 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding machine learning benchmarks
Paper and Code
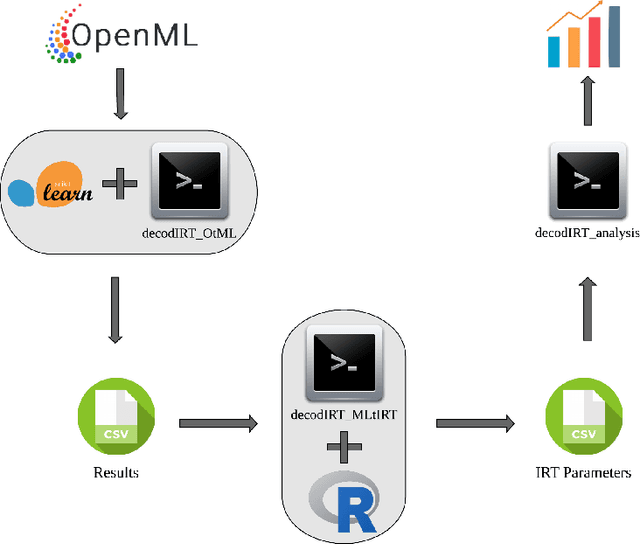
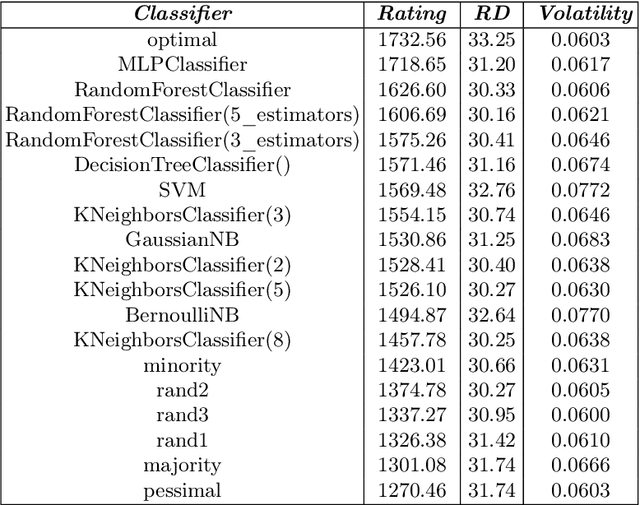
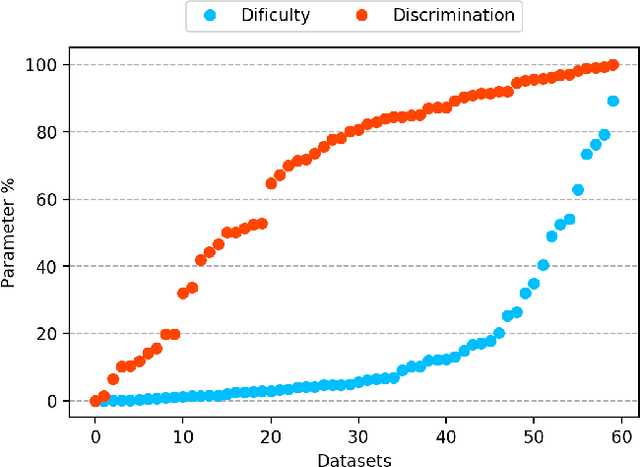
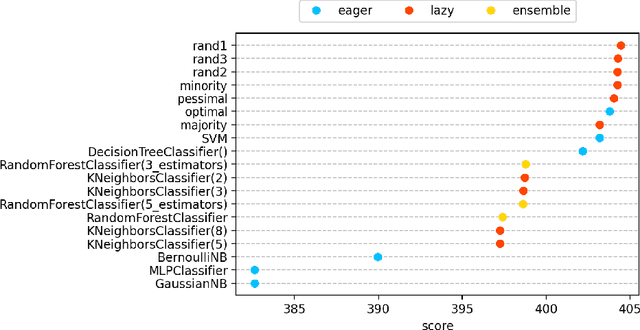
Despite the availability of benchmark machine learning (ML) repositories (e.g., UCI, OpenML), there is no standard evaluation strategy yet capable of pointing out which is the best set of datasets to serve as gold standard to test different ML algorithms. In recent studies, Item Response Theory (IRT) has emerged as a new approach to elucidate what should be a good ML benchmark. This work applied IRT to explore the well-known OpenML-CC18 benchmark to identify how suitable it is on the evaluation of classifiers. Several classifiers ranging from classical to ensembles ones were evaluated using IRT models, which could simultaneously estimate dataset difficulty and classifiers' ability. The Glicko-2 rating system was applied on the top of IRT to summarize the innate ability and aptitude of classifiers. It was observed that not all datasets from OpenML-CC18 are really useful to evaluate classifiers. Most datasets evaluated in this work (84%) contain easy instances in general (e.g., around 10% of difficult instances only). Also, 80% of the instances in half of this benchmark are very discriminating ones, which can be of great use for pairwise algorithm comparison, but not useful to push classifiers abilities. This paper presents this new evaluation methodology based on IRT as well as the tool decodIRT, developed to guide IRT estimation over ML benchmarks.