 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRehabilitating the ColorChecker Dataset for Illuminant Estimation
Sep 17, 2018
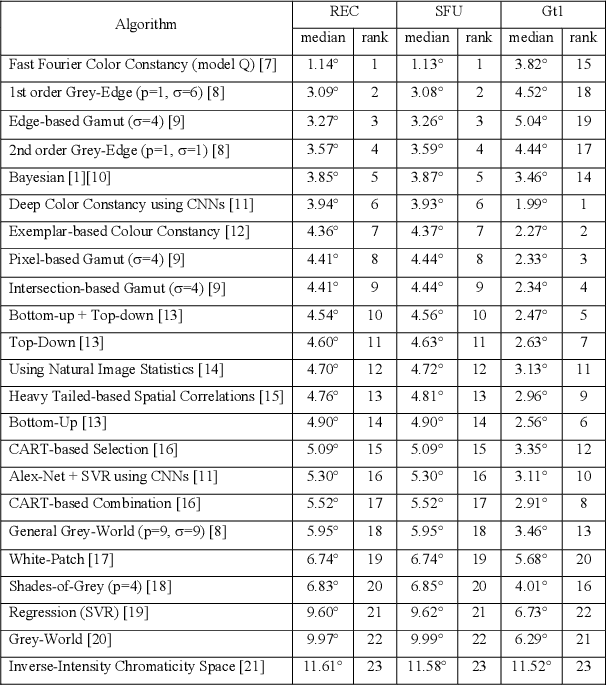
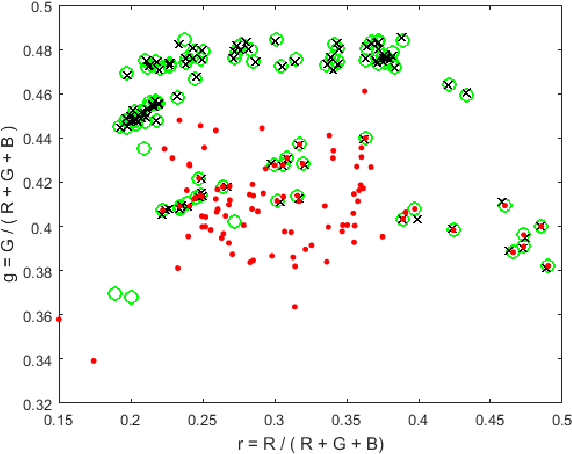
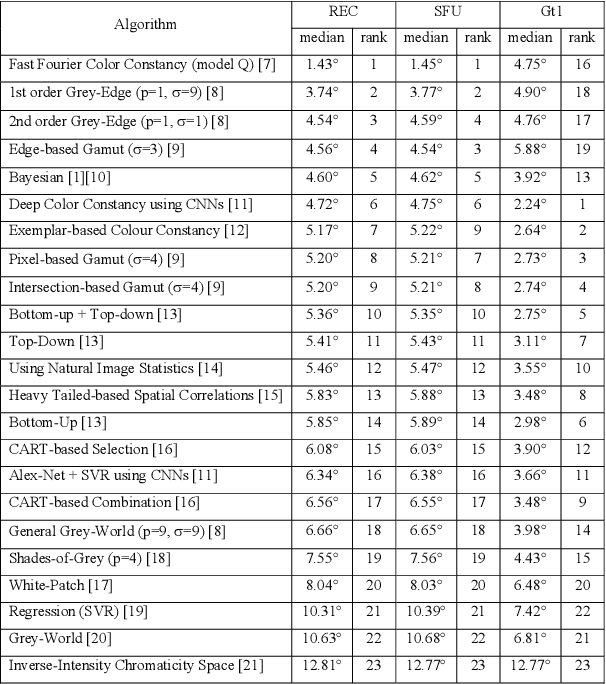
In a previous work, it was shown that there is a curious problem with the benchmark ColorChecker dataset for illuminant estimation. To wit, this dataset has at least 3 different sets of ground-truths. Typically, for a single algorithm a single ground-truth is used. But then different algorithms, whose performance is measured with respect to different ground-truths, are compared against each other and then ranked. This makes no sense. We show in this paper that there are also errors in how each ground-truth set was calculated. As a result, all performance rankings based on the ColorChecker dataset - and there are scores of these - are inaccurate. In this paper, we re-generate a new 'recommended' set of ground-truth based on the calculation methodology described by Shi and Funt. We then review the performance evaluation of a range of illuminant estimation algorithms. Compared with the legacy ground-truths, we find that the difference in how algorithms perform can be large, with many local rankings of algorithms being reversed. Finally, we draw the readers attention to our new 'open' data repository which, we hope, will allow the ColorChecker set to be rehabilitated and once again to become a useful benchmark for illuminant estimation algorithms.