 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-parametric spatially constrained local prior for scene parsing on real-world data
Jun 23, 2020
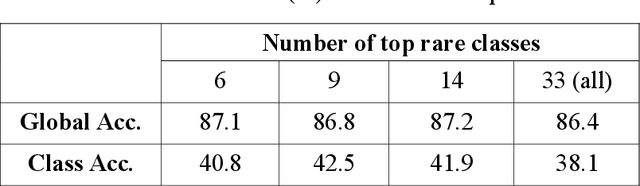
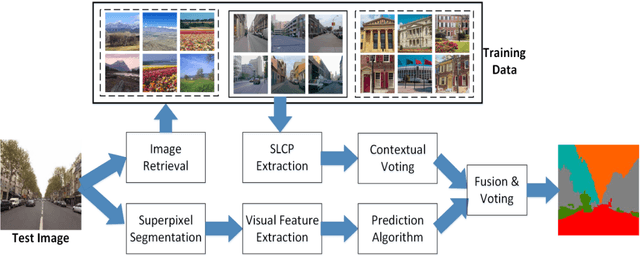
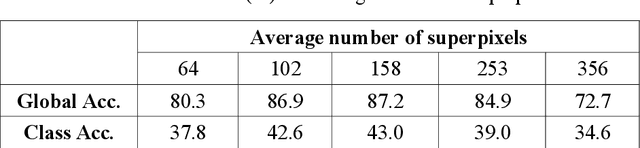
Scene parsing aims to recognize the object category of every pixel in scene images, and it plays a central role in image content understanding and computer vision applications. However, accurate scene parsing from unconstrained real-world data is still a challenging task. In this paper, we present the non-parametric Spatially Constrained Local Prior (SCLP) for scene parsing on realistic data. For a given query image, the non-parametric SCLP is learnt by first retrieving a subset of most similar training images to the query image and then collecting prior information about object co-occurrence statistics between spatial image blocks and between adjacent superpixels from the retrieved subset. The SCLP is powerful in capturing both long- and short-range context about inter-object correlations in the query image and can be effectively integrated with traditional visual features to refine the classification results. Our experiments on the SIFT Flow and PASCAL-Context benchmark datasets show that the non-parametric SCLP used in conjunction with superpixel-level visual features achieves one of the top performance compared with state-of-the-art approaches.
* 10 pages, journal
Spatially Constrained Location Prior for Scene Parsing
Feb 24, 2018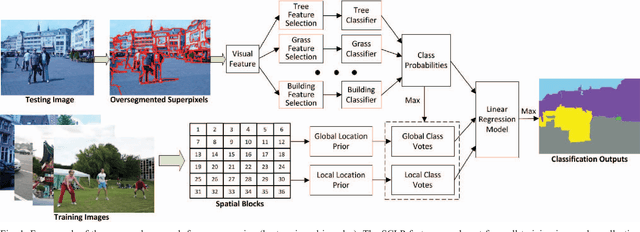
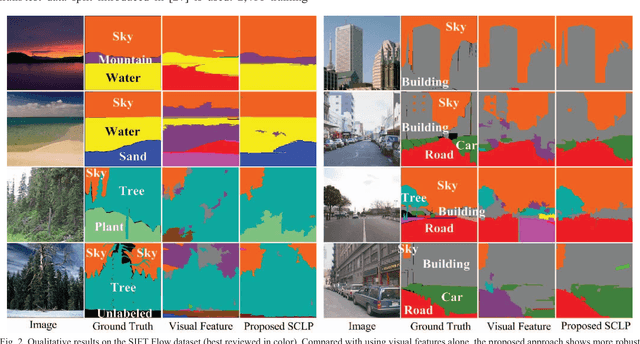
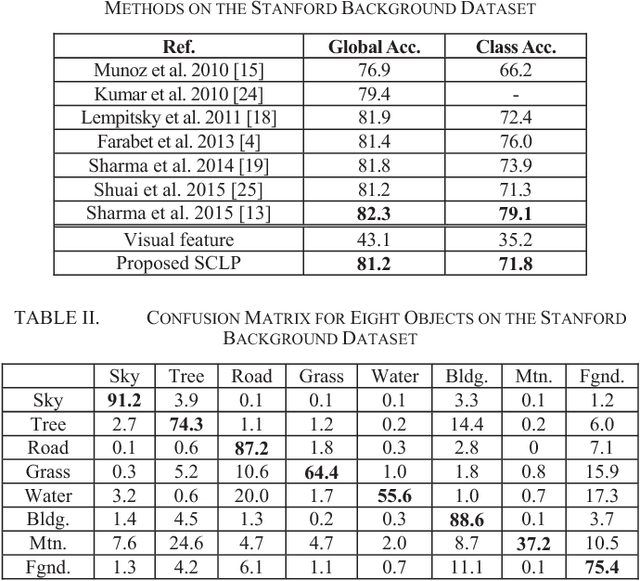
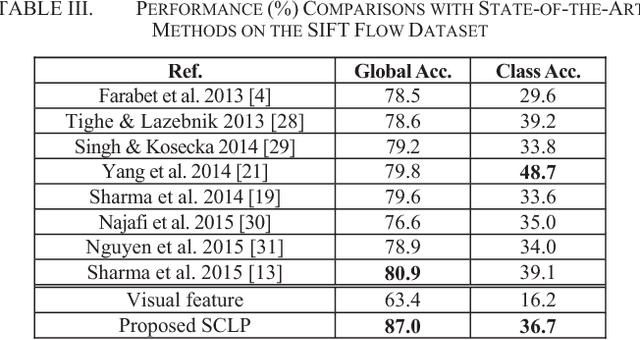
Semantic context is an important and useful cue for scene parsing in complicated natural images with a substantial amount of variations in objects and the environment. This paper proposes Spatially Constrained Location Prior (SCLP) for effective modelling of global and local semantic context in the scene in terms of inter-class spatial relationships. Unlike existing studies focusing on either