 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
Boosting Lossless Speculative Decoding via Feature Sampling and Partial Alignment Distillation
Aug 28, 2024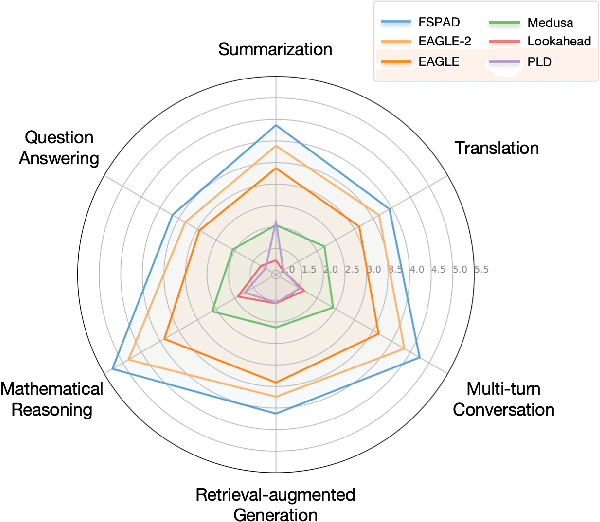
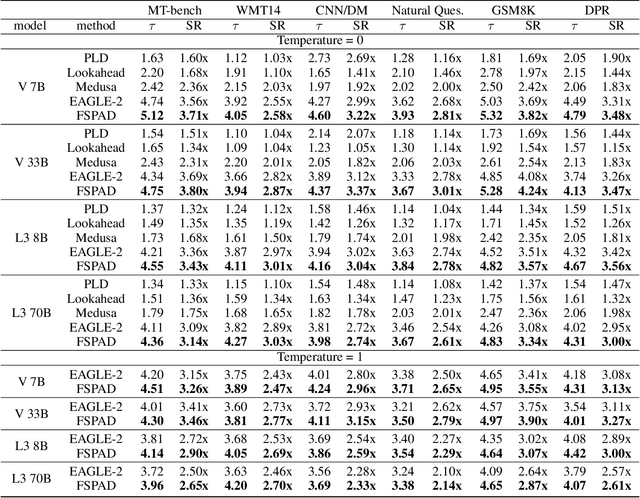
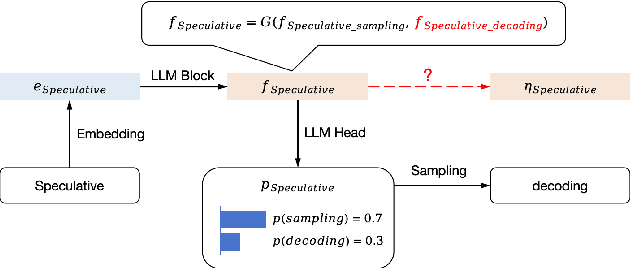
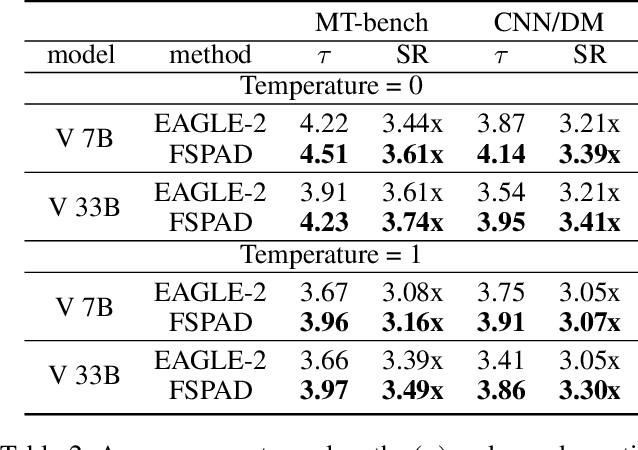
Lossless speculative decoding accelerates target large language model (LLM) inference by employing a lightweight draft model for generating tree-structured candidates, which are subsequently verified in parallel by the target LLM. Currently, effective approaches leverage feature-level rather than token-level autoregression within the draft model to facilitate more straightforward predictions and enhanced knowledge distillation. In this paper, we reassess these approaches and propose FSPAD (Feature Sampling and Partial Alignment Distillation for Lossless Speculative Decoding), which introduces two straightforward and effective components within the existing framework to boost lossless speculative decoding. Firstly, FSPAD utilizes token embeddings to sample features of the target LLM in high-dimensional space before feeding them into the draft model, due to the inherent uncertainty of the features preventing the draft model from obtaining the specific token output by the target LLM. Secondly, FSPAD introduces partial alignment distillation to weaken the draft model's connection between features and logits, aiming to reduce the conflict between feature alignment and logit confidence during training. Our experiments include both greedy and non-greedy decoding on the largest and smallest models from the Vicuna and LLaMA3-Instruct series, as well as tasks in multi-turn conversation, translation, summarization, question answering, mathematical reasoning, and retrieval-augmented generation. The results show that FSPAD outperforms the state-of-the-art method across all the aforementioned tasks and target LLMs.
