 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Forgetting in Federated Learning on Non-IID Data
Oct 17, 2019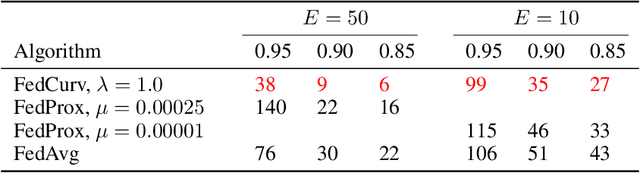
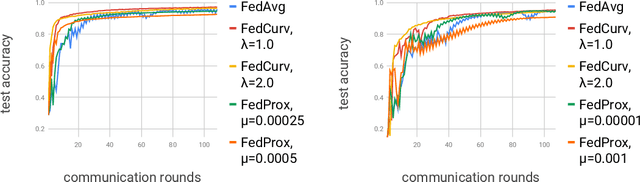
We tackle the problem of Federated Learning in the non i.i.d. case, in which local models drift apart, inhibiting learning. Building on an analogy with Lifelong Learning, we adapt a solution for catastrophic forgetting to Federated Learning. We add a penalty term to the loss function, compelling all local models to converge to a shared optimum. We show that this can be done efficiently for communication (adding no further privacy risks), scaling with the number of nodes in the distributed setting. Our experiments show that this method is superior to competing ones for image recognition on the MNIST dataset.
Sketching for Principal Component Regression
Mar 07, 2018
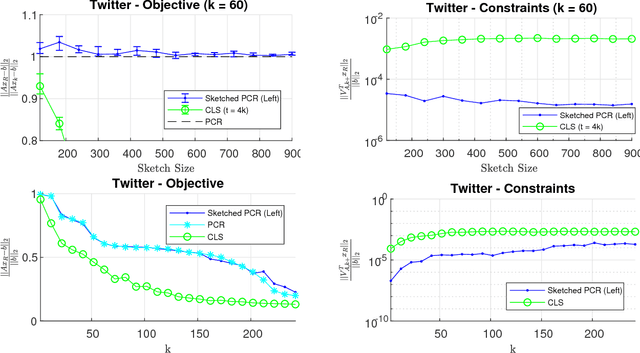
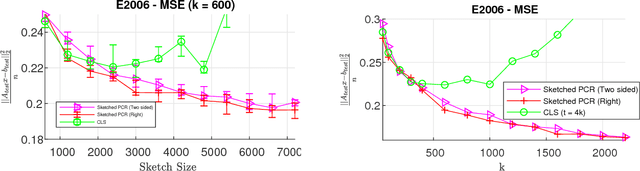
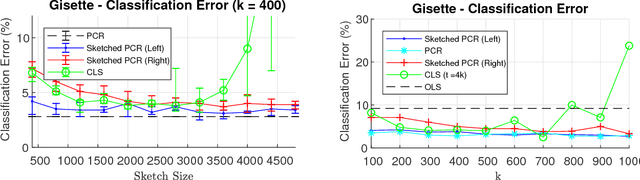
Principal component regression (PCR) is a useful method for regularizing linear regression. Although conceptually simple, straightforward implementations of PCR have high computational costs and so are inappropriate when learning with large scale data. In this paper, we propose efficient algorithms for computing approximate PCR solutions that are, on one hand, high quality approximations to the true PCR solutions (when viewed as minimizer of a constrained optimization problem), and on the other hand entertain rigorous risk bounds (when viewed as statistical estimators). In particular, we propose an input sparsity time algorithms for approximate PCR. We also consider computing an approximate PCR in the streaming model, and kernel PCR. Empirical results demonstrate the excellent performance of our proposed methods.