 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Anomaly Detection by Residual Adaptation
Oct 05, 2020


Deep anomaly detection is a difficult task since, in high dimensions, it is hard to completely characterize a notion of "differentness" when given only examples of normality. In this paper we propose a novel approach to deep anomaly detection based on augmenting large pretrained networks with residual corrections that adjusts them to the task of anomaly detection. Our method gives rise to a highly parameter-efficient learning mechanism, enhances disentanglement of representations in the pretrained model, and outperforms all existing anomaly detection methods including other baselines utilizing pretrained networks. On the CIFAR-10 one-versus-rest benchmark, for example, our technique raises the state of the art from 96.1 to 99.0 mean AUC.
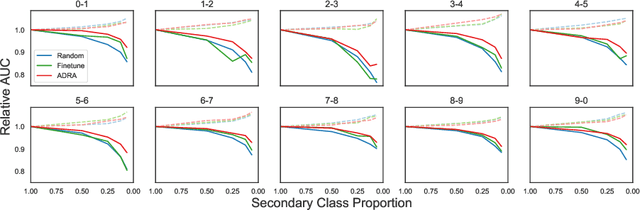
Latent Domain Learning with Dynamic Residual Adapters
Jun 01, 2020


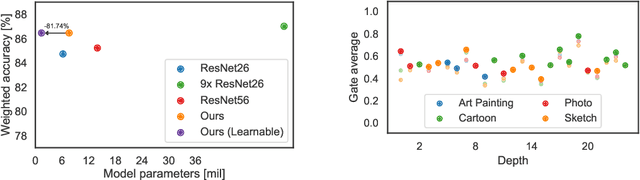
A practical shortcoming of deep neural networks is their specialization to a single task and domain. While recent techniques in domain adaptation and multi-domain learning enable the learning of more domain-agnostic features, their success relies on the presence of domain labels, typically requiring manual annotation and careful curation of datasets. Here we focus on a less explored, but more realistic case: learning from data from multiple domains, without access to domain annotations. In this scenario, standard model training leads to the overfitting of large domains, while disregarding smaller ones. We address this limitation via dynamic residual adapters, an adaptive gating mechanism that helps account for latent domains, coupled with an augmentation strategy inspired by recent style transfer techniques. Our proposed approach is examined on image classification tasks containing multiple latent domains, and we showcase its ability to obtain robust performance across these. Dynamic residual adapters significantly outperform off-the-shelf networks with much larger capacity, and can be incorporated seamlessly with existing architectures in an end-to-end manner.
Mode Normalization
Oct 12, 2018

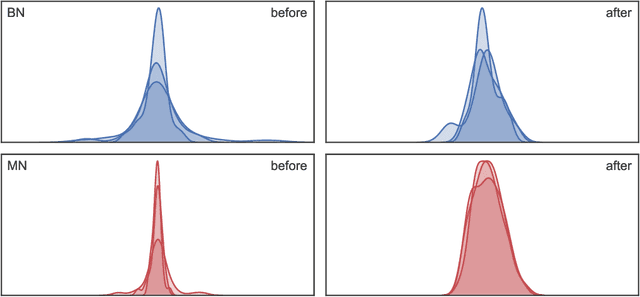

Normalization methods are a central building block in the deep learning toolbox. They accelerate and stabilize training, while decreasing the dependence on manually tuned learning rate schedules. When learning from multi-modal distributions, the effectiveness of batch normalization (BN), arguably the most prominent normalization method, is reduced. As a remedy, we propose a more flexible approach: by extending the normalization to more than a single mean and variance, we detect modes of data on-the-fly, jointly normalizing samples that share common features. We demonstrate that our method outperforms BN and other widely used normalization techniques in several experiments, including single and multi-task datasets.