 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplanation-by-Example Based on Item Response Theory
Oct 04, 2022
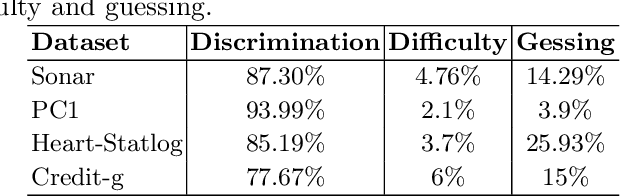
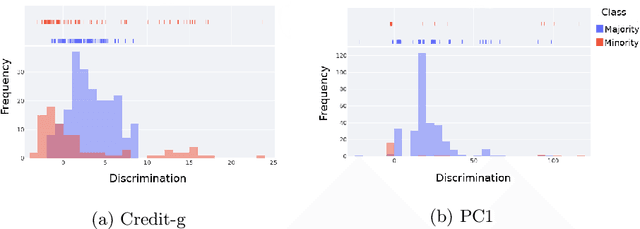
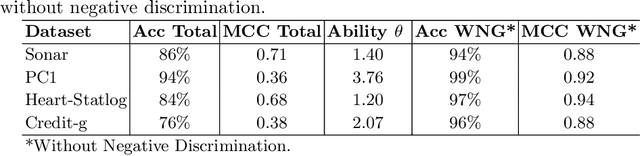
Intelligent systems that use Machine Learning classification algorithms are increasingly common in everyday society. However, many systems use black-box models that do not have characteristics that allow for self-explanation of their predictions. This situation leads researchers in the field and society to the following question: How can I trust the prediction of a model I cannot understand? In this sense, XAI emerges as a field of AI that aims to create techniques capable of explaining the decisions of the classifier to the end-user. As a result, several techniques have emerged, such as Explanation-by-Example, which has a few initiatives consolidated by the community currently working with XAI. This research explores the Item Response Theory (IRT) as a tool to explaining the models and measuring the level of reliability of the Explanation-by-Example approach. To this end, four datasets with different levels of complexity were used, and the Random Forest model was used as a hypothesis test. From the test set, 83.8% of the errors are from instances in which the IRT points out the model as unreliable.
Data vs classifiers, who wins?
Jul 21, 2021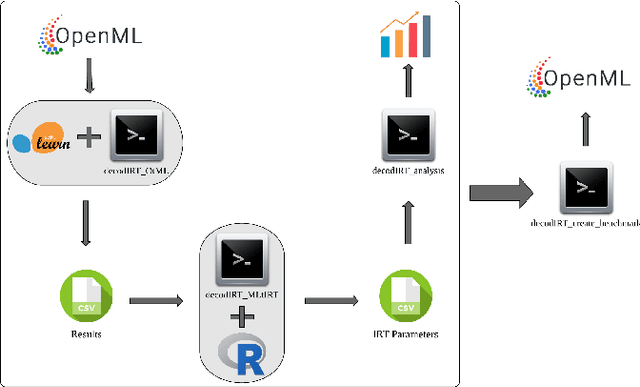
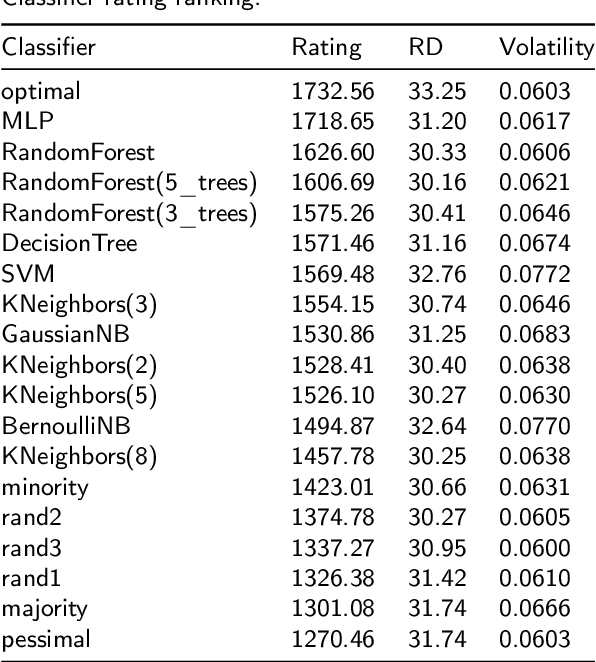
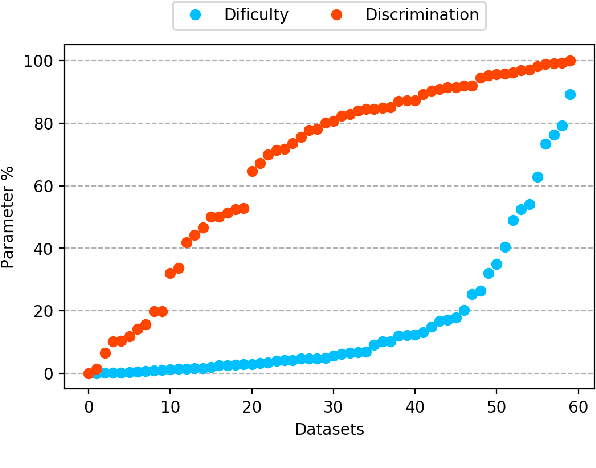
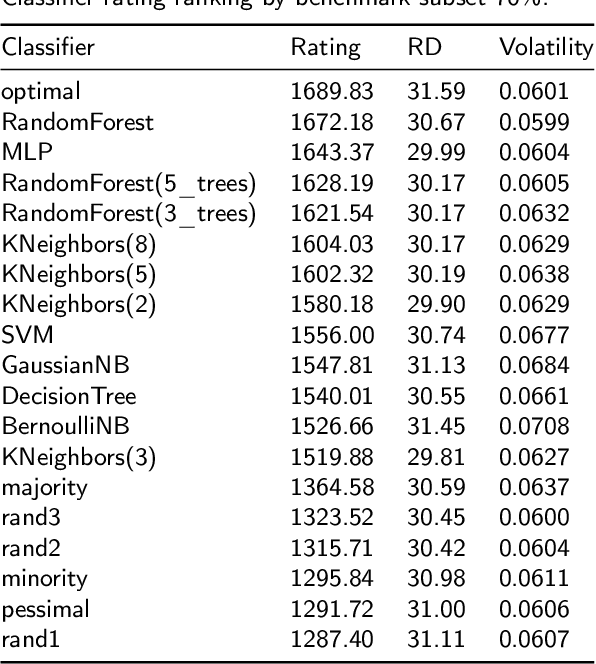
The classification experiments covered by machine learning (ML) are composed by two important parts: the data and the algorithm. As they are a fundamental part of the problem, both must be considered when evaluating a model's performance against a benchmark. The best classifiers need robust benchmarks to be properly evaluated. For this, gold standard benchmarks such as OpenML-CC18 are used. However, data complexity is commonly not considered along with the model during a performance evaluation. Recent studies employ Item Response Theory (IRT) as a new approach to evaluating datasets and algorithms, capable of evaluating both simultaneously. This work presents a new evaluation methodology based on IRT and Glicko-2, jointly with the decodIRT tool developed to guide the estimation of IRT in ML. It explores the IRT as a tool to evaluate the OpenML-CC18 benchmark for its algorithmic evaluation capability and checks if there is a subset of datasets more efficient than the original benchmark. Several classifiers, from classics to ensemble, are also evaluated using the IRT models. The Glicko-2 rating system was applied together with IRT to summarize the innate ability and classifiers performance. It was noted that not all OpenML-CC18 datasets are really useful for evaluating algorithms, where only 10% were rated as being really difficult. Furthermore, it was verified the existence of a more efficient subset containing only 50% of the original size. While Randon Forest was singled out as the algorithm with the best innate ability.
