 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWomen Wearing Lipstick: Measuring the Bias Between an Object and Its Related Gender
Oct 29, 2023



In this paper, we investigate the impact of objects on gender bias in image captioning systems. Our results show that only gender-specific objects have a strong gender bias (e.g., women-lipstick). In addition, we propose a visual semantic-based gender score that measures the degree of bias and can be used as a plug-in for any image captioning system. Our experiments demonstrate the utility of the gender score, since we observe that our score can measure the bias relation between a caption and its related gender; therefore, our score can be used as an additional metric to the existing Object Gender Co-Occ approach. Code and data are publicly available at \url{https://github.com/ahmedssabir/GenderScore}.
Visual Semantic Relatedness Dataset for Image Captioning
Jan 20, 2023



Modern image captioning system relies heavily on extracting knowledge from images to capture the concept of a static story. In this paper, we propose a textual visual context dataset for captioning, in which the publicly available dataset COCO Captions (Lin et al., 2014) has been extended with information about the scene (such as objects in the image). Since this information has a textual form, it can be used to leverage any NLP task, such as text similarity or semantic relation methods, into captioning systems, either as an end-to-end training strategy or a post-processing based approach.
Belief Revision based Caption Re-ranker with Visual Semantic Information
Sep 16, 2022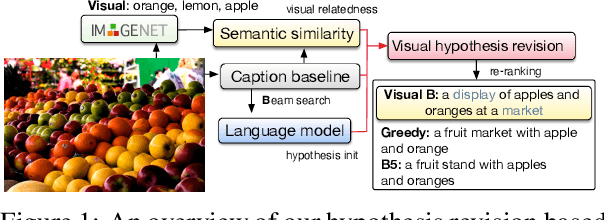
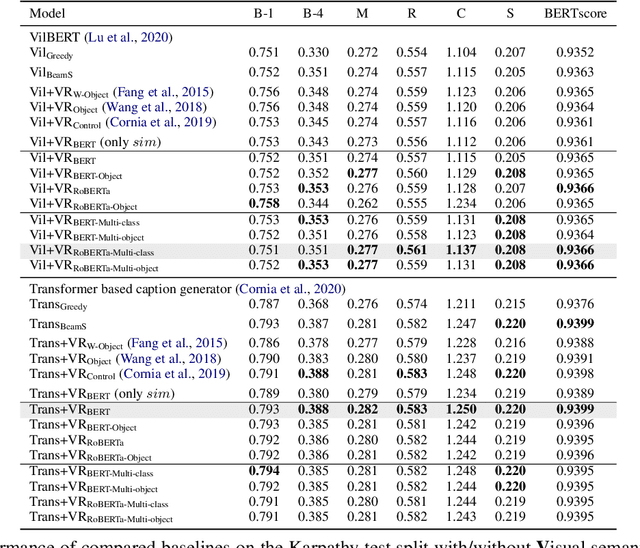
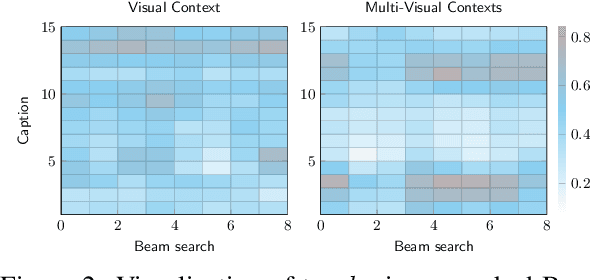
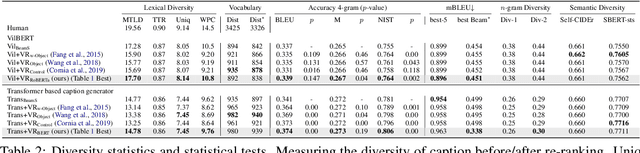
In this work, we focus on improving the captions generated by image-caption generation systems. We propose a novel re-ranking approach that leverages visual-semantic measures to identify the ideal caption that maximally captures the visual information in the image. Our re-ranker utilizes the Belief Revision framework (Blok et al., 2003) to calibrate the original likelihood of the top-n captions by explicitly exploiting the semantic relatedness between the depicted caption and the visual context. Our experiments demonstrate the utility of our approach, where we observe that our re-ranker can enhance the performance of a typical image-captioning system without the necessity of any additional training or fine-tuning.
