 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZipf's laws of meaning in Catalan
Jun 30, 2021
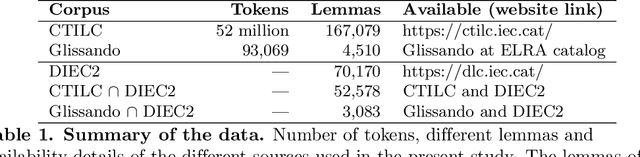
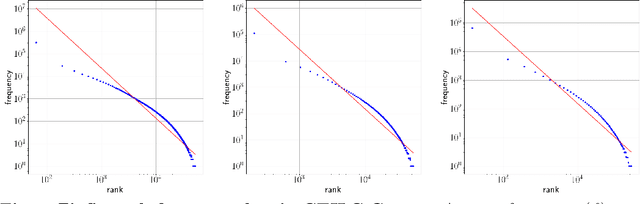
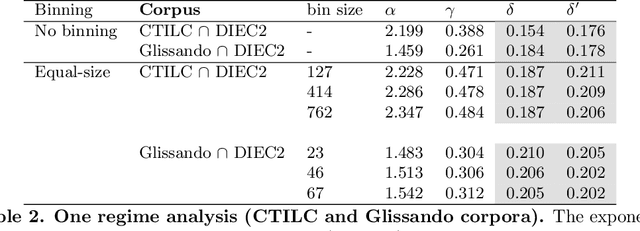
In his pioneering research, G. K. Zipf formulated a couple of statistical laws on the relationship between the frequency of a word with its number of meanings: the law of meaning distribution, relating the frequency of a word and its frequency rank, and the meaning-frequency law, relating the frequency of a word with its number of meanings. Although these laws were formulated more than half a century ago, they have been only investigated in a few languages. Here we present the first study of these laws in Catalan. We verify these laws in Catalan via the relationship among their exponents and that of the rank-frequency law. We present a new protocol for the analysis of these Zipfian laws that can be extended to other languages. We report the first evidence of two marked regimes for these laws in written language and speech, paralleling the two regimes in Zipf's rank-frequency law in large multi-author corpora discovered in early 2000s. Finally, the implications of these two regimes will be discussed.
Polysemy and brevity versus frequency in language
Mar 27, 2019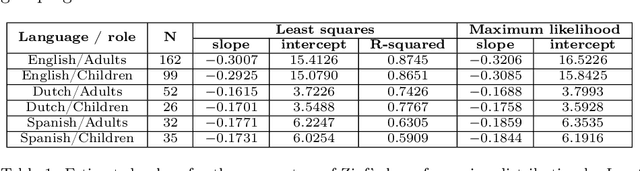
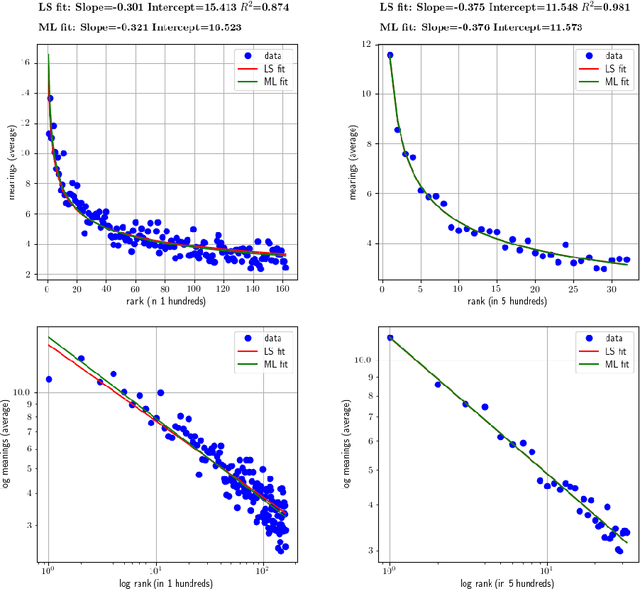
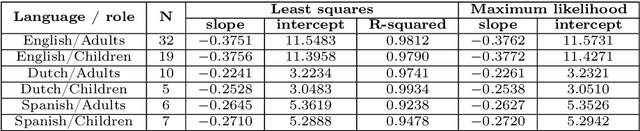
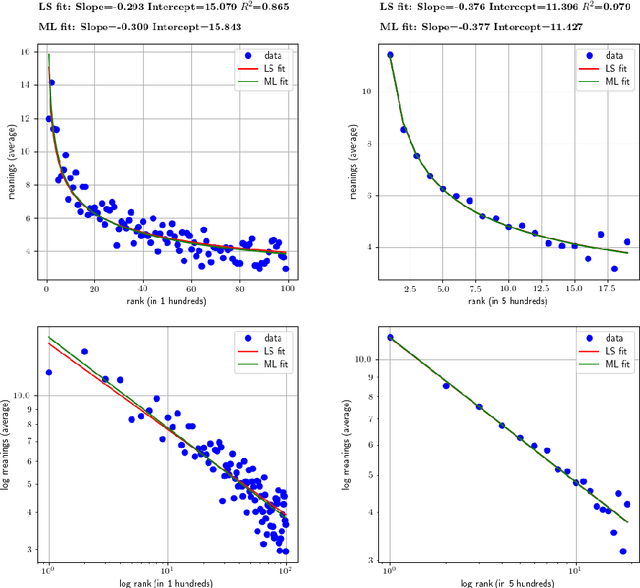
The pioneering research of G. K. Zipf on the relationship between word frequency and other word features led to the formulation of various linguistic laws. The most popular is Zipf's law for word frequencies. Here we focus on two laws that have been studied less intensively: the meaning-frequency law, i.e. the tendency of more frequent words to be more polysemous, and the law of abbreviation, i.e. the tendency of more frequent words to be shorter. In a previous work, we tested the robustness of these Zipfian laws for English, roughly measuring word length in number