 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring the Energy Consumption and Efficiency of Deep Neural Networks: An Empirical Analysis and Design Recommendations
Mar 13, 2024



Addressing the so-called ``Red-AI'' trend of rising energy consumption by large-scale neural networks, this study investigates the actual energy consumption, as measured by node-level watt-meters, of training various fully connected neural network architectures. We introduce the BUTTER-E dataset, an augmentation to the BUTTER Empirical Deep Learning dataset, containing energy consumption and performance data from 63,527 individual experimental runs spanning 30,582 distinct configurations: 13 datasets, 20 sizes (number of trainable parameters), 8 network ``shapes'', and 14 depths on both CPU and GPU hardware collected using node-level watt-meters. This dataset reveals the complex relationship between dataset size, network structure, and energy use, and highlights the impact of cache effects. We propose a straightforward and effective energy model that accounts for network size, computing, and memory hierarchy. Our analysis also uncovers a surprising, hardware-mediated non-linear relationship between energy efficiency and network design, challenging the assumption that reducing the number of parameters or FLOPs is the best way to achieve greater energy efficiency. Highlighting the need for cache-considerate algorithm development, we suggest a combined approach to energy efficient network, algorithm, and hardware design. This work contributes to the fields of sustainable computing and Green AI, offering practical guidance for creating more energy-efficient neural networks and promoting sustainable AI.
An Empirical Deep Dive into Deep Learning's Driving Dynamics
Jul 25, 2022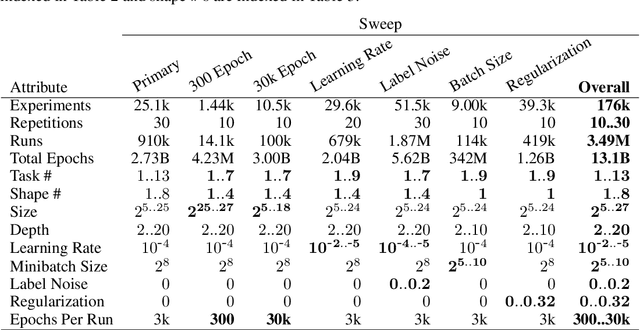
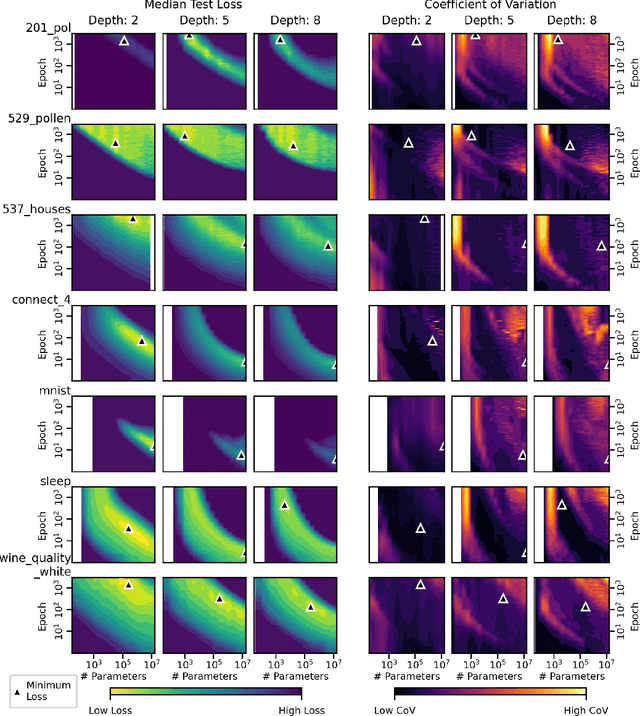
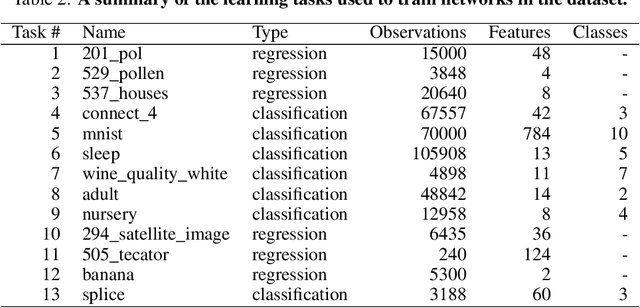
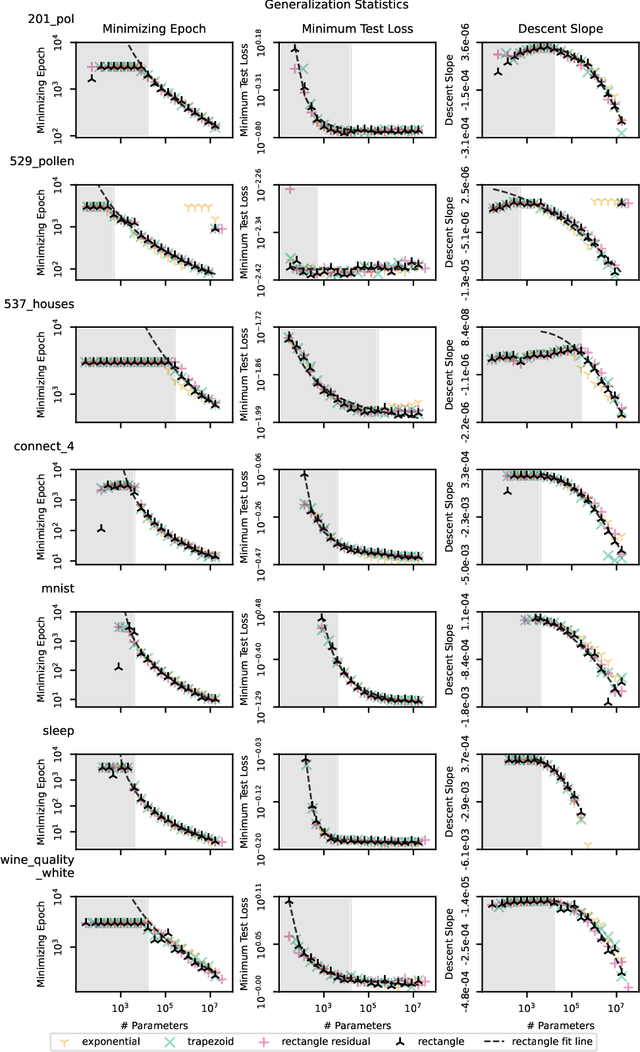
We present an empirical dataset surveying the deep learning phenomenon on fully-connected networks, encompassing the training and test performance of numerous network topologies, sweeping across multiple learning tasks, depths, numbers of free parameters, learning rates, batch sizes, and regularization penalties. The dataset probes 178 thousand hyperparameter settings with an average of 20 repetitions each, totaling 3.5 million training runs and 20 performance metrics for each of the 13.1 billion training epochs observed. Accumulating this 671 GB dataset utilized 5,448 CPU core-years, 17.8 GPU-years, and 111.2 node-years. Additionally, we provide a preliminary analysis revealing patterns which persist across learning tasks and topologies. We aim to inspire work empirically studying modern machine learning techniques as a catalyst for the theoretical discoveries needed to progress the field beyond energy-intensive and heuristic practices.