 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning and Decision-Making with Data: Optimal Formulations and Phase Transitions
Sep 14, 2021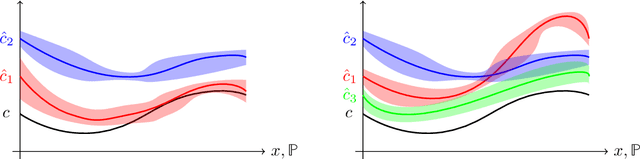
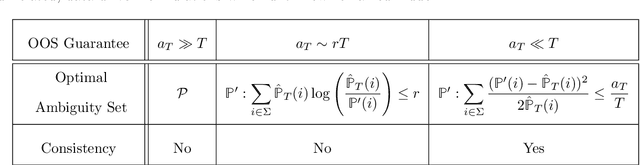
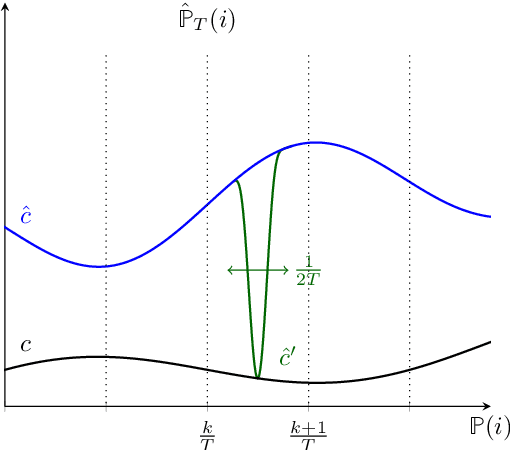
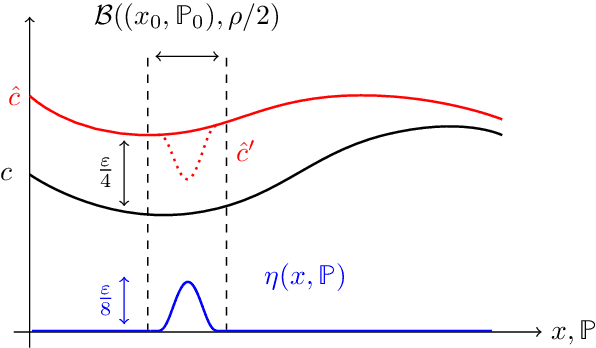
We study the problem of designing optimal learning and decision-making formulations when only historical data is available. Prior work typically commits to a particular class of data-driven formulation and subsequently tries to establish out-of-sample performance guarantees. We take here the opposite approach. We define first a sensible yard stick with which to measure the quality of any data-driven formulation and subsequently seek to find an optimal such formulation. Informally, any data-driven formulation can be seen to balance a measure of proximity of the estimated cost to the actual cost while guaranteeing a level of out-of-sample performance. Given an acceptable level of out-of-sample performance, we construct explicitly a data-driven formulation that is uniformly closer to the true cost than any other formulation enjoying the same out-of-sample performance. We show the existence of three distinct out-of-sample performance regimes (a superexponential regime, an exponential regime and a subexponential regime) between which the nature of the optimal data-driven formulation experiences a phase transition. The optimal data-driven formulations can be interpreted as a classically robust formulation in the superexponential regime, an entropic distributionally robust formulation in the exponential regime and finally a variance penalized formulation in the subexponential regime. This final observation unveils a surprising connection between these three, at first glance seemingly unrelated, data-driven formulations which until now remained hidden.
The Representation Power of Neural Networks: Breaking the Curse of Dimensionality
Jan 09, 2021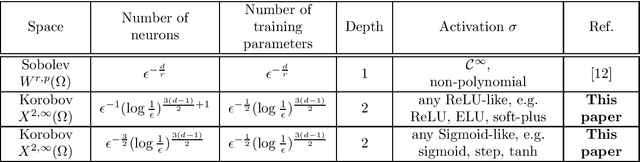
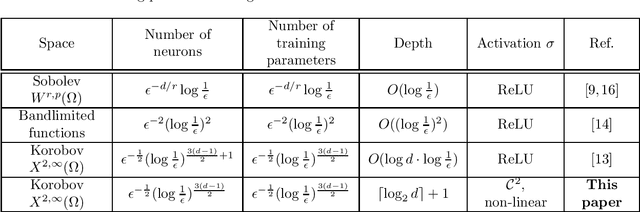

In this paper, we analyze the number of neurons and training parameters that a neural networks needs to approximate multivariate functions of bounded second mixed derivatives -- Korobov functions. We prove upper bounds on these quantities for shallow and deep neural networks, breaking the curse of dimensionality. Our bounds hold for general activation functions, including ReLU. We further prove that these bounds nearly match the minimal number of parameters any continuous function approximator needs to approximate Korobov functions, showing that neural networks are near-optimal function approximators.