of characters and distinguishing adult from child speech. In the present article, we extend our study to other languages (Dutch and Spanish) and introduce two additional measures of length: syllabic length and phonemic length. Our correlation analysis indicates that both the meaning-frequency law and the law of abbreviation hold overall in all the analyzed languages.
The polysemy of the words that children learn over time
Nov 27, 2016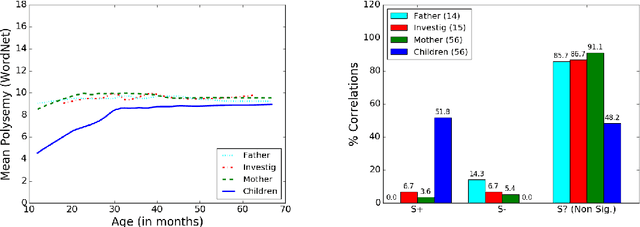
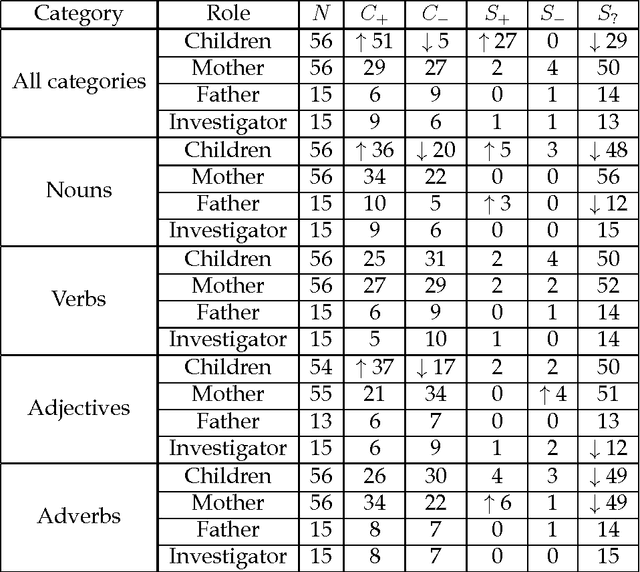
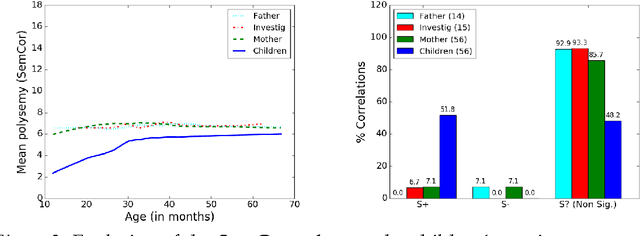
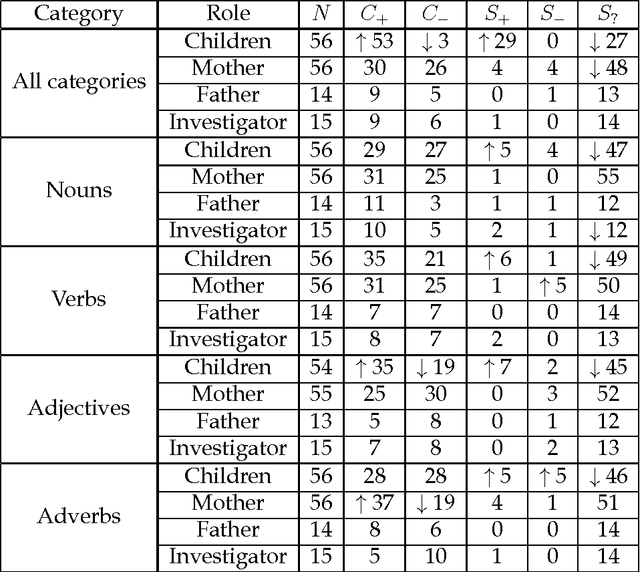
Here we study polysemy as a potential learning bias in vocabulary learning in children. We employ a massive set of transcriptions of conversations between children and adults in English, to analyze the evolution of mean polysemy in the words produced by children whose ages range between 10 and 60 months. Our results show that mean polysemy in children increases over time in two phases, i.e. a fast growth till the 31st month followed by a slower tendency towards adult speech. In contrast, no dependency with time is found in adults. This suggests that children have a preference for non-polysemous words in their early stages of vocabulary acquisition. Our hypothesis is twofold: (a) polysemy is a standalone bias or (b) polysemy is a side-effect of other biases. Interestingly, the bias for low polysemy described above weakens when controlling for syntactic category (noun, verb, adjective or adverb). The pattern of the evolution of polysemy suggests that both hypotheses may apply to some extent, and that (b) would originate from a combination of the well-known preference for nouns and the lower polysemy of nouns with respect to other syntactic categories.
The infochemical core
