 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReferring Expression Generation in Visually Grounded Dialogue with Discourse-aware Comprehension Guiding
Sep 09, 2024
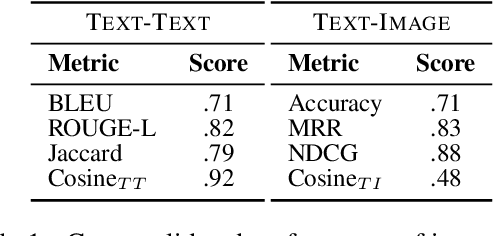
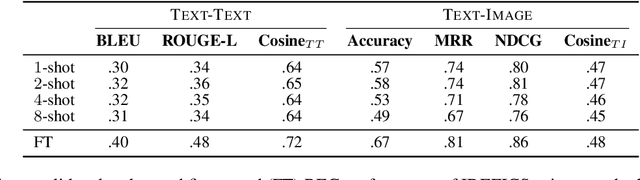
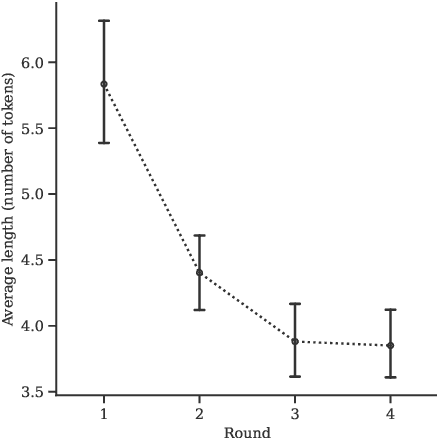
We propose an approach to referring expression generation (REG) in visually grounded dialogue that is meant to produce referring expressions (REs) that are both discriminative and discourse-appropriate. Our method constitutes a two-stage process. First, we model REG as a text- and image-conditioned next-token prediction task. REs are autoregressively generated based on their preceding linguistic context and a visual representation of the referent. Second, we propose the use of discourse-aware comprehension guiding as part of a generate-and-rerank strategy through which candidate REs generated with our REG model are reranked based on their discourse-dependent discriminatory power. Results from our human evaluation indicate that our proposed two-stage approach is effective in producing discriminative REs, with higher performance in terms of text-image retrieval accuracy for reranked REs compared to those generated using greedy decoding.
Resolving References in Visually-Grounded Dialogue via Text Generation
Sep 23, 2023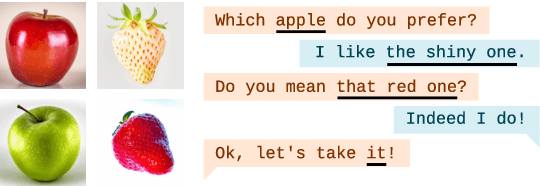
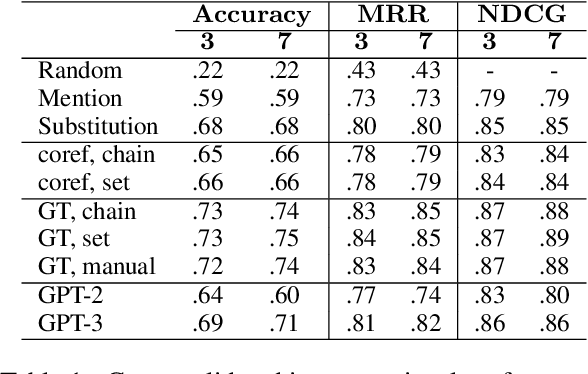

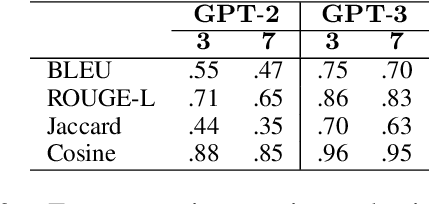
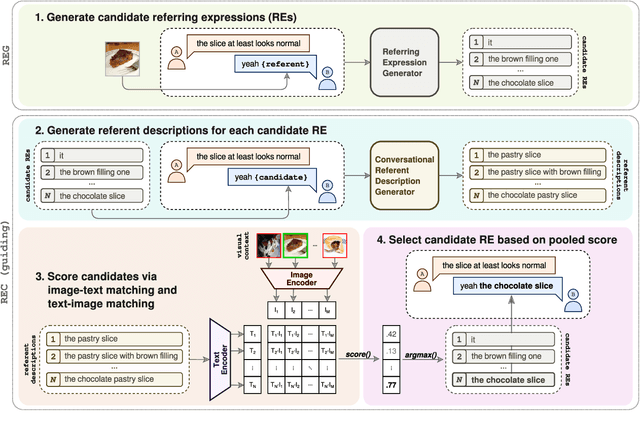
Vision-language models (VLMs) have shown to be effective at image retrieval based on simple text queries, but text-image retrieval based on conversational input remains a challenge. Consequently, if we want to use VLMs for reference resolution in visually-grounded dialogue, the discourse processing capabilities of these models need to be augmented. To address this issue, we propose fine-tuning a causal large language model (LLM) to generate definite descriptions that summarize coreferential information found in the linguistic context of references. We then use a pretrained VLM to identify referents based on the generated descriptions, zero-shot. We evaluate our approach on a manually annotated dataset of visually-grounded dialogues and achieve results that, on average, exceed the performance of the baselines we compare against. Furthermore, we find that using referent descriptions based on larger context windows has the potential to yield higher returns.
