 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocation Privacy-Enabled Beamforming in ISAC Scenarios
Aug 13, 2025Integrated sensing and communication (ISAC) technology enables simultaneous environmental perception and data transmission in wireless networks; however, it also exposes user location to receivers. In this paper, we introduce a novel beamforming framework guided by the proposed privacy metric direction of arrival obfuscation ratio (DAOR) to protect transmitter location privacy in ISAC scenarios. Unlike previous approaches, we do not suppress the line-of-sight (LOS) component while reshaping the angular power distribution so that a false direction appears dominant at the receiver. We derive closed-form bounds on the feasible DAOR via generalized eigenvalue analysis and formulate an achievable rate-maximization problem under the DAOR constraint. The resulting problem is non-convex, which is efficiently solved using semidefinite relaxation, eigenmode selection, and optimal power allocation. A suboptimal design strategy is also proposed with reduced complexity. Numerical results demonstrate that the proposed DAOR-based beamformer achieves a trade-off between location privacy and communication rate without nullifying the LOS path. Results also show that a suboptimal design achieves a near-optimal communication rate with nearly an 85% reduction in computation time at a signal-to-noise ratio (SNR) of 10 dB.
Enhancing UAV Path Planning Efficiency Through Accelerated Learning
Jan 17, 2025Unmanned Aerial Vehicles (UAVs) are increasingly essential in various fields such as surveillance, reconnaissance, and telecommunications. This study aims to develop a learning algorithm for the path planning of UAV wireless communication relays, which can reduce storage requirements and accelerate Deep Reinforcement Learning (DRL) convergence. Assuming the system possesses terrain maps of the area and can estimate user locations using localization algorithms or direct GPS reporting, it can input these parameters into the learning algorithms to achieve optimized path planning performance. However, higher resolution terrain maps are necessary to extract topological information such as terrain height, object distances, and signal blockages. This requirement increases memory and storage demands on UAVs while also lengthening convergence times in DRL algorithms. Similarly, defining the telecommunication coverage map in UAV wireless communication relays using these terrain maps and user position estimations demands higher memory and storage utilization for the learning path planning algorithms. Our approach reduces path planning training time by applying a dimensionality reduction technique based on Principal Component Analysis (PCA), sample combination, Prioritized Experience Replay (PER), and the combination of Mean Squared Error (MSE) and Mean Absolute Error (MAE) loss calculations in the coverage map estimates, thereby enhancing a Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm. The proposed solution reduces the convergence episodes needed for basic training by approximately four times compared to the traditional TD3.
PCA-Featured Transformer for Jamming Detection in 5G UAV Networks
Dec 19, 2024Jamming attacks pose a threat to Unmanned Aerial Vehicle (UAV) wireless communication systems, potentially disrupting essential services and compromising network reliability. Current detection approaches struggle with sophisticated artificial intelligence (AI) jamming techniques that adapt their patterns while existing machine learning solutions often require extensive feature engineering and fail to capture complex temporal dependencies in attack signatures. Furthermore, 5G networks using either Time Division Duplex (TDD) or Frequency Division Duplex (FDD) methods can face service degradation from intentional interference sources. To address these challenges, we present a novel transformer-based deep learning framework for jamming detection with Principal Component Analysis (PCA) added features. Our architecture leverages the transformer's self-attention mechanism to capture complex temporal dependencies and spatial correlations in wireless signal characteristics, enabling more robust jamming detection techniques. The U-shaped model incorporates a modified transformer encoder that processes signal features including received signal strength indicator (RSSI) and signal-to-noise ratio (SINR) measurements, alongside a specialized positional encoding scheme that accounts for the periodic nature of wireless signals. In addition, we propose a batch size scheduler and implement chunking techniques to optimize training convergence for time series data. These advancements contribute to achieving up to a ten times improvement in training speed within the advanced U-shaped encoder-decoder model introduced. Simulation results demonstrate that our approach achieves a detection accuracy of 90.33 \% in Line-of-Sight (LoS) and 84.35 % in non-Line-of-Sight (NLoS) and outperforms machine learning methods and existing deep learning solutions such as the XGBoost (XGB) classifier in approximately 4%.
