 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocally Asynchronous Stochastic Gradient Descent for Decentralised Deep Learning
Mar 24, 2022


Distributed training algorithms of deep neural networks show impressive convergence speedup properties on very large problems. However, they inherently suffer from communication related slowdowns and communication topology becomes a crucial design choice. Common approaches supported by most machine learning frameworks are: 1) Synchronous decentralized algorithms relying on a peer-to-peer All Reduce topology that is sensitive to stragglers and communication delays. 2) Asynchronous centralised algorithms with a server based topology that is prone to communication bottleneck. Researchers also suggested asynchronous decentralized algorithms designed to avoid the bottleneck and speedup training, however, those commonly use inexact sparse averaging that may lead to a degradation in accuracy. In this paper, we propose Local Asynchronous SGD (LASGD), an asynchronous decentralized algorithm that relies on All Reduce for model synchronization. We empirically validate LASGD's performance on image classification tasks on the ImageNet dataset. Our experiments demonstrate that LASGD accelerates training compared to SGD and state of the art gossip based approaches.
An Exploration into why Output Regularization Mitigates Label Noise
Apr 26, 2021Label noise presents a real challenge for supervised learning algorithms. Consequently, mitigating label noise has attracted immense research in recent years. Noise robust losses is one of the more promising approaches for dealing with label noise, as these methods only require changing the loss function and do not require changing the design of the classifier itself, which can be expensive in terms of development time. In this work we focus on losses that use output regularization (such as label smoothing and entropy). Although these losses perform well in practice, their ability to mitigate label noise lack mathematical rigor. In this work we aim at closing this gap by showing that losses, which incorporate an output regularization term, become symmetric as the regularization coefficient goes to infinity. We argue that the regularization coefficient can be seen as a hyper-parameter controlling the symmetricity, and thus, the noise robustness of the loss function.
Overcoming Forgetting in Federated Learning on Non-IID Data
Oct 17, 2019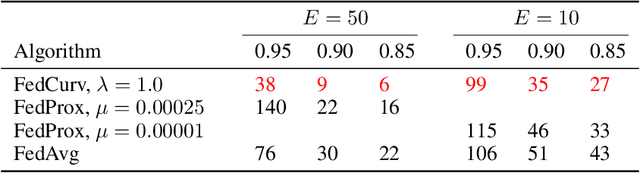
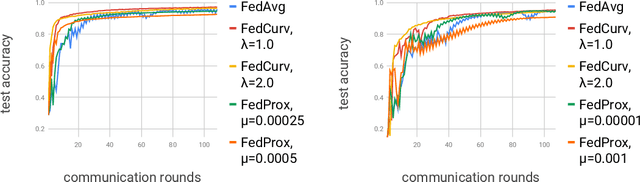
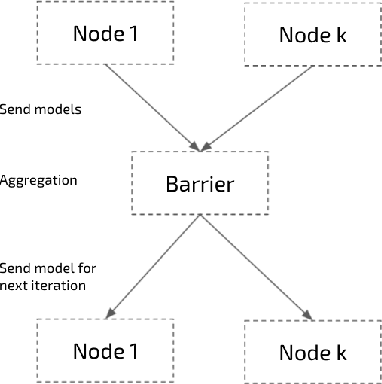
We tackle the problem of Federated Learning in the non i.i.d. case, in which local models drift apart, inhibiting learning. Building on an analogy with Lifelong Learning, we adapt a solution for catastrophic forgetting to Federated Learning. We add a penalty term to the loss function, compelling all local models to converge to a shared optimum. We show that this can be done efficiently for communication (adding no further privacy risks), scaling with the number of nodes in the distributed setting. Our experiments show that this method is superior to competing ones for image recognition on the MNIST dataset.