Collecting Visually-Grounded Dialogue with A Game Of Sorts
Sep 10, 2023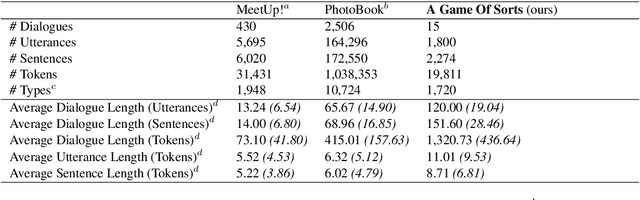
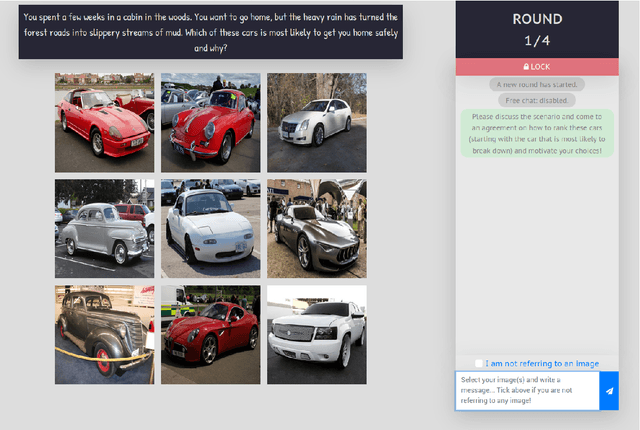
An idealized, though simplistic, view of the referring expression production and grounding process in (situated) dialogue assumes that a speaker must merely appropriately specify their expression so that the target referent may be successfully identified by the addressee. However, referring in conversation is a collaborative process that cannot be aptly characterized as an exchange of minimally-specified referring expressions. Concerns have been raised regarding assumptions made by prior work on visually-grounded dialogue that reveal an oversimplified view of conversation and the referential process. We address these concerns by introducing a collaborative image ranking task, a grounded agreement game we call "A Game Of Sorts". In our game, players are tasked with reaching agreement on how to rank a set of images given some sorting criterion through a largely unrestricted, role-symmetric dialogue. By putting emphasis on the argumentation in this mixed-initiative interaction, we collect discussions that involve the collaborative referential process. We describe results of a small-scale data collection experiment with the proposed task. All discussed materials, which includes the collected data, the codebase, and a containerized version of the application, are publicly available.
* Published at LREC 2022
CoLLIE: Continual Learning of Language Grounding from Language-Image Embeddings
Nov 15, 2021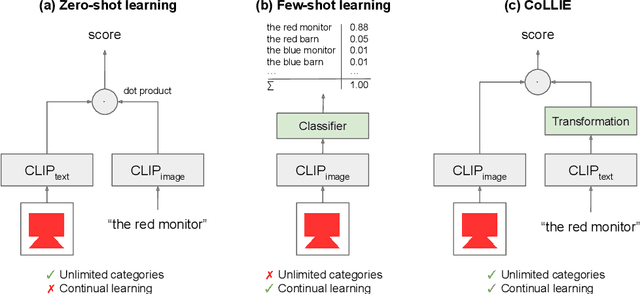
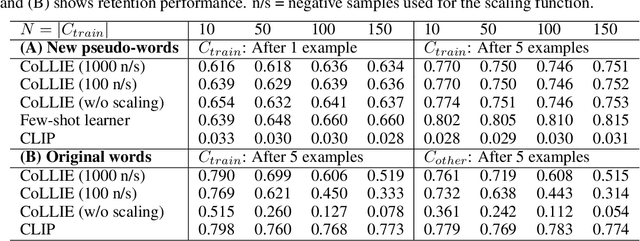
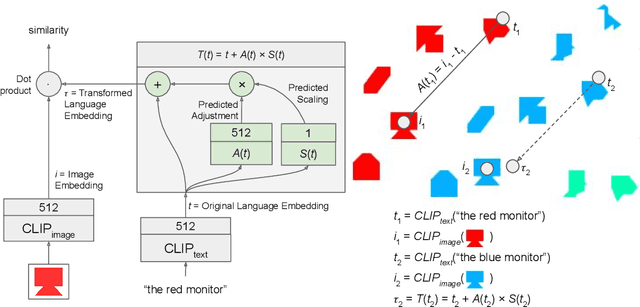
This paper presents CoLLIE: a simple, yet effective model for continual learning of how language is grounded in vision. Given a pre-trained multimodal embedding model, where language and images are projected in the same semantic space (in this case CLIP by OpenAI), CoLLIE learns a transformation function that adjusts the language embeddings when needed to accommodate new language use. Unlike traditional few-shot learning, the model does not just learn new classes and labels, but can also generalize to similar language use. We verify the model's performance on two different tasks of continual learning and show that it can efficiently learn and generalize from only a few examples, with little interference with the model's original zero-shot performance.