 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolysemy and brevity versus frequency in language
Mar 27, 2019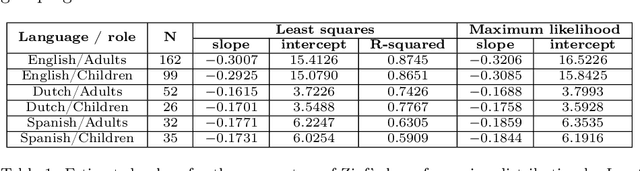
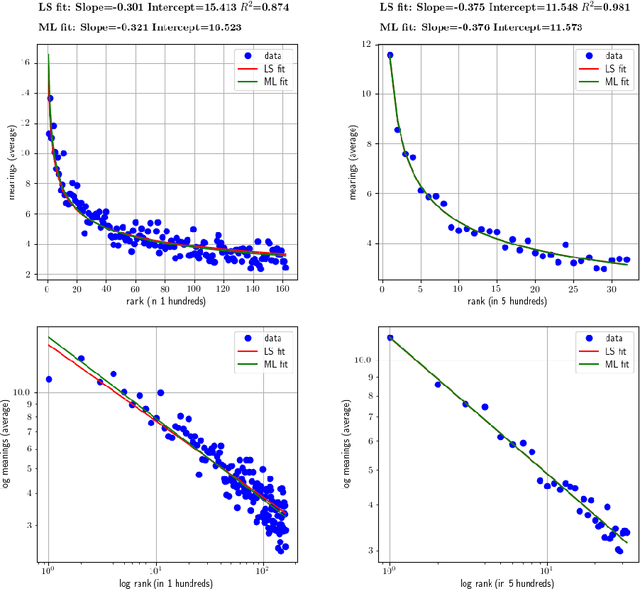
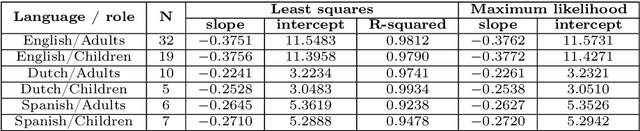
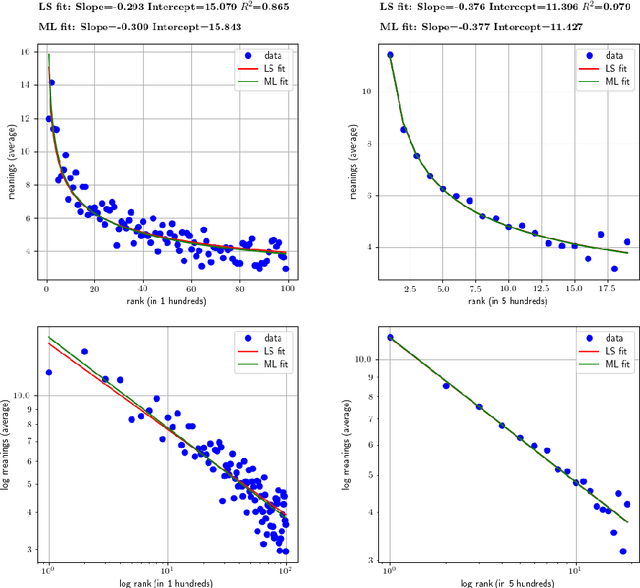
The pioneering research of G. K. Zipf on the relationship between word frequency and other word features led to the formulation of various linguistic laws. The most popular is Zipf's law for word frequencies. Here we focus on two laws that have been studied less intensively: the meaning-frequency law, i.e. the tendency of more frequent words to be more polysemous, and the law of abbreviation, i.e. the tendency of more frequent words to be shorter. In a previous work, we tested the robustness of these Zipfian laws for English, roughly measuring word length in number of characters and distinguishing adult from child speech. In the present article, we extend our study to other languages (Dutch and Spanish) and introduce two additional measures of length: syllabic length and phonemic length. Our correlation analysis indicates that both the meaning-frequency law and the law of abbreviation hold overall in all the analyzed languages.