relative or absolute location prior of objects, the SCLP effectively incorporates both relative and absolute location priors by calculating object co-occurrence frequencies in spatially constrained image blocks. The SCLP is general and can be used in conjunction with various visual feature-based prediction models, such as Artificial Neural Networks and Support Vector Machine (SVM), to enforce spatial contextual constraints on class labels. Using SVM classifiers and a linear regression model, we demonstrate that the incorporation of SCLP achieves superior performance compared to the state-of-the-art methods on the Stanford background and SIFT Flow datasets.
* authors' pre-print version of a article published in IJCNN 2016
Facial Expression Analysis under Partial Occlusion: A Survey
Feb 24, 2018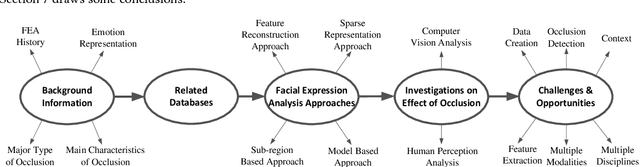


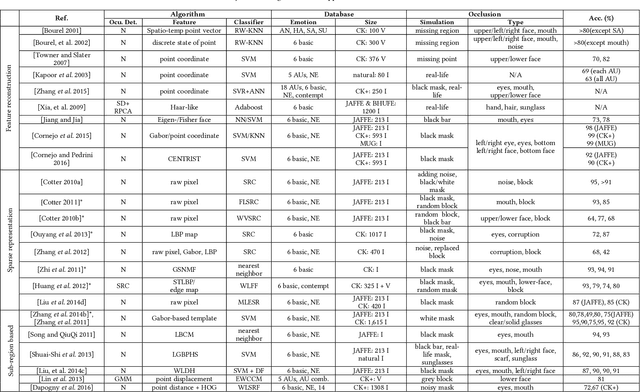
Automatic machine-based Facial Expression Analysis (FEA) has made substantial progress in the past few decades driven by its importance for applications in psychology, security, health, entertainment and human computer interaction. The vast majority of completed FEA studies are based on non-occluded faces collected in a controlled laboratory environment. Automatic expression recognition tolerant to partial occlusion remains less understood, particularly in real-world scenarios. In recent years, efforts investigating techniques to handle partial occlusion for FEA have seen an increase. The context is right for a comprehensive perspective of these developments and the state of the art from this perspective. This survey provides such a comprehensive review of recent advances in dataset creation, algorithm development, and investigations of the effects of occlusion critical for robust performance in FEA systems. It outlines existing challenges in overcoming partial occlusion and discusses possible opportunities in advancing the technology. To the best of our knowledge, it is the first FEA survey dedicated to occlusion and aimed at promoting better informed and benchmarked future work.
