 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing Explainability Techniques for Reinforcement Learning Model Assurance
Paper and Code
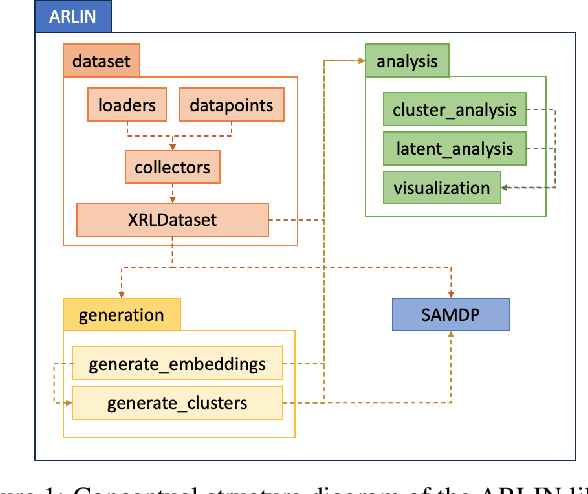
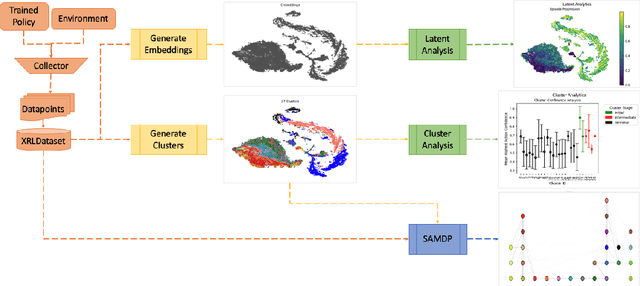
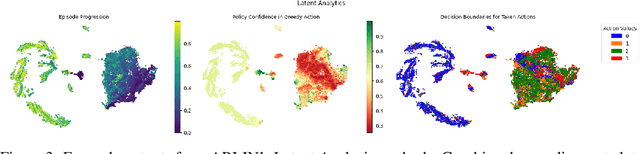
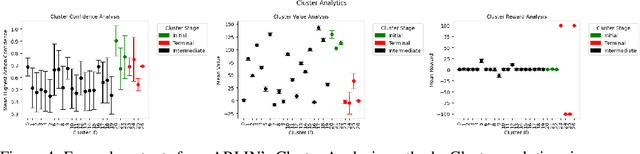
Explainable Reinforcement Learning (XRL) can provide transparency into the decision-making process of a Deep Reinforcement Learning (DRL) model and increase user trust and adoption in real-world use cases. By utilizing XRL techniques, researchers can identify potential vulnerabilities within a trained DRL model prior to deployment, therefore limiting the potential for mission failure or mistakes by the system. This paper introduces the ARLIN (Assured RL Model Interrogation) Toolkit, an open-source Python library that identifies potential vulnerabilities and critical points within trained DRL models through detailed, human-interpretable explainability outputs. To illustrate ARLIN's effectiveness, we provide explainability visualizations and vulnerability analysis for a publicly available DRL model. The open-source code repository is available for download at https://github.com/mitre/arlin.