Decoding machine learning benchmarks
Aug 19, 2020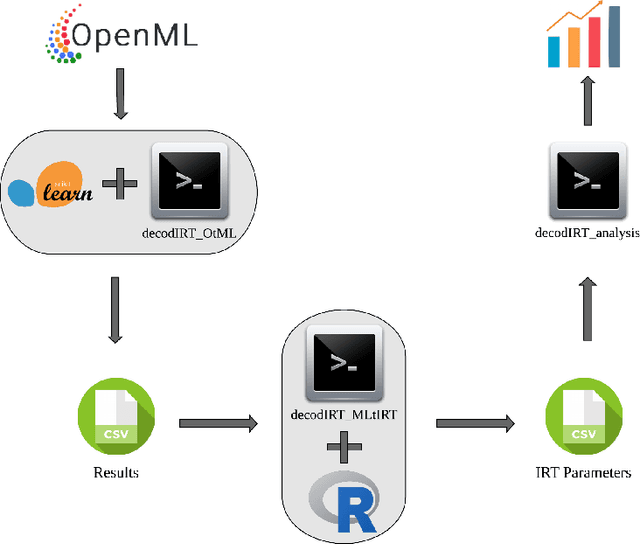
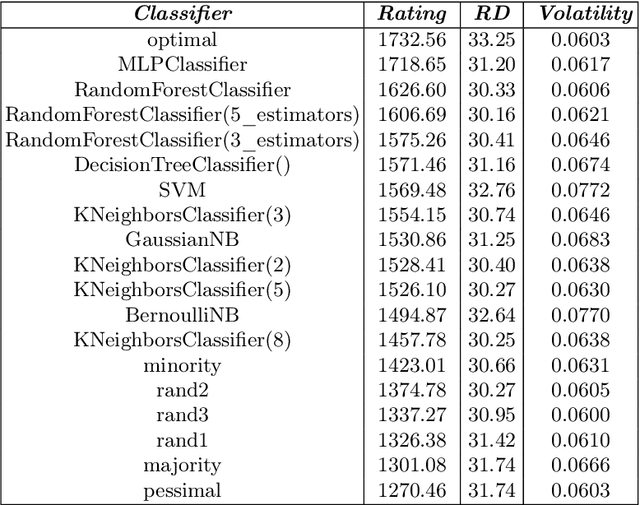
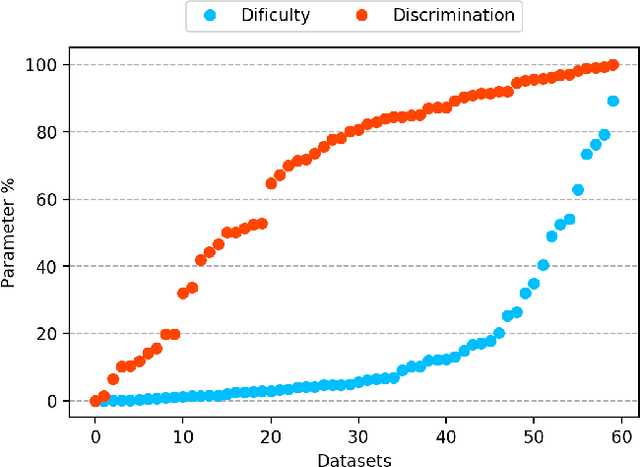
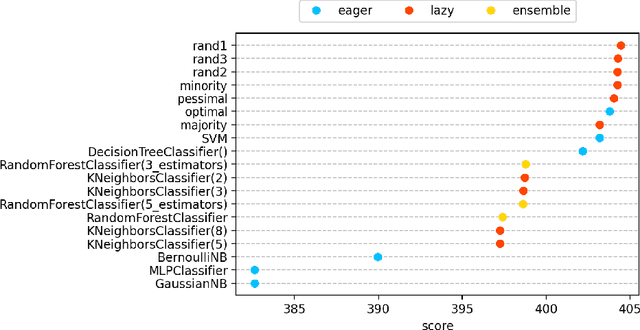
Despite the availability of benchmark machine learning (ML) repositories (e.g., UCI, OpenML), there is no standard evaluation strategy yet capable of pointing out which is the best set of datasets to serve as gold standard to test different ML algorithms. In recent studies, Item Response Theory (IRT) has emerged as a new approach to elucidate what should be a good ML benchmark. This work applied IRT to explore the well-known OpenML-CC18 benchmark to identify how suitable it is on the evaluation of classifiers. Several classifiers ranging from classical to ensembles ones were evaluated using IRT models, which could simultaneously estimate dataset difficulty and classifiers' ability. The Glicko-2 rating system was applied on the top of IRT to summarize the innate ability and aptitude of classifiers. It was observed that not all datasets from OpenML-CC18 are really useful to evaluate classifiers. Most datasets evaluated in this work (84%) contain easy instances in general (e.g., around 10% of difficult instances only). Also, 80% of the instances in half of this benchmark are very discriminating ones, which can be of great use for pairwise algorithm comparison, but not useful to push classifiers abilities. This paper presents this new evaluation methodology based on IRT as well as the tool decodIRT, developed to guide IRT estimation over ML benchmarks.