 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation of perceived prosodic similarity of conversational feedback
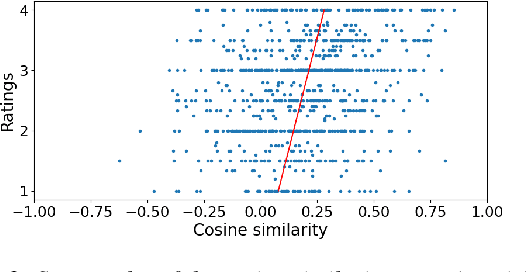
May 19, 2025Vocal feedback (e.g., `mhm', `yeah', `okay') is an important component of spoken dialogue and is crucial to ensuring common ground in conversational systems. The exact meaning of such feedback is conveyed through both lexical and prosodic form. In this work, we investigate the perceived prosodic similarity of vocal feedback with the same lexical form, and to what extent existing speech representations reflect such similarities. A triadic comparison task with recruited participants is used to measure perceived similarity of feedback responses taken from two different datasets. We find that spectral and self-supervised speech representations encode prosody better than extracted pitch features, especially in the case of feedback from the same speaker. We also find that it is possible to further condense and align the representations to human perception through contrastive learning.
Joint Learning of Context and Feedback Embeddings in Spoken Dialogue
Jun 11, 2024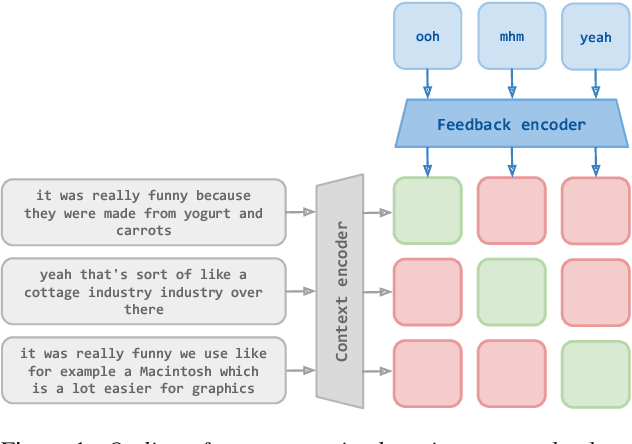


Short feedback responses, such as backchannels, play an important role in spoken dialogue. So far, most of the modeling of feedback responses has focused on their timing, often neglecting how their lexical and prosodic form influence their contextual appropriateness and conversational function. In this paper, we investigate the possibility of embedding short dialogue contexts and feedback responses in the same representation space using a contrastive learning objective. In our evaluation, we primarily focus on how such embeddings can be used as a context-feedback appropriateness metric and thus for feedback response ranking in U.S. English dialogues. Our results show that the model outperforms humans given the same ranking task and that the learned embeddings carry information about the conversational function of feedback responses.
Resolving References in Visually-Grounded Dialogue via Text Generation
Sep 23, 2023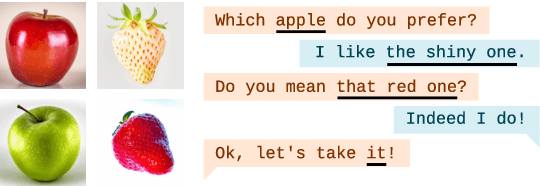
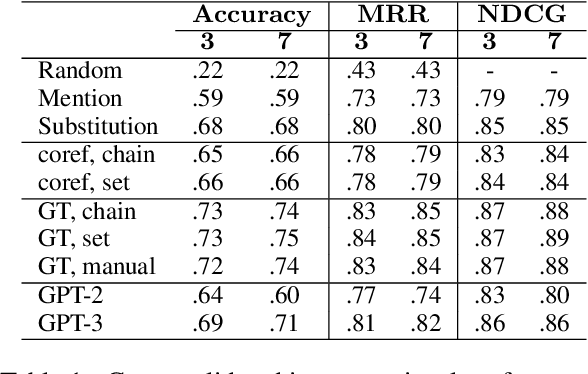

Vision-language models (VLMs) have shown to be effective at image retrieval based on simple text queries, but text-image retrieval based on conversational input remains a challenge. Consequently, if we want to use VLMs for reference resolution in visually-grounded dialogue, the discourse processing capabilities of these models need to be augmented. To address this issue, we propose fine-tuning a causal large language model (LLM) to generate definite descriptions that summarize coreferential information found in the linguistic context of references. We then use a pretrained VLM to identify referents based on the generated descriptions, zero-shot. We evaluate our approach on a manually annotated dataset of visually-grounded dialogues and achieve results that, on average, exceed the performance of the baselines we compare against. Furthermore, we find that using referent descriptions based on larger context windows has the potential to yield higher returns.