 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining RL Agents for Multi-Objective Network Defense Tasks
May 28, 2025Open-ended learning (OEL) -- which emphasizes training agents that achieve broad capability over narrow competency -- is emerging as a paradigm to develop artificial intelligence (AI) agents to achieve robustness and generalization. However, despite promising results that demonstrate the benefits of OEL, applying OEL to develop autonomous agents for real-world cybersecurity applications remains a challenge. We propose a training approach, inspired by OEL, to develop autonomous network defenders. Our results demonstrate that like in other domains, OEL principles can translate into more robust and generalizable agents for cyber defense. To apply OEL to network defense, it is necessary to address several technical challenges. Most importantly, it is critical to provide a task representation approach over a broad universe of tasks that maintains a consistent interface over goals, rewards and action spaces. This way, the learning agent can train with varying network conditions, attacker behaviors, and defender goals while being able to build on previously gained knowledge. With our tools and results, we aim to fundamentally impact research that applies AI to solve cybersecurity problems. Specifically, as researchers develop gyms and benchmarks for cyber defense, it is paramount that they consider diverse tasks with consistent representations, such as those we propose in our work.
A Framework for Adversarial Analysis of Decision Support Systems Prior to Deployment
May 27, 2025This paper introduces a comprehensive framework designed to analyze and secure decision-support systems trained with Deep Reinforcement Learning (DRL), prior to deployment, by providing insights into learned behavior patterns and vulnerabilities discovered through simulation. The introduced framework aids in the development of precisely timed and targeted observation perturbations, enabling researchers to assess adversarial attack outcomes within a strategic decision-making context. We validate our framework, visualize agent behavior, and evaluate adversarial outcomes within the context of a custom-built strategic game, CyberStrike. Utilizing the proposed framework, we introduce a method for systematically discovering and ranking the impact of attacks on various observation indices and time-steps, and we conduct experiments to evaluate the transferability of adversarial attacks across agent architectures and DRL training algorithms. The findings underscore the critical need for robust adversarial defense mechanisms to protect decision-making policies in high-stakes environments.
Utilizing Explainability Techniques for Reinforcement Learning Model Assurance
Nov 27, 2023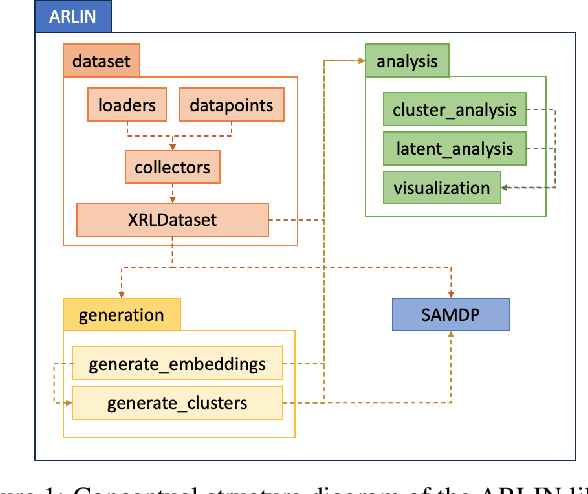
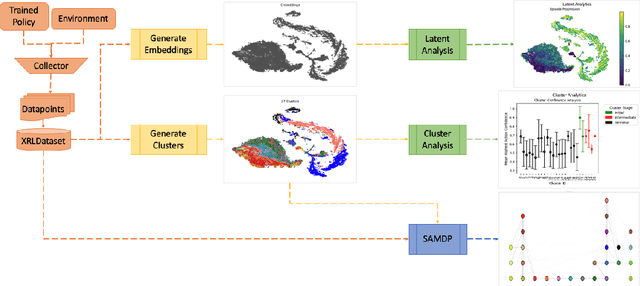
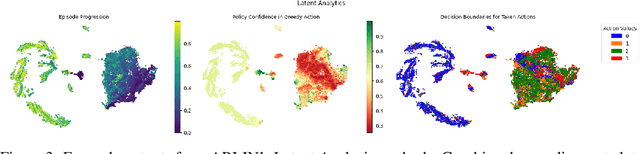
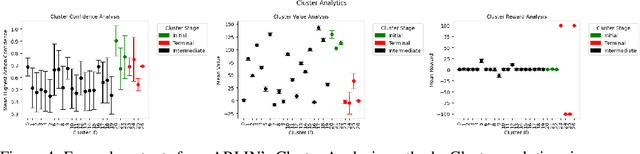
Explainable Reinforcement Learning (XRL) can provide transparency into the decision-making process of a Deep Reinforcement Learning (DRL) model and increase user trust and adoption in real-world use cases. By utilizing XRL techniques, researchers can identify potential vulnerabilities within a trained DRL model prior to deployment, therefore limiting the potential for mission failure or mistakes by the system. This paper introduces the ARLIN (Assured RL Model Interrogation) Toolkit, an open-source Python library that identifies potential vulnerabilities and critical points within trained DRL models through detailed, human-interpretable explainability outputs. To illustrate ARLIN's effectiveness, we provide explainability visualizations and vulnerability analysis for a publicly available DRL model. The open-source code repository is available for download at https://github.com/mitre/arlin.