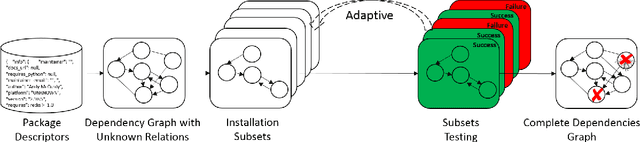

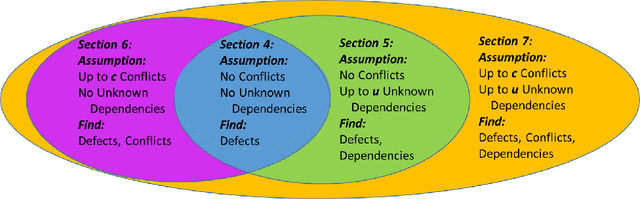
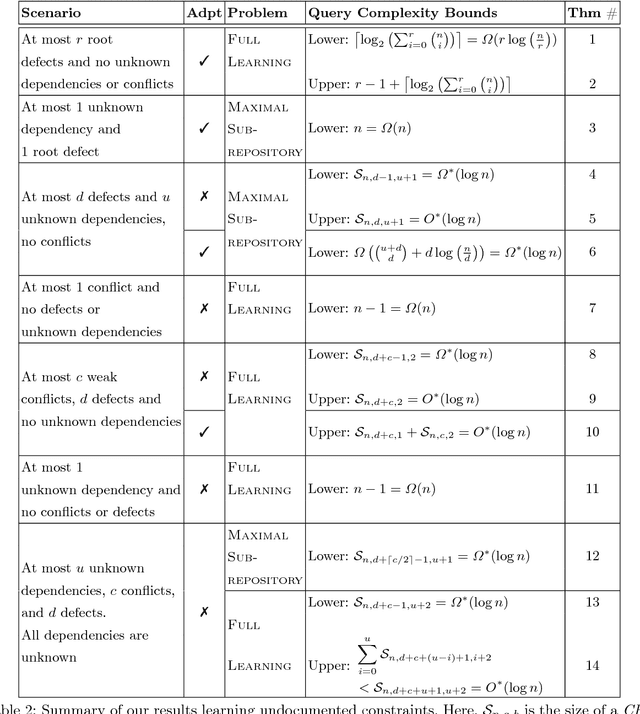
Modern software systems are expected to be secure and contain all the latest features, even when new versions of software are released multiple times an hour. Each system may include many interacting packages. The problem of installing multiple dependent packages has been extensively studied in the past, yielding some promising solutions that work well in practice. However, these assume that the developers declare all the dependencies and conflicts between the packages. Oftentimes, the entire repository structure may not be known upfront, for example when packages are developed by different vendors. In this paper we present algorithms for learning dependencies, conflicts and defective packages from installation attempts. Our algorithms use combinatorial data structures to generate queries that test installations and discover the entire dependency structure. A query that the algorithms make corresponds to trying to install a subset of packages and getting a Boolean feedback on whether all constraints were satisfied in this subset. Our goal is to minimize the query complexity of the algorithms. We prove lower and upper bounds on the number of queries that these algorithms require to make for different settings of the problem.