 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData vs classifiers, who wins?
Paper and Code
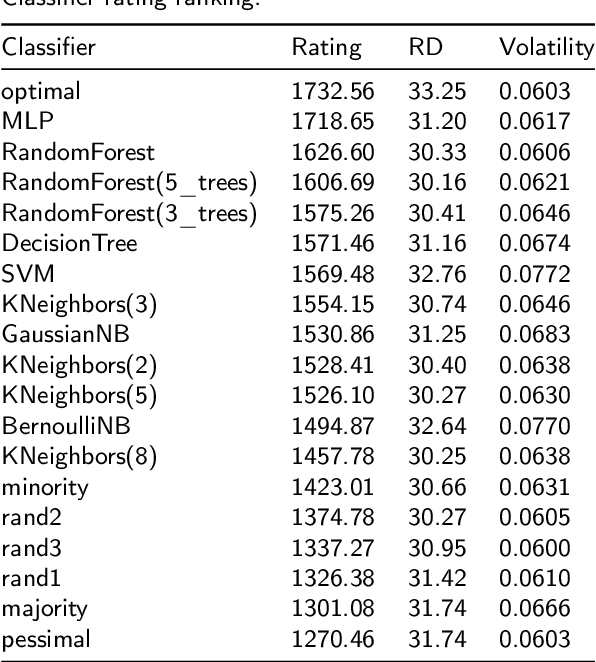
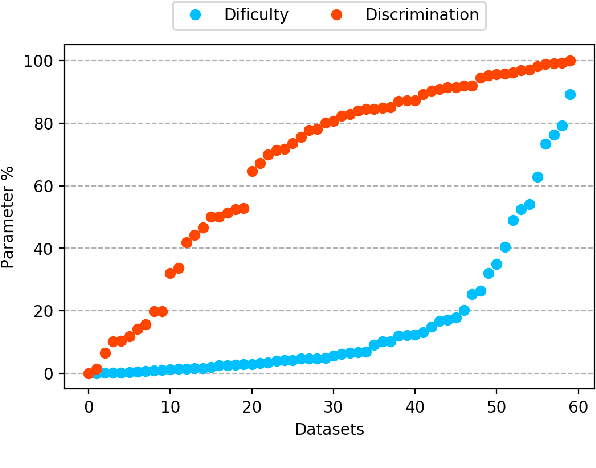
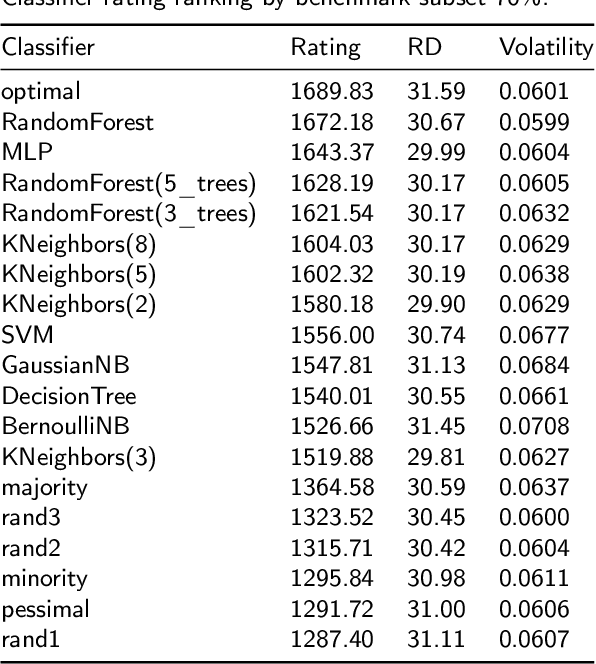
The classification experiments covered by machine learning (ML) are composed by two important parts: the data and the algorithm. As they are a fundamental part of the problem, both must be considered when evaluating a model's performance against a benchmark. The best classifiers need robust benchmarks to be properly evaluated. For this, gold standard benchmarks such as OpenML-CC18 are used. However, data complexity is commonly not considered along with the model during a performance evaluation. Recent studies employ Item Response Theory (IRT) as a new approach to evaluating datasets and algorithms, capable of evaluating both simultaneously. This work presents a new evaluation methodology based on IRT and Glicko-2, jointly with the decodIRT tool developed to guide the estimation of IRT in ML. It explores the IRT as a tool to evaluate the OpenML-CC18 benchmark for its algorithmic evaluation capability and checks if there is a subset of datasets more efficient than the original benchmark. Several classifiers, from classics to ensemble, are also evaluated using the IRT models. The Glicko-2 rating system was applied together with IRT to summarize the innate ability and classifiers performance. It was noted that not all OpenML-CC18 datasets are really useful for evaluating algorithms, where only 10% were rated as being really difficult. Furthermore, it was verified the existence of a more efficient subset containing only 50% of the original size. While Randon Forest was singled out as the algorithm with the best innate ability.