Zipf's laws of meaning in Catalan
Jun 30, 2021
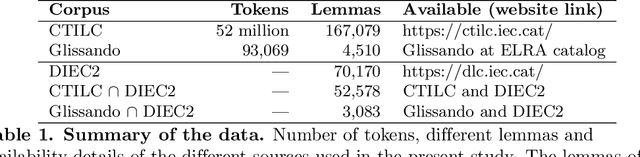
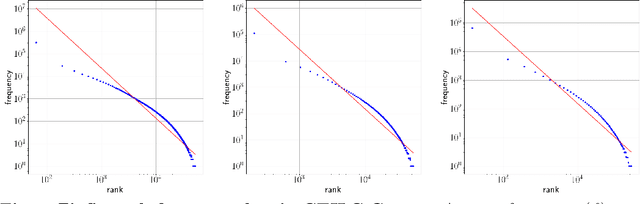
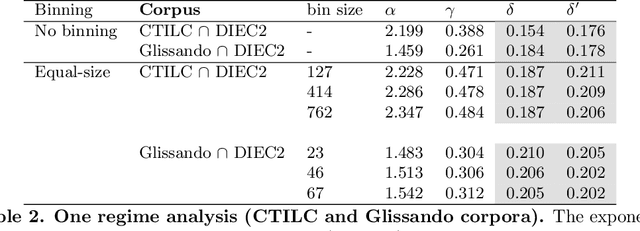
In his pioneering research, G. K. Zipf formulated a couple of statistical laws on the relationship between the frequency of a word with its number of meanings: the law of meaning distribution, relating the frequency of a word and its frequency rank, and the meaning-frequency law, relating the frequency of a word with its number of meanings. Although these laws were formulated more than half a century ago, they have been only investigated in a few languages. Here we present the first study of these laws in Catalan. We verify these laws in Catalan via the relationship among their exponents and that of the rank-frequency law. We present a new protocol for the analysis of these Zipfian laws that can be extended to other languages. We report the first evidence of two marked regimes for these laws in written language and speech, paralleling the two regimes in Zipf's rank-frequency law in large multi-author corpora discovered in early 2000s. Finally, the implications of these two regimes will be discussed.
Textual Visual Semantic Dataset for Text Spotting
Apr 21, 2020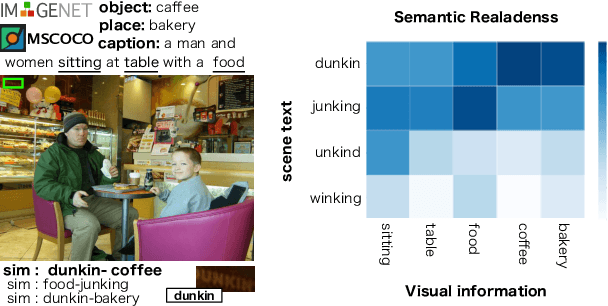

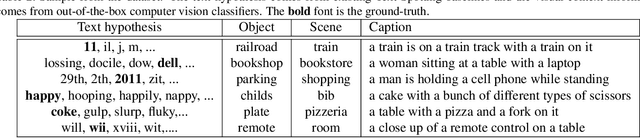

Text Spotting in the wild consists of detecting and recognizing text appearing in images (e.g. signboards, traffic signals or brands in clothing or objects). This is a challenging problem due to the complexity of the context where texts appear (uneven backgrounds, shading, occlusions, perspective distortions, etc.). Only a few approaches try to exploit the relation between text and its surrounding environment to better recognize text in the scene. In this paper, we propose a visual context dataset for Text Spotting in the wild, where the publicly available dataset COCO-text [Veit et al. 2016] has been extended with information about the scene (such as objects and places appearing in the image) to enable researchers to include semantic relations between texts and scene in their Text Spotting systems, and to offer a common framework for such approaches. For each text in an image, we extract three kinds of context information: objects in the scene, image location label and a textual image description (caption). We use state-of-the-art out-of-the-box available tools to extract this additional information. Since this information has textual form, it can be used to leverage text similarity or semantic relation methods into Text Spotting systems, either as a post-processing or in an end-to-end training strategy. Our data is publicly available at https://git.io/JeZTb.