Fast calculation of entropy with Zhang's estimator
Jul 26, 2017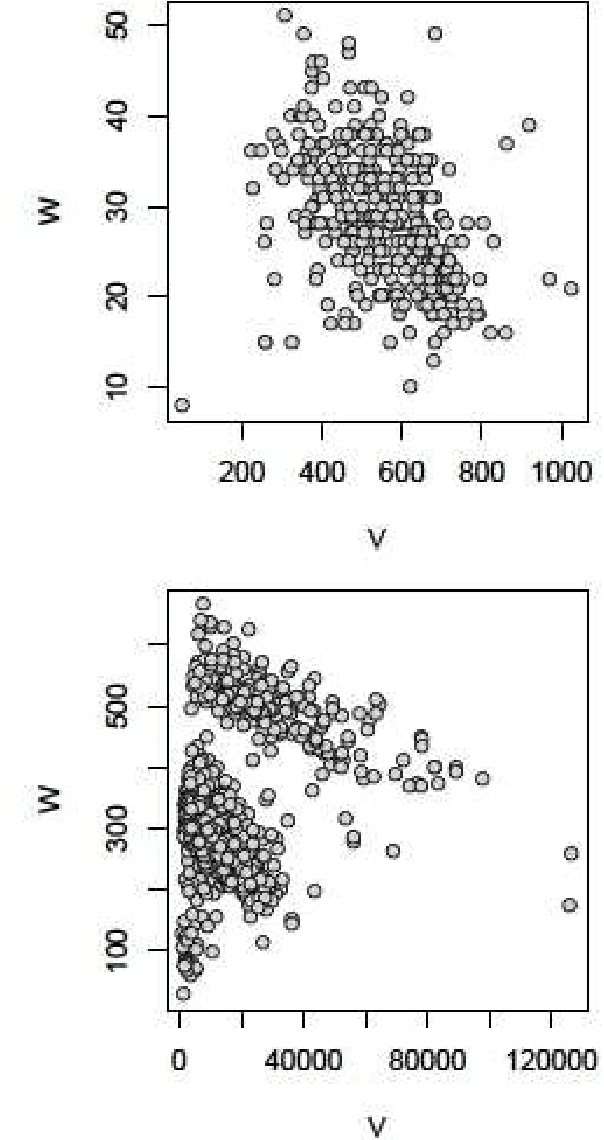
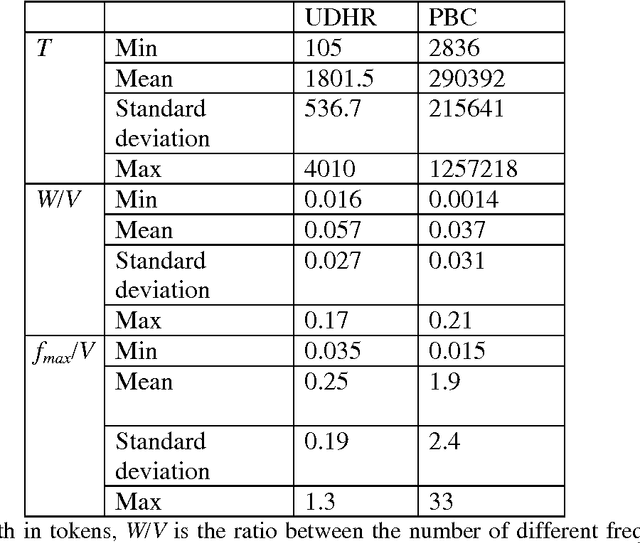
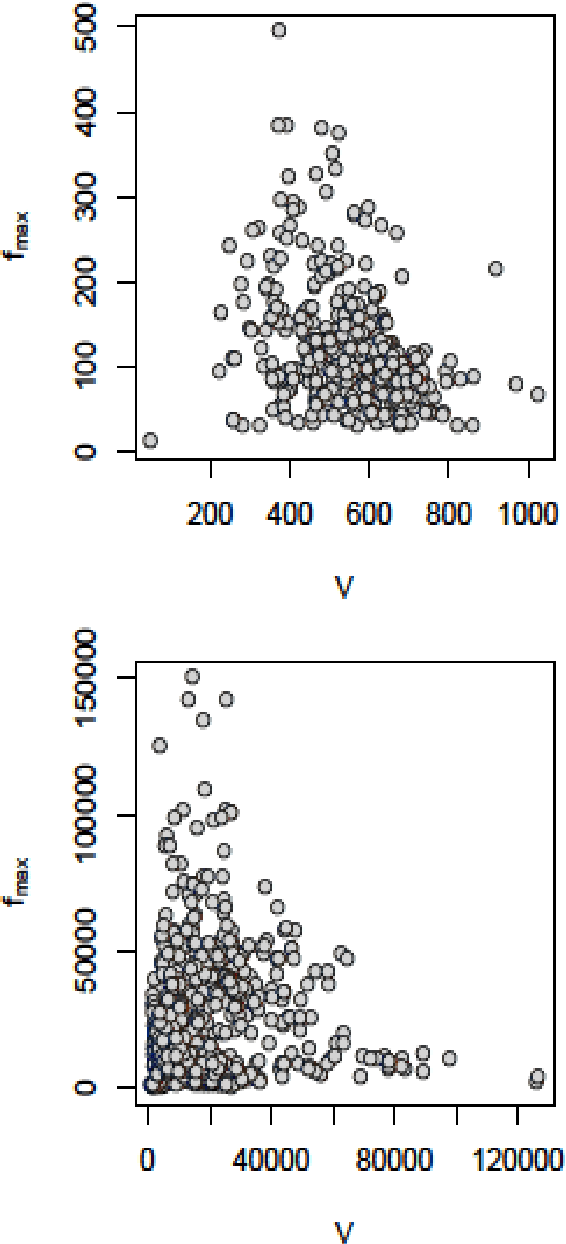
Entropy is a fundamental property of a repertoire. Here, we present an efficient algorithm to estimate the entropy of types with the help of Zhang's estimator. The algorithm takes advantage of the fact that the number of different frequencies in a text is in general much smaller than the number of types. We justify the convenience of the algorithm by means of an analysis of the statistical properties of texts from more than 1000 languages. Our work opens up various possibilities for future research.
