 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiscale Latent-Guided Entropy Model for LiDAR Point Cloud Compression
Sep 26, 2022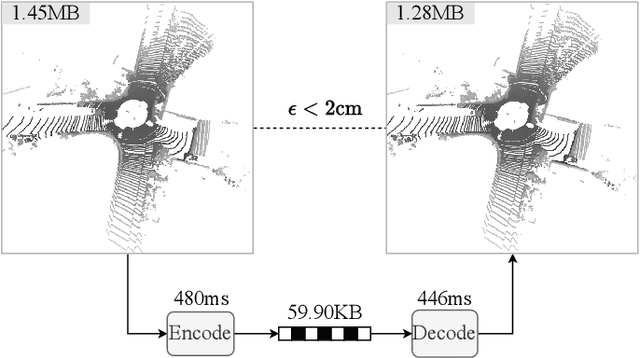
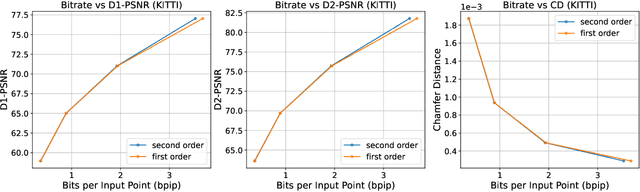
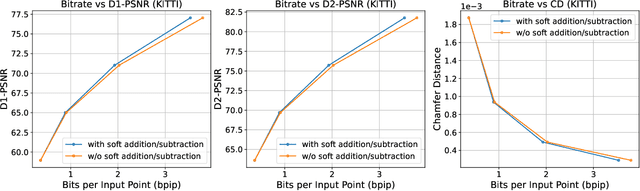
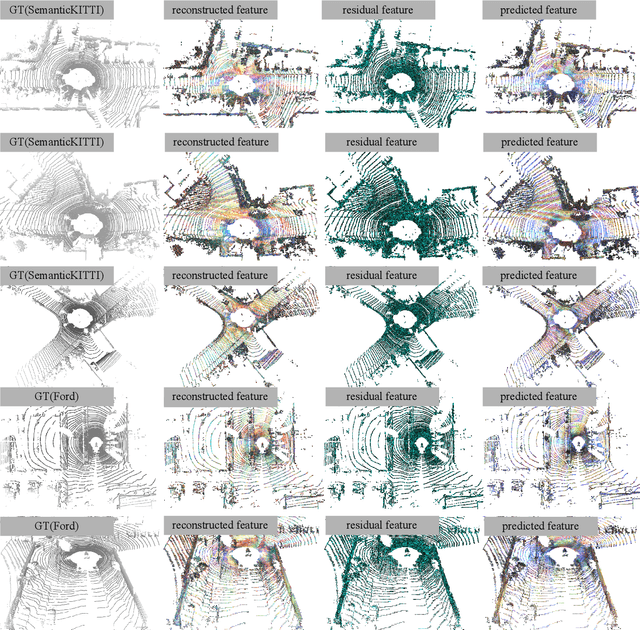
The non-uniform distribution and extremely sparse nature of the LiDAR point cloud (LPC) bring significant challenges to its high-efficient compression. This paper proposes a novel end-to-end, fully-factorized deep framework that encodes the original LPC into an octree structure and hierarchically decomposes the octree entropy model in layers. The proposed framework utilizes a hierarchical latent variable as side information to encapsulate the sibling and ancestor dependence, which provides sufficient context information for the modelling of point cloud distribution while enabling the parallel encoding and decoding of octree nodes in the same layer. Besides, we propose a residual coding framework for the compression of the latent variable, which explores the spatial correlation of each layer by progressive downsampling, and model the corresponding residual with a fully-factorized entropy model. Furthermore, we propose soft addition and subtraction for residual coding to improve network flexibility. The comprehensive experiment results on the LiDAR benchmark SemanticKITTI and MPEG-specified dataset Ford demonstrates that our proposed framework achieves state-of-the-art performance among all the previous LPC frameworks. Besides, our end-to-end, fully-factorized framework is proved by experiment to be high-parallelized and time-efficient and saves more than 99.8% of decoding time compared to previous state-of-the-art methods on LPC compression.
