 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat type of inference is planning?
Jun 25, 2024



Multiple types of inference are available for probabilistic graphical models, e.g., marginal, maximum-a-posteriori, and even marginal maximum-a-posteriori. Which one do researchers mean when they talk about "planning as inference"? There is no consistency in the literature, different types are used, and their ability to do planning is further entangled with specific approximations or additional constraints. In this work we use the variational framework to show that all commonly used types of inference correspond to different weightings of the entropy terms in the variational problem, and that planning corresponds _exactly_ to a _different_ set of weights. This means that all the tricks of variational inference are readily applicable to planning. We develop an analogue of loopy belief propagation that allows us to perform approximate planning in factored state Markov decisions processes without incurring intractability due to the exponentially large state space. The variational perspective shows that the previous types of inference for planning are only adequate in environments with low stochasticity, and allows us to characterize each type by its own merits, disentangling the type of inference from the additional approximations that its practical use requires. We validate these results empirically on synthetic MDPs and tasks posed in the International Planning Competition.
Associating Grasp Configurations with Hierarchical Features in Convolutional Neural Networks
Jul 26, 2017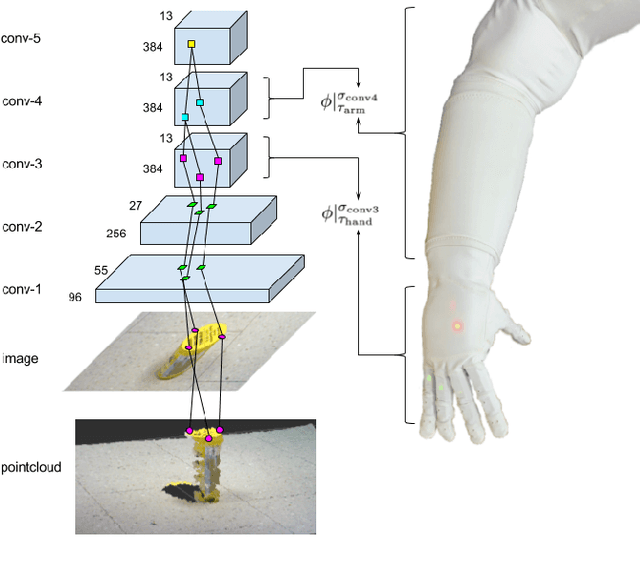


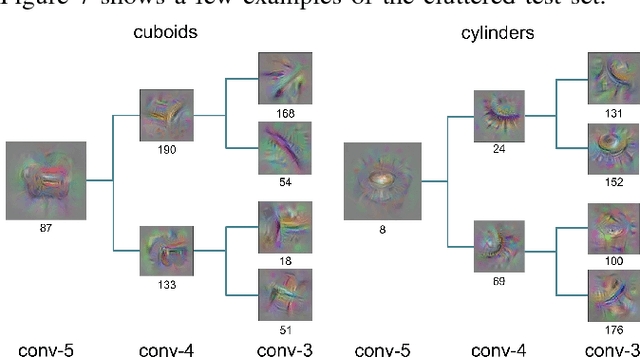
In this work, we provide a solution for posturing the anthropomorphic Robonaut-2 hand and arm for grasping based on visual information. A mapping from visual features extracted from a convolutional neural network (CNN) to grasp points is learned. We demonstrate that a CNN pre-trained for image classification can be applied to a grasping task based on a small set of grasping examples. Our approach takes advantage of the hierarchical nature of the CNN by identifying features that capture the hierarchical support relations between filters in different CNN layers and locating their 3D positions by tracing activations backwards in the CNN. When this backward trace terminates in the RGB-D image, important manipulable structures are thereby localized. These features that reside in different layers of the CNN are then associated with controllers that engage different kinematic subchains in the hand/arm system for grasping. A grasping dataset is collected using demonstrated hand/object relationships for Robonaut-2 to evaluate the proposed approach in terms of the precision of the resulting preshape postures. We demonstrate that this approach outperforms baseline approaches in cluttered scenarios on the grasping dataset and a point cloud based approach on a grasping task using Robonaut-2.