 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatially Constrained Location Prior for Scene Parsing
Paper and Code
Feb 24, 2018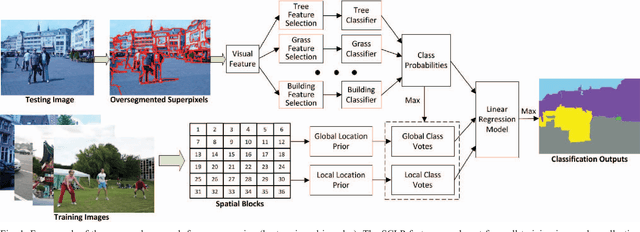
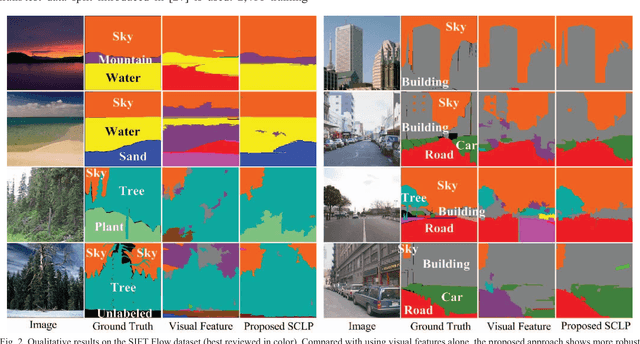
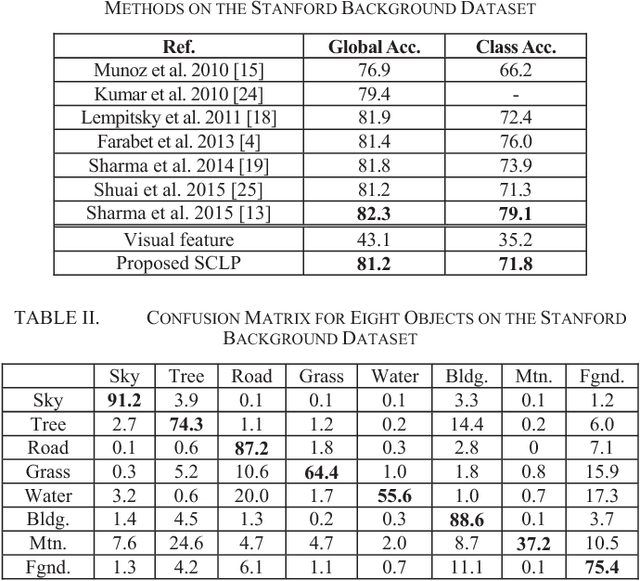
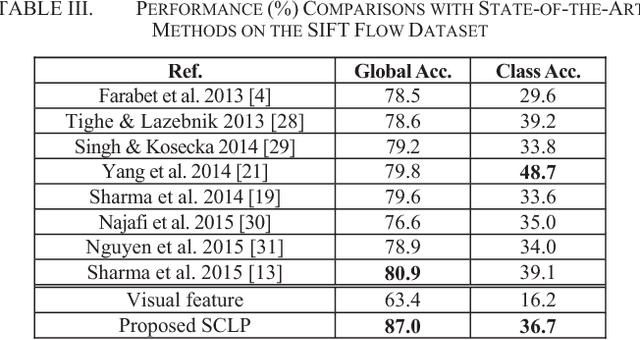
Semantic context is an important and useful cue for scene parsing in complicated natural images with a substantial amount of variations in objects and the environment. This paper proposes Spatially Constrained Location Prior (SCLP) for effective modelling of global and local semantic context in the scene in terms of inter-class spatial relationships. Unlike existing studies focusing on either relative or absolute location prior of objects, the SCLP effectively incorporates both relative and absolute location priors by calculating object co-occurrence frequencies in spatially constrained image blocks. The SCLP is general and can be used in conjunction with various visual feature-based prediction models, such as Artificial Neural Networks and Support Vector Machine (SVM), to enforce spatial contextual constraints on class labels. Using SVM classifiers and a linear regression model, we demonstrate that the incorporation of SCLP achieves superior performance compared to the state-of-the-art methods on the Stanford background and SIFT Flow datasets.