Semantic Relatedness Based Re-ranker for Text Spotting
Sep 19, 2019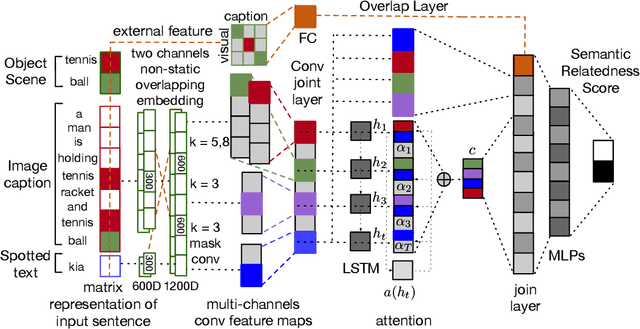
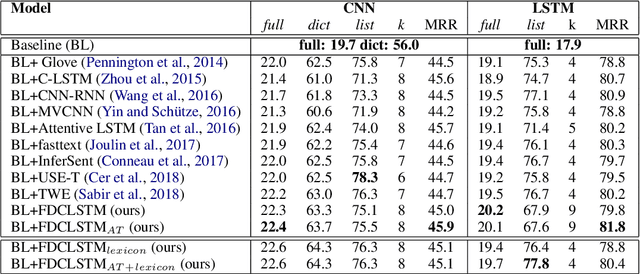
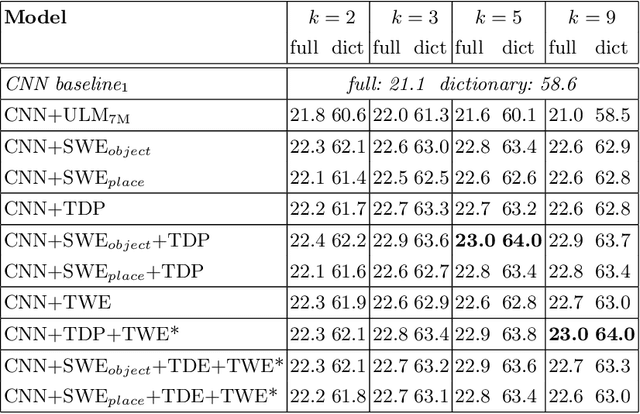
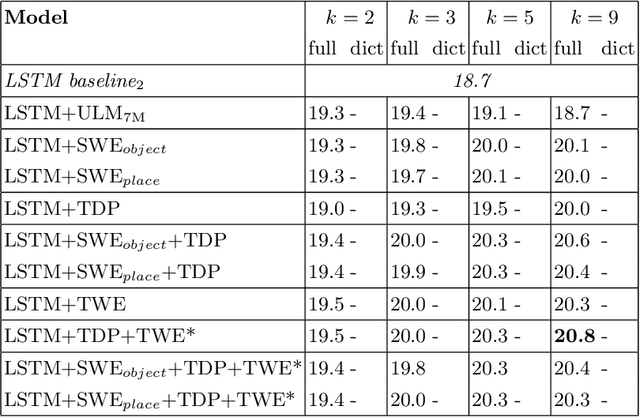
Applications such as textual entailment, plagiarism detection or document clustering rely on the notion of semantic similarity, and are usually approached with dimension reduction techniques like LDA or with embedding-based neural approaches. We present a scenario where semantic similarity is not enough, and we devise a neural approach to learn semantic relatedness. The scenario is text spotting in the wild, where a text in an image (e.g. street sign, advertisement or bus destination) must be identified and recognized. Our goal is to improve the performance of vision systems by leveraging semantic information. Our rationale is that the text to be spotted is often related to the image context in which it appears (word pairs such as Delta-airplane, or quarters-parking are not similar, but are clearly related). We show how learning a word-to-word or word-to-sentence relatedness score can improve the performance of text spotting systems up to 2.9 points, outperforming other measures in a benchmark dataset.