Oct 24, 2016Vocalizations and less often gestures have been the object of linguistic research over decades. However, the development of a general theory of communication with human language as a particular case requires a clear understanding of the organization of communication through other means. Infochemicals are chemical compounds that carry information and are employed by small organisms that cannot emit acoustic signals of optimal frequency to achieve successful communication. Here the distribution of infochemicals across species is investigated when they are ranked by their degree or the number of species with which it is associated (because they produce or they are sensitive to it). The quality of the fit of different functions to the dependency between degree and rank is evaluated with a penalty for the number of parameters of the function. Surprisingly, a double Zipf (a Zipf distribution with two regimes with a different exponent each) is the model yielding the best fit although it is the function with the largest number of parameters. This suggests that the world wide repertoire of infochemicals contains a chemical nucleus shared by many species and reminiscent of the core vocabularies found for human language in dictionaries or large corpora.
* Little corrections of format and language
The failure of the law of brevity in two New World primates. Statistical caveats
Sep 28, 2012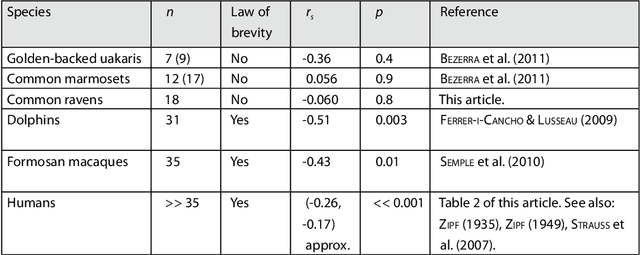
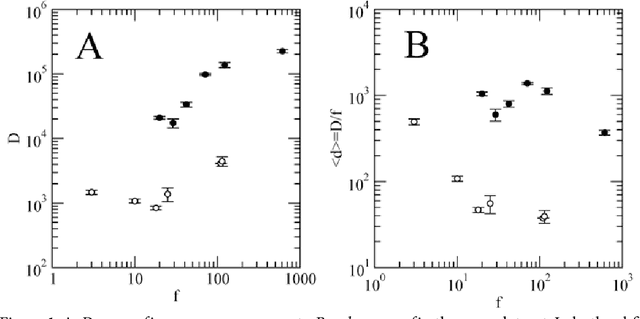
Parallels of Zipf's law of brevity, the tendency of more frequent words to be shorter, have been found in bottlenose dolphins and Formosan macaques. Although these findings suggest that behavioral repertoires are shaped by a general principle of compression, common marmosets and golden-backed uakaris do not exhibit the law. However, we argue that the law may be impossible or difficult to detect statistically in a given species if the repertoire is too small, a problem that could be affecting golden backed uakaris, and show that the law is present in a subset of the repertoire of common marmosets. We suggest that the visibility of the law will depend on the subset of the repertoire under consideration or the repertoire size.
* Little improvements in the statistical arguments