D-DPCC: Deep Dynamic Point Cloud Compression via 3D Motion Prediction
May 02, 2022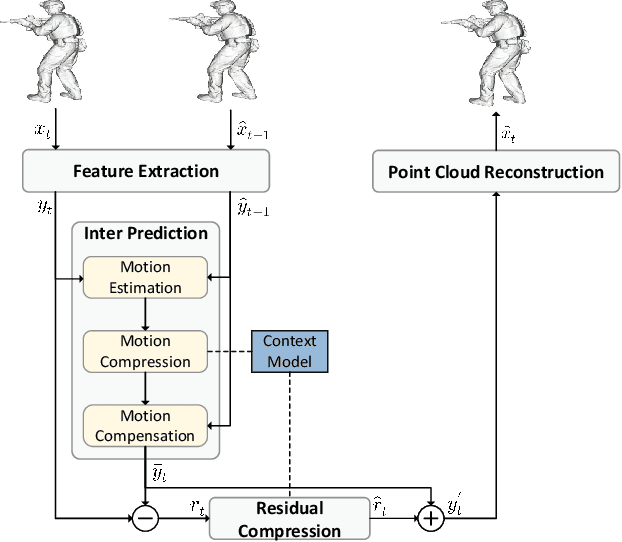
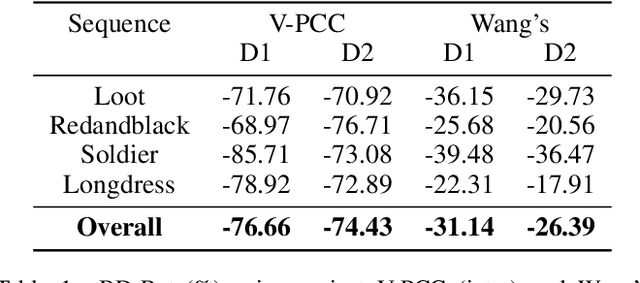
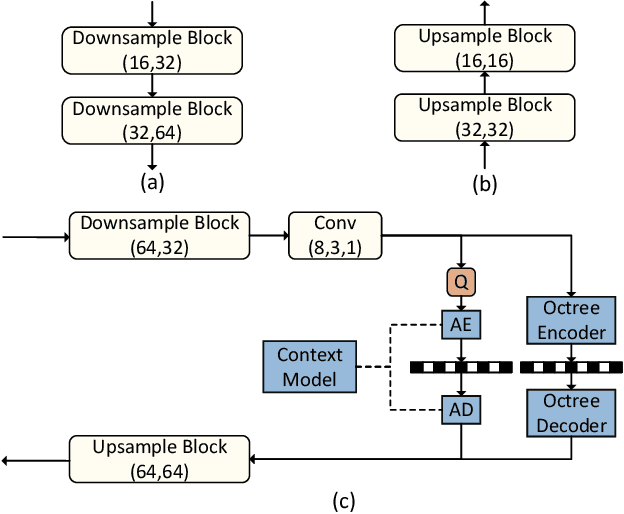
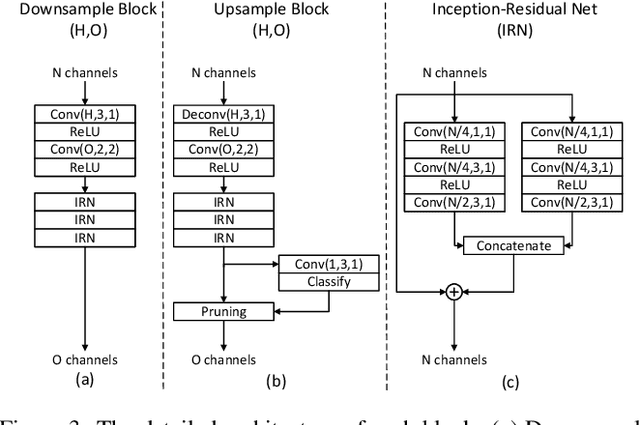
The non-uniformly distributed nature of the 3D dynamic point cloud (DPC) brings significant challenges to its high-efficient inter-frame compression. This paper proposes a novel 3D sparse convolution-based Deep Dynamic Point Cloud Compression (D-DPCC) network to compensate and compress the DPC geometry with 3D motion estimation and motion compensation in the feature space. In the proposed D-DPCC network, we design a {\it Multi-scale Motion Fusion} (MMF) module to accurately estimate the 3D optical flow between the feature representations of adjacent point cloud frames. Specifically, we utilize a 3D sparse convolution-based encoder to obtain the latent representation for motion estimation in the feature space and introduce the proposed MMF module for fused 3D motion embedding. Besides, for motion compensation, we propose a 3D {\it Adaptively Weighted Interpolation} (3DAWI) algorithm with a penalty coefficient to adaptively decrease the impact of distant neighbors. We compress the motion embedding and the residual with a lossy autoencoder-based network. To our knowledge, this paper is the first work proposing an end-to-end deep dynamic point cloud compression framework. The experimental result shows that the proposed D-DPCC framework achieves an average 76\% BD-Rate (Bjontegaard Delta Rate) gains against state-of-the-art Video-based Point Cloud Compression (V-PCC) v13 in inter mode.