Visual Re-ranking with Natural Language Understanding for Text Spotting
Oct 29, 2018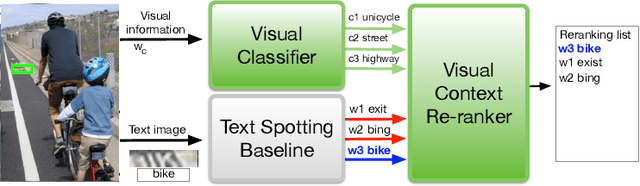
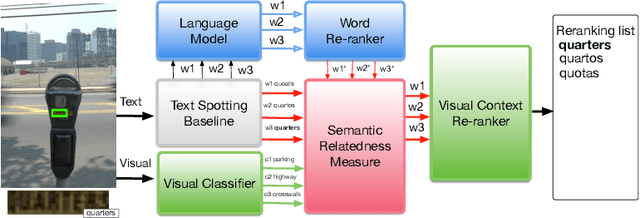
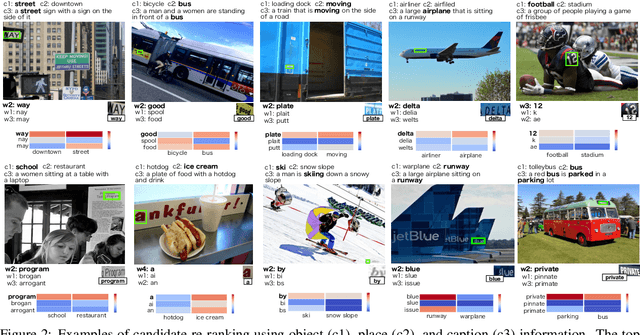
Many scene text recognition approaches are based on purely visual information and ignore the semantic relation between scene and text. In this paper, we tackle this problem from natural language processing perspective to fill the gap between language and vision. We propose a post-processing approach to improve scene text recognition accuracy by using occurrence probabilities of words (unigram language model), and the semantic correlation between scene and text. For this, we initially rely on an off-the-shelf deep neural network, already trained with a large amount of data, which provides a series of text hypotheses per input image. These hypotheses are then re-ranked using word frequencies and semantic relatedness with objects or scenes in the image. As a result of this combination, the performance of the original network is boosted with almost no additional cost. We validate our approach on ICDAR'17 dataset.
Visual Semantic Re-ranker for Text Spotting
Oct 27, 2018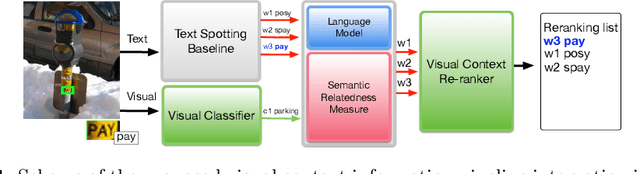
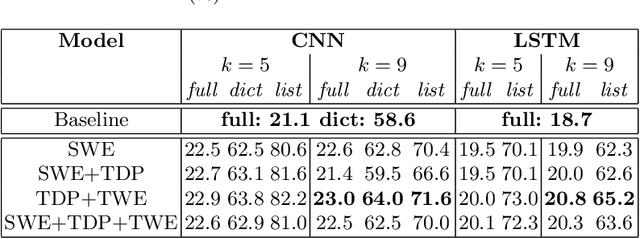
Many current state-of-the-art methods for text recognition are based on purely local information and ignore the semantic correlation between text and its surrounding visual context. In this paper, we propose a post-processing approach to improve the accuracy of text spotting by using the semantic relation between the text and the scene. We initially rely on an off-the-shelf deep neural network that provides a series of text hypotheses for each input image. These text hypotheses are then re-ranked using the semantic relatedness with the object in the image. As a result of this combination, the performance of the original network is boosted with a very low computational cost. The proposed framework can be used as a drop-in complement for any text-spotting algorithm that outputs a ranking of word hypotheses. We validate our approach on ICDAR'17 shared task dataset.