 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefurnishing with X-Ray Vision: Joint Removal of Furniture from Panoramas and Mesh
Jun 06, 2025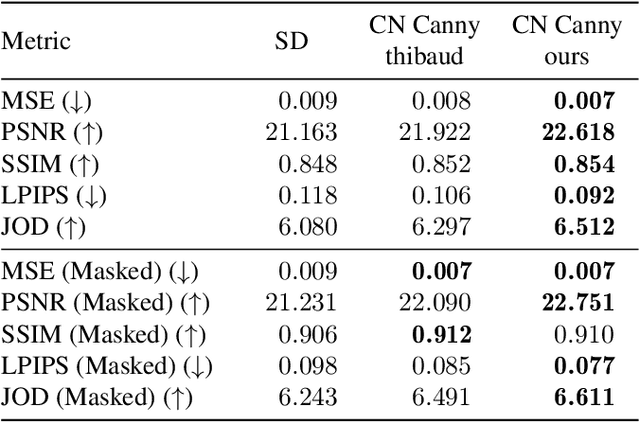
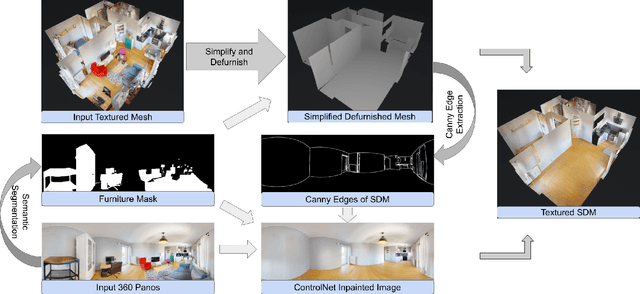
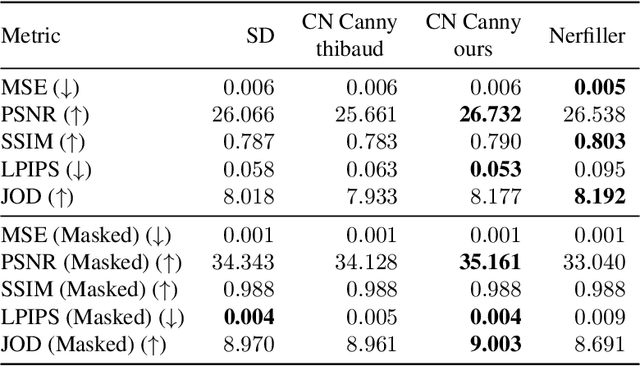

We present a pipeline for generating defurnished replicas of indoor spaces represented as textured meshes and corresponding multi-view panoramic images. To achieve this, we first segment and remove furniture from the mesh representation, extend planes, and fill holes, obtaining a simplified defurnished mesh (SDM). This SDM acts as an ``X-ray'' of the scene's underlying structure, guiding the defurnishing process. We extract Canny edges from depth and normal images rendered from the SDM. We then use these as a guide to remove the furniture from panorama images via ControlNet inpainting. This control signal ensures the availability of global geometric information that may be hidden from a particular panoramic view by the furniture being removed. The inpainted panoramas are used to texture the mesh. We show that our approach produces higher quality assets than methods that rely on neural radiance fields, which tend to produce blurry low-resolution images, or RGB-D inpainting, which is highly susceptible to hallucinations.
Much Easier Said Than Done: Falsifying the Causal Relevance of Linear Decoding Methods
Nov 08, 2022


Linear classifier probes are frequently utilized to better understand how neural networks function. Researchers have approached the problem of determining unit importance in neural networks by probing their learned, internal representations. Linear classifier probes identify highly selective units as the most important for network function. Whether or not a network actually relies on high selectivity units can be tested by removing them from the network using ablation. Surprisingly, when highly selective units are ablated they only produce small performance deficits, and even then only in some cases. In spite of the absence of ablation effects for selective neurons, linear decoding methods can be effectively used to interpret network function, leaving their effectiveness a mystery. To falsify the exclusive role of selectivity in network function and resolve this contradiction, we systematically ablate groups of units in subregions of activation space. Here, we find a weak relationship between neurons identified by probes and those identified by ablation. More specifically, we find that an interaction between selectivity and the average activity of the unit better predicts ablation performance deficits for groups of units in AlexNet, VGG16, MobileNetV2, and ResNet101. Linear decoders are likely somewhat effective because they overlap with those units that are causally important for network function. Interpretability methods could be improved by focusing on causally important units.