Clover-2: Accurate Inference for Regressive Lightweight Speculative Decoding
Aug 01, 2024Large Language Models (LLMs) frequently suffer from inefficiencies, largely attributable to the discord between the requirements of auto-regressive decoding and the architecture of contemporary GPUs. Recently, regressive lightweight speculative decoding has garnered attention for its notable efficiency improvements in text generation tasks. This approach utilizes a lightweight regressive draft model, like a Recurrent Neural Network (RNN) or a single transformer decoder layer, leveraging sequential information to iteratively predict potential tokens. Specifically, RNN draft models are computationally economical but tend to deliver lower accuracy, while attention decoder layer models exhibit the opposite traits. This paper presents Clover-2, an advanced iteration of Clover, an RNN-based draft model designed to achieve comparable accuracy to that of attention decoder layer models while maintaining minimal computational overhead. Clover-2 enhances the model architecture and incorporates knowledge distillation to increase Clover's accuracy and improve overall efficiency. We conducted experiments using the open-source Vicuna 7B and LLaMA3-Instruct 8B models. The results demonstrate that Clover-2 surpasses existing methods across various model architectures, showcasing its efficacy and robustness.
CAVM: Conditional Autoregressive Vision Model for Contrast-Enhanced Brain Tumor MRI Synthesis
Jun 23, 2024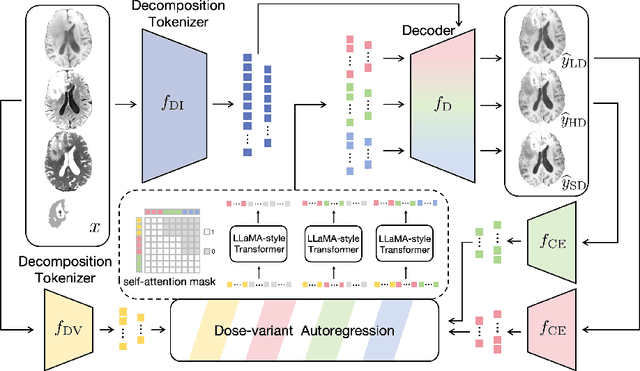
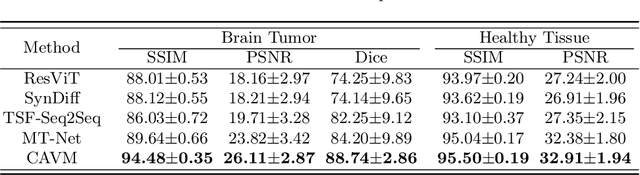
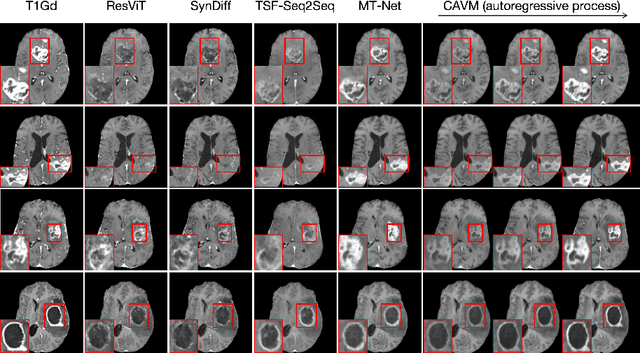

Contrast-enhanced magnetic resonance imaging (MRI) is pivotal in the pipeline of brain tumor segmentation and analysis. Gadolinium-based contrast agents, as the most commonly used contrast agents, are expensive and may have potential side effects, and it is desired to obtain contrast-enhanced brain tumor MRI scans without the actual use of contrast agents. Deep learning methods have been applied to synthesize virtual contrast-enhanced MRI scans from non-contrast images. However, as this synthesis problem is inherently ill-posed, these methods fall short in producing high-quality results. In this work, we propose Conditional Autoregressive Vision Model (CAVM) for improving the synthesis of contrast-enhanced brain tumor MRI. As the enhancement of image intensity grows with a higher dose of contrast agents, we assume that it is less challenging to synthesize a virtual image with a lower dose, where the difference between the contrast-enhanced and non-contrast images is smaller. Thus, CAVM gradually increases the contrast agent dosage and produces higher-dose images based on previous lower-dose ones until the final desired dose is achieved. Inspired by the resemblance between the gradual dose increase and the Chain-of-Thought approach in natural language processing, CAVM uses an autoregressive strategy with a decomposition tokenizer and a decoder. Specifically, the tokenizer is applied to obtain a more compact image representation for computational efficiency, and it decomposes the image into dose-variant and dose-invariant tokens. Then, a masked self-attention mechanism is developed for autoregression that gradually increases the dose of the virtual image based on the dose-variant tokens. Finally, the updated dose-variant tokens corresponding to the desired dose are decoded together with dose-invariant tokens to produce the final contrast-enhanced MRI.