Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Representation Power of Neural Networks: Breaking the Curse of Dimensionality
Paper and Code
Jan 09, 2021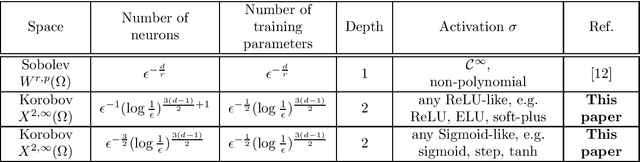
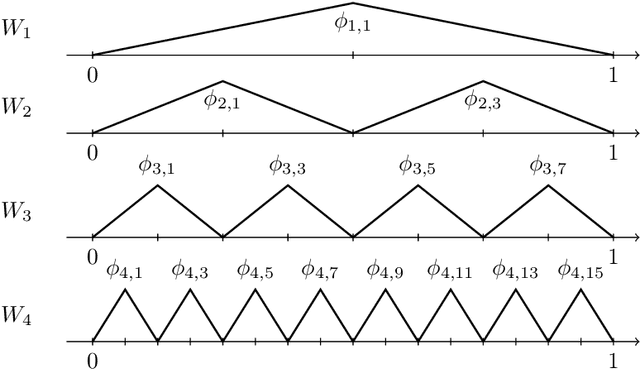
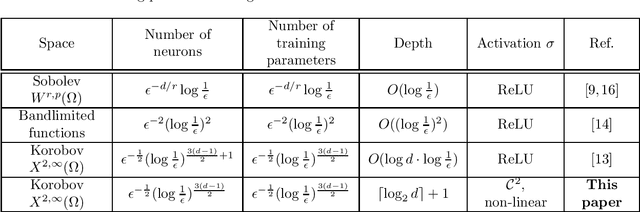

In this paper, we analyze the number of neurons and training parameters that a neural networks needs to approximate multivariate functions of bounded second mixed derivatives -- Korobov functions. We prove upper bounds on these quantities for shallow and deep neural networks, breaking the curse of dimensionality. Our bounds hold for general activation functions, including ReLU. We further prove that these bounds nearly match the minimal number of parameters any continuous function approximator needs to approximate Korobov functions, showing that neural networks are near-optimal function approximators.
* 24 pages, 7 figures
View paper on