 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning deep kernels for exponential family densities
Nov 22, 2018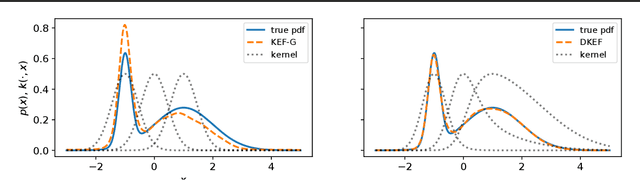
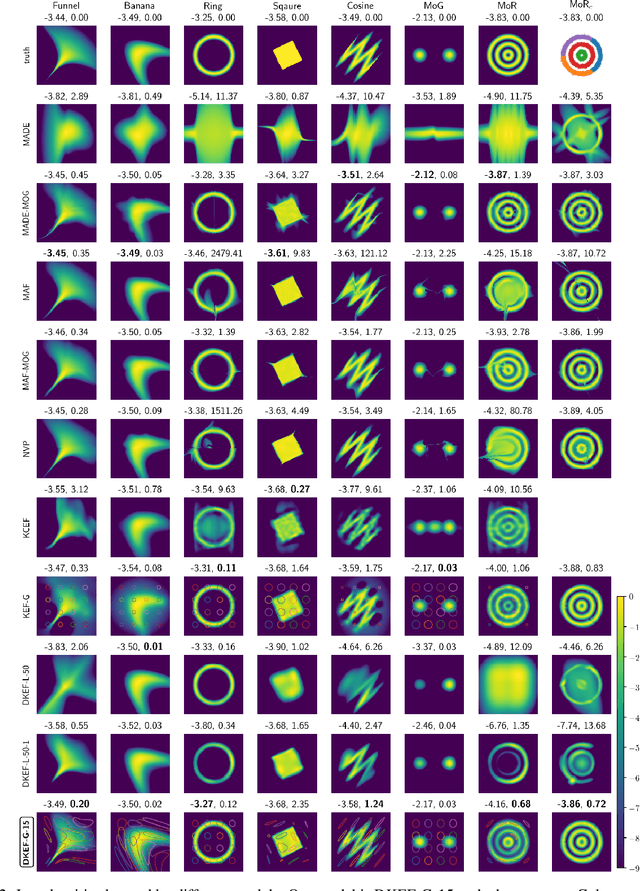
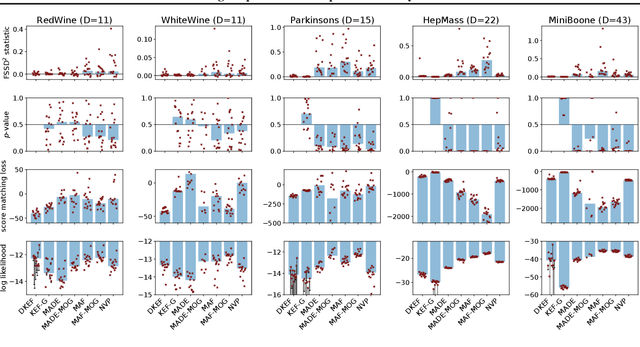
The kernel exponential family is a rich class of distributions,which can be fit efficiently and with statistical guarantees by score matching. Being required to choose a priori a simple kernel such as the Gaussian, however, limits its practical applicability. We provide a scheme for learning a kernel parameterized by a deep network, which can find complex location-dependent local features of the data geometry. This gives a very rich class of density models, capable of fitting complex structures on moderate-dimensional problems. Compared to deep density models fit via maximum likelihood, our approach provides a complementary set of strengths and tradeoffs: in empirical studies, the former can yield higher likelihoods, whereas the latter gives better estimates of the gradient of the log density, the score, which describes the distribution's shape.