* Authors pre-print of the article accepted for publication in ACM Computing Surveys (accepted on 02-Nov-2017)
Superpixel based Class-Semantic Texton Occurrences for Natural Roadside Vegetation Segmentation
Feb 24, 2018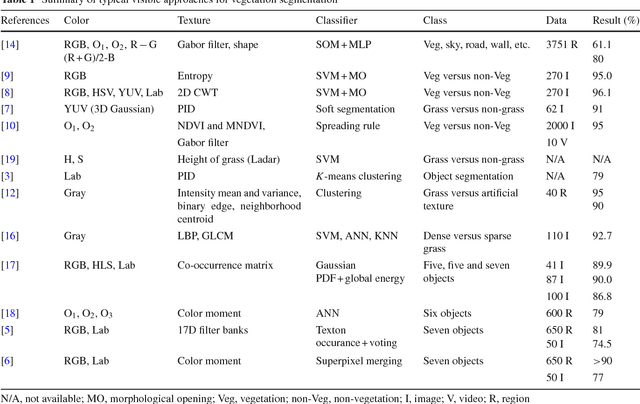
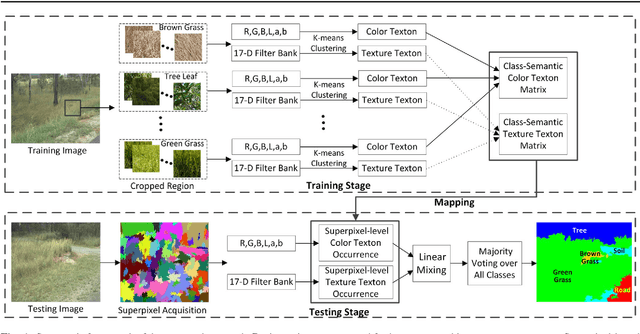


Vegetation segmentation from roadside data is a field that has received relatively little attention in present studies, but can be of great potentials in a wide range of real-world applications, such as road safety assessment and vegetation condition monitoring. In this paper, we present a novel approach that generates class-semantic color-texture textons and aggregates superpixel based texton occurrences for vegetation segmentation in natural roadside images. Pixel-level class-semantic textons are first learnt by generating two individual sets of bag-of-word visual dictionaries from color and filter-bank texture features separately for each object class using manually cropped training data. For a testing image, it is first oversegmented into a set of homogeneous superpixels. The color and texture features of all pixels in each superpixel are extracted and further mapped to one of the learnt textons using the nearest distance metric, resulting in a color and a texture texton occurrence matrix. The color and texture texton occurrences are aggregated using a linear mixing method over each superpixel and the segmentation is finally achieved using a simple yet effective majority voting strategy. Evaluations on two public image datasets from videos collected by the Department of Transport and Main Roads (DTMR), Queensland, Australia, and a public roadside grass dataset show high accuracy of the proposed approach. We also demonstrate the effectiveness of the approach for vegetation segmentation in real-world scenarios.