The polysemy of the words that children learn over time
Nov 27, 2016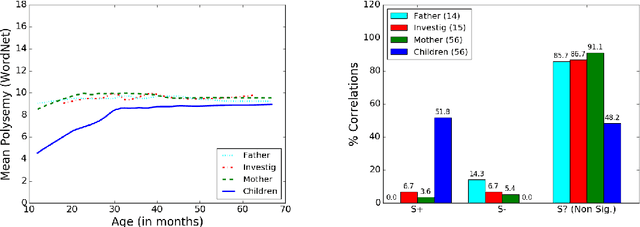
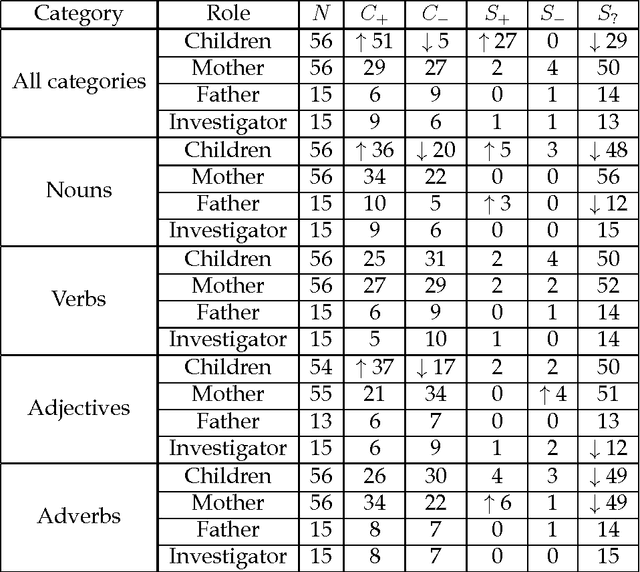
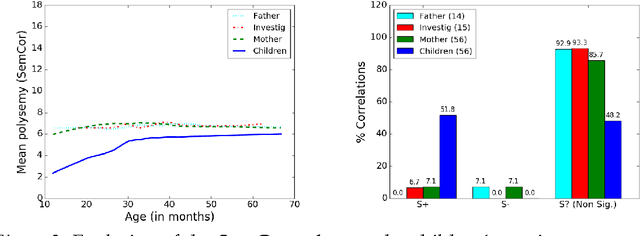
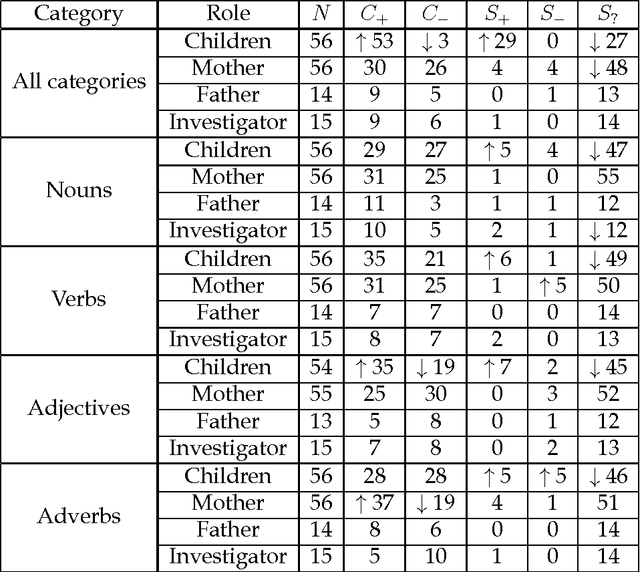
Here we study polysemy as a potential learning bias in vocabulary learning in children. We employ a massive set of transcriptions of conversations between children and adults in English, to analyze the evolution of mean polysemy in the words produced by children whose ages range between 10 and 60 months. Our results show that mean polysemy in children increases over time in two phases, i.e. a fast growth till the 31st month followed by a slower tendency towards adult speech. In contrast, no dependency with time is found in adults. This suggests that children have a preference for non-polysemous words in their early stages of vocabulary acquisition. Our hypothesis is twofold: (a) polysemy is a standalone bias or (b) polysemy is a side-effect of other biases. Interestingly, the bias for low polysemy described above weakens when controlling for syntactic category (noun, verb, adjective or adverb). The pattern of the evolution of polysemy suggests that both hypotheses may apply to some extent, and that (b) would originate from a combination of the well-known preference for nouns and the lower polysemy of nouns with respect to other syntactic categories.