An Empirical Deep Dive into Deep Learning's Driving Dynamics
Jul 25, 2022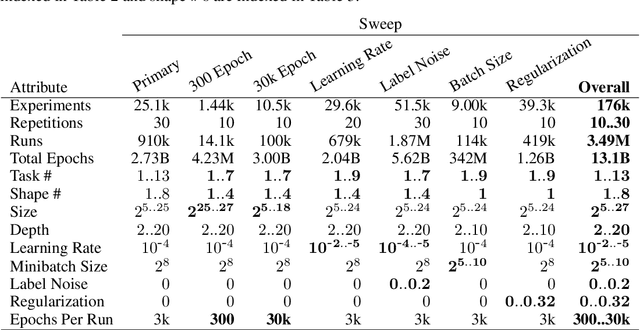
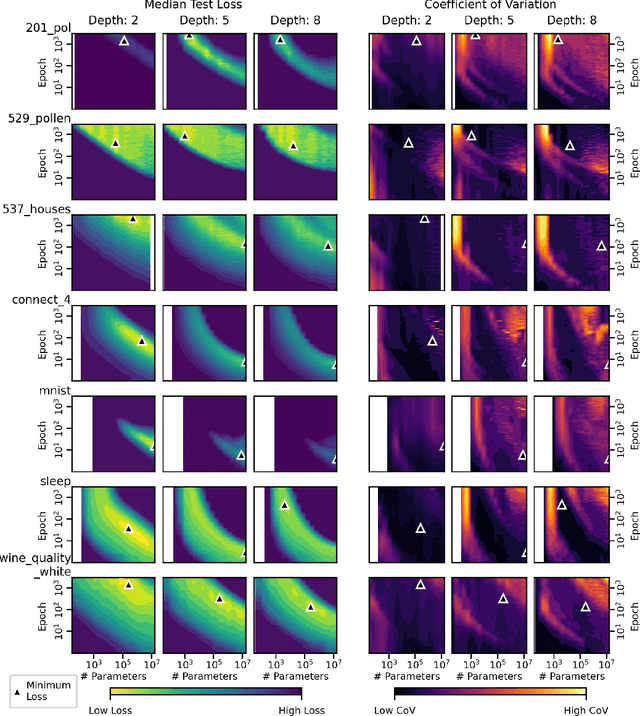
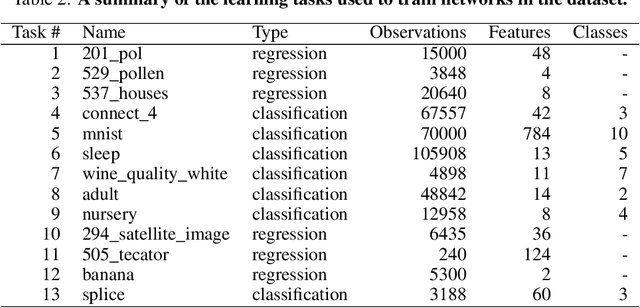
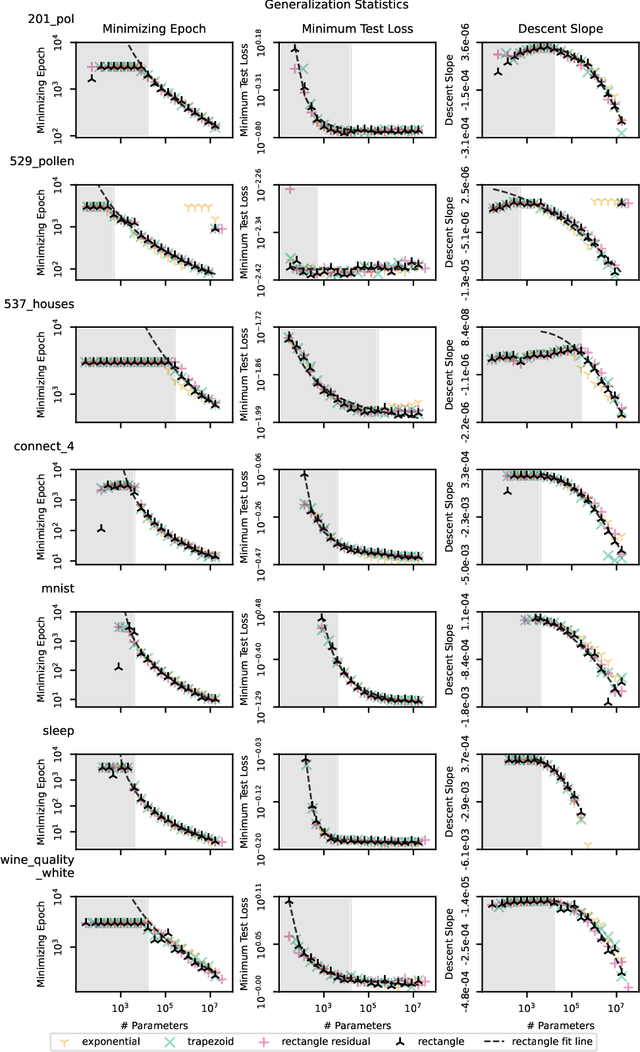
We present an empirical dataset surveying the deep learning phenomenon on fully-connected networks, encompassing the training and test performance of numerous network topologies, sweeping across multiple learning tasks, depths, numbers of free parameters, learning rates, batch sizes, and regularization penalties. The dataset probes 178 thousand hyperparameter settings with an average of 20 repetitions each, totaling 3.5 million training runs and 20 performance metrics for each of the 13.1 billion training epochs observed. Accumulating this 671 GB dataset utilized 5,448 CPU core-years, 17.8 GPU-years, and 111.2 node-years. Additionally, we provide a preliminary analysis revealing patterns which persist across learning tasks and topologies. We aim to inspire work empirically studying modern machine learning techniques as a catalyst for the theoretical discoveries needed to progress the field beyond energy-intensive and heuristic practices.