 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Discovery under Latent Class Confounding
Nov 13, 2023Directed acyclic graphs are used to model the causal structure of a system. ``Causal discovery'' describes the problem of learning this structure from data. When data is an aggregate from multiple sources (populations or environments), global confounding obscures conditional independence properties that drive many causal discovery algorithms. For this reason, existing causal discovery algorithms are not suitable for the multiple-source setting. We demonstrate that, if the confounding is of bounded cardinality (i.e. the data comes from a limited number of sources), causal discovery can still be achieved. The feasibility of this problem is governed by a trade-off between the cardinality of the global confounder, the cardinalities of the observed variables, and the sparsity of the causal structure.
Learning Mixtures of Arbitrary Distributions over Large Discrete Domains
Sep 18, 2013We give an algorithm for learning a mixture of {\em unstructured} distributions. This problem arises in various unsupervised learning scenarios, for example in learning {\em topic models} from a corpus of documents spanning several topics. We show how to learn the constituents of a mixture of $k$ arbitrary distributions over a large discrete domain $[n]=\{1,2,\dots,n\}$ and the mixture weights, using $O(n\polylog n)$ samples. (In the topic-model learning setting, the mixture constituents correspond to the topic distributions.) This task is information-theoretically impossible for $k>1$ under the usual sampling process from a mixture distribution. However, there are situations (such as the above-mentioned topic model case) in which each sample point consists of several observations from the same mixture constituent. This number of observations, which we call the {\em "sampling aperture"}, is a crucial parameter of the problem. We obtain the {\em first} bounds for this mixture-learning problem {\em without imposing any assumptions on the mixture constituents.} We show that efficient learning is possible exactly at the information-theoretically least-possible aperture of $2k-1$. Thus, we achieve near-optimal dependence on $n$ and optimal aperture. While the sample-size required by our algorithm depends exponentially on $k$, we prove that such a dependence is {\em unavoidable} when one considers general mixtures. A sequence of tools contribute to the algorithm, such as concentration results for random matrices, dimension reduction, moment estimations, and sensitivity analysis.
A Two-round Variant of EM for Gaussian Mixtures
Jan 16, 2013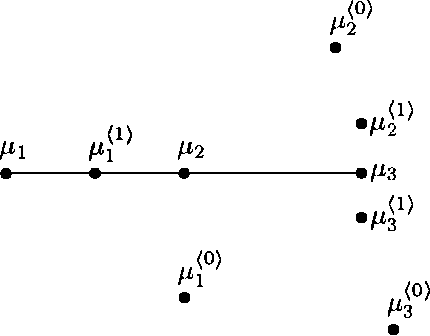
Given a set of possible models (e.g., Bayesian network structures) and a data sample, in the unsupervised model selection problem the task is to choose the most accurate model with respect to the domain joint probability distribution. In contrast to this, in supervised model selection it is a priori known that the chosen model will be used in the future for prediction tasks involving more ``focused' predictive distributions. Although focused predictive distributions can be produced from the joint probability distribution by marginalization, in practice the best model in the unsupervised sense does not necessarily perform well in supervised domains. In particular, the standard marginal likelihood score is a criterion for the unsupervised task, and, although frequently used for supervised model selection also, does not perform well in such tasks. In this paper we study the performance of the marginal likelihood score empirically in supervised Bayesian network selection tasks by using a large number of publicly available classification data sets, and compare the results to those obtained by alternative model selection criteria, including empirical crossvalidation methods, an approximation of a supervised marginal likelihood measure, and a supervised version of Dawids prequential(predictive sequential) principle.The results demonstrate that the marginal likelihood score does NOT perform well FOR supervised model selection, WHILE the best results are obtained BY using Dawids prequential r napproach.