* This is a pre-print of an article published in Machine Vision and Applications. The final authenticated version is available online at: https://doi.org/10.1007/s00138-017-0833-7
Density Weighted Connectivity of Grass Pixels in Image Frames for Biomass Estimation
Feb 21, 2018
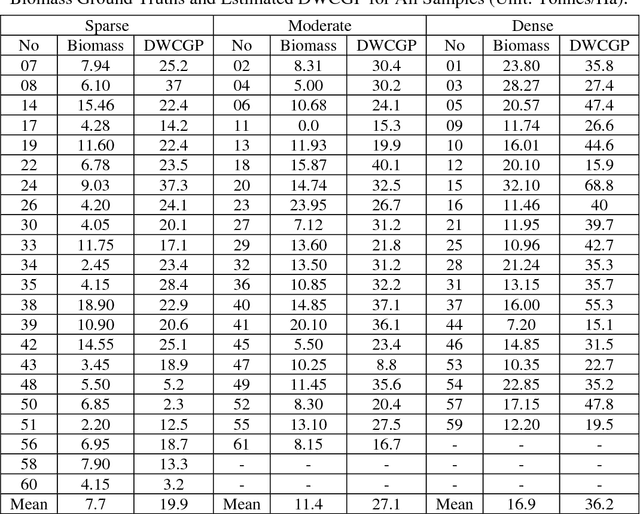
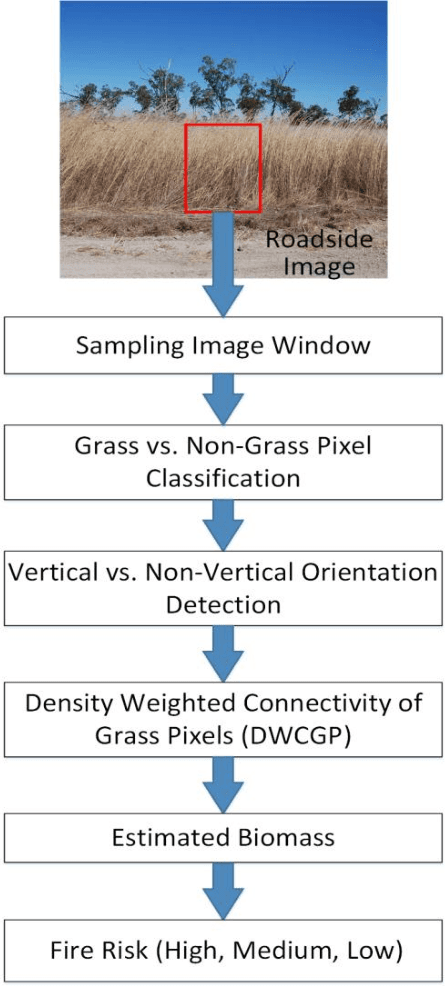

Accurate estimation of the biomass of roadside grasses plays a significant role in applications such as fire-prone region identification. Current solutions heavily depend on field surveys, remote sensing measurements and image processing using reference markers, which often demand big investments of time, effort and cost. This paper proposes Density Weighted Connectivity of Grass Pixels (DWCGP) to automatically estimate grass biomass from roadside image data. The DWCGP calculates the length of continuously connected grass pixels along a vertical orientation in each image column, and then weights the length by the grass density in a surrounding region of the column. Grass pixels are classified using feedforward artificial neural networks and the dominant texture orientation at every pixel is computed using multi-orientation Gabor wavelet filter vote. Evaluations on a field survey dataset show that the DWCGP reduces Root-Mean-Square Error from 5.84 to 5.52 by additionally considering grass density on top of grass height. The DWCGP shows robustness to non-vertical grass stems and to changes of both Gabor filter parameters and surrounding region widths. It also has performance close to human observation and higher than eight baseline approaches, as well as promising results for classifying low vs. high fire risk and identifying fire-prone road regions.