Joint Transmit and Jamming Power Optimization for Secrecy in Energy Harvesting Networks: A Reinforcement Learning Approach
Jul 24, 2024



In this paper, we address the problem of joint allocation of transmit and jamming power at the source and destination, respectively, to enhance the long-term cumulative secrecy performance of an energy-harvesting wireless communication system until it stops functioning in the presence of an eavesdropper. The source and destination have energy-harvesting devices with limited battery capacities. The destination also has a full-duplex transceiver to transmit jamming signals for secrecy. We frame the problem as an infinite-horizon Markov decision process (MDP) problem and propose a reinforcement learning-based optimal joint power allocation (OJPA) algorithm that employs a policy iteration (PI) algorithm. Since the optimal algorithm is computationally expensive, we develop a low-complexity sub-optimal joint power allocation (SJPA) algorithm, namely, reduced state joint power allocation (RSJPA). Two other SJPA algorithms, the greedy algorithm (GA) and the naive algorithm (NA), are implemented as benchmarks. In addition, the OJPA algorithm outperforms the individual power allocation (IPA) algorithms termed individual transmit power allocation (ITPA) and individual jamming power allocation (IJPA), where the transmit and jamming powers, respectively, are optimized individually. The results show that the OJPA algorithm is also more energy efficient. Simulation results show that the OJPA algorithm significantly improves the secrecy performance compared to all SJPA algorithms. The proposed RSJPA algorithm achieves nearly optimal performance with significantly less computational complexity marking it the balanced choice between the complexity and the performance. We find that the computational time for the RSJPA algorithm is around 75 percent less than the OJPA algorithm.
Multi-task Learning-based Joint CSI Prediction and Predictive Transmitter Selection for Security
May 01, 2024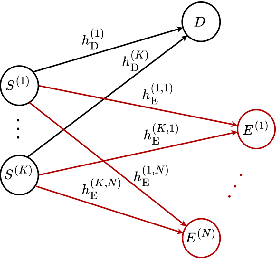
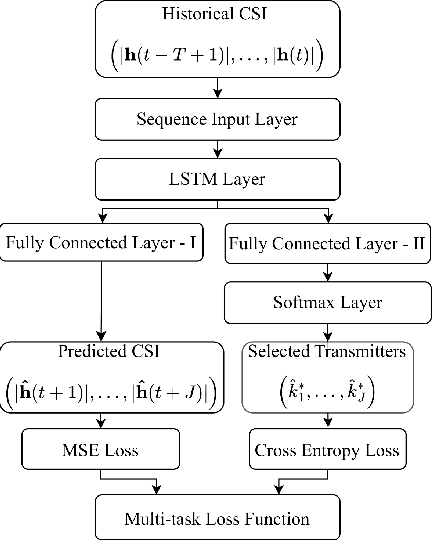
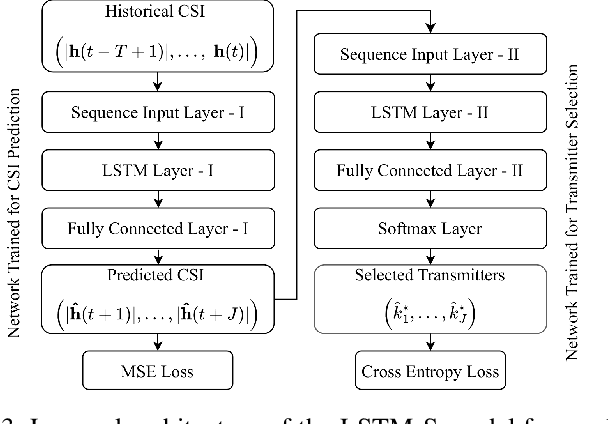
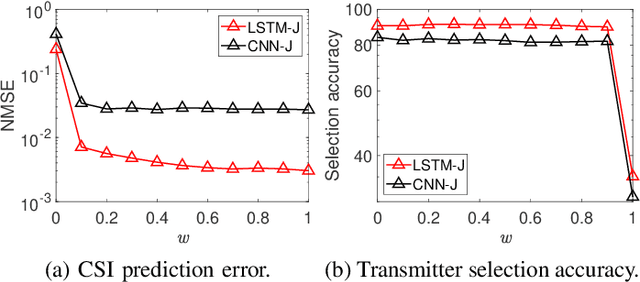
In mobile communication scenarios, the acquired channel state information (CSI) rapidly becomes outdated due to fast-changing channels. Opportunistic transmitter selection based on current CSI for secrecy improvement may be outdated during actual transmission, negating the diversity benefit of transmitter selection. Motivated by this problem, we propose a joint CSI prediction and predictive selection of the optimal transmitter strategy based on historical CSI by exploiting the temporal correlation among CSIs. The proposed solution utilizes the multi-task learning (MTL) framework by employing a single Long Short-Term Memory (LSTM) network architecture that simultaneously learns two tasks of predicting the CSI and selecting the optimal transmitter in parallel instead of learning these tasks sequentially. The proposed LSTM architecture outperforms convolutional neural network (CNN) based architecture due to its superior ability to capture temporal features in the data. Compared to the sequential task learning models, the MTL architecture provides superior predicted secrecy performance for a large variation in the number of transmitters and the speed of mobile nodes. It also offers significant computational and memory efficiency, leading to a substantial saving in computational time by around 40 percent.