 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolecular dynamics without molecules: searching the conformational space of proteins with generative neural networks
Jun 09, 2022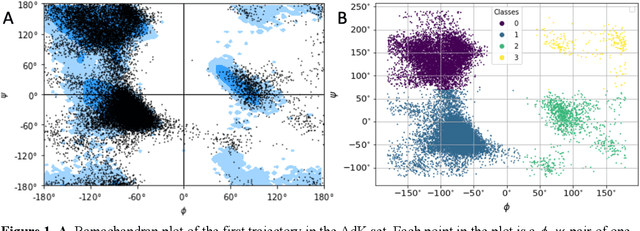
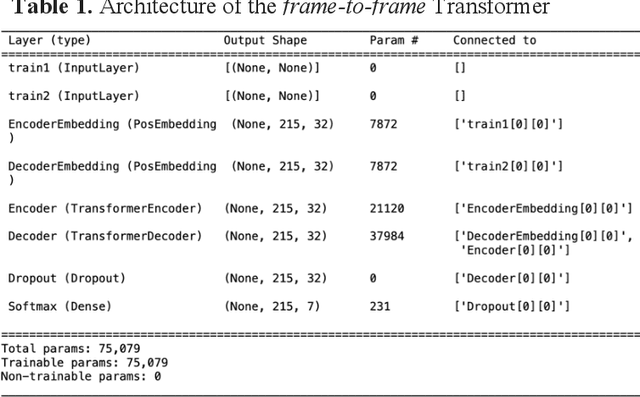

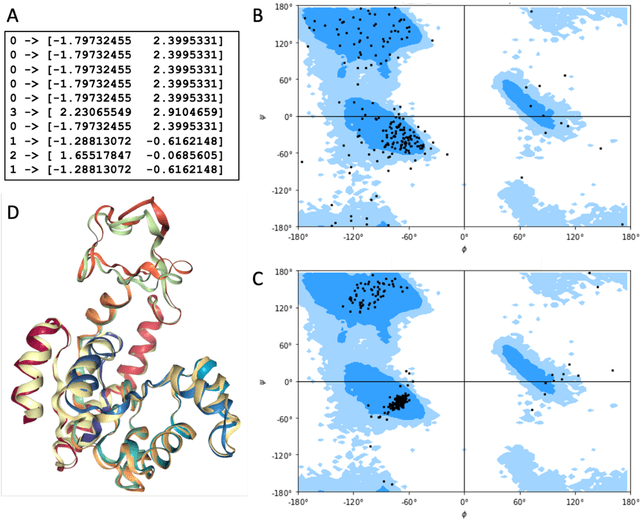
All-atom and coarse-grained molecular dynamics are two widely used computational tools to study the conformational states of proteins. Yet, these two simulation methods suffer from the fact that without access to supercomputing resources, the time and length scales at which these states become detectable are difficult to achieve. One alternative to such methods is based on encoding the atomistic trajectory of molecular dynamics as a shorthand version devoid of physical particles, and then learning to propagate the encoded trajectory through the use of artificial intelligence. Here we show that a simple textual representation of the frames of molecular dynamics trajectories as vectors of Ramachandran basin classes retains most of the structural information of the full atomistic representation of a protein in each frame, and can be used to generate equivalent atom-less trajectories suitable to train different types of generative neural networks. In turn, the trained generative models can be used to extend indefinitely the atom-less dynamics or to sample the conformational space of proteins from their representation in the models latent space. We define intuitively this methodology as molecular dynamics without molecules, and show that it enables to cover physically relevant states of proteins that are difficult to access with traditional molecular dynamics.
Learning Pruned Structure and Weights Simultaneously from Scratch: an Attention based Approach
Nov 01, 2021
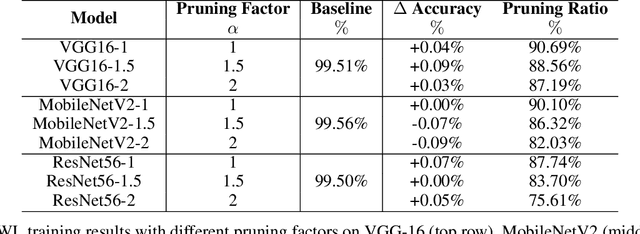
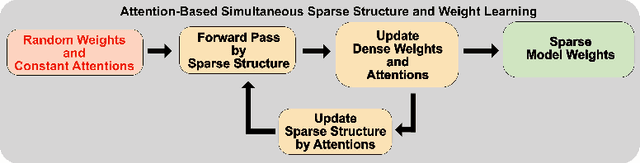

As a deep learning model typically contains millions of trainable weights, there has been a growing demand for a more efficient network structure with reduced storage space and improved run-time efficiency. Pruning is one of the most popular network compression techniques. In this paper, we propose a novel unstructured pruning pipeline, Attention-based Simultaneous sparse structure and Weight Learning (ASWL). Unlike traditional channel-wise or weight-wise attention mechanism, ASWL proposed an efficient algorithm to calculate the pruning ratio through layer-wise attention for each layer, and both weights for the dense network and the sparse network are tracked so that the pruned structure is simultaneously learned from randomly initialized weights. Our experiments on MNIST, Cifar10, and ImageNet show that ASWL achieves superior pruning results in terms of accuracy, pruning ratio and operating efficiency when compared with state-of-the-art network pruning methods.