 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDMP: Multi-modal Diffusion for supervised Motion Predictions with uncertainty
Oct 04, 2024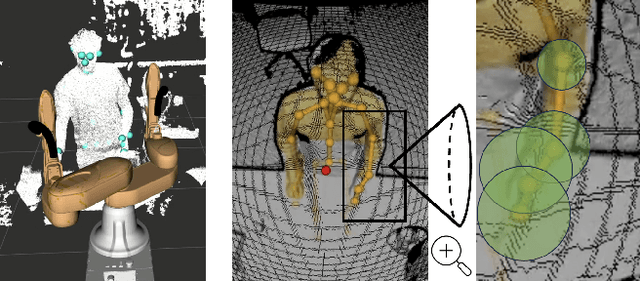
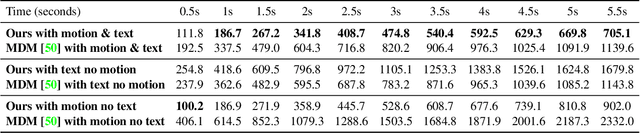

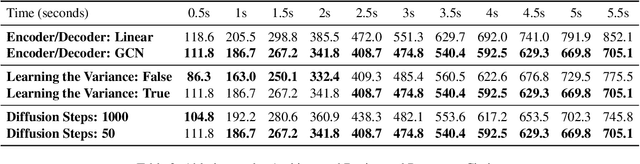
This paper introduces a Multi-modal Diffusion model for Motion Prediction (MDMP) that integrates and synchronizes skeletal data and textual descriptions of actions to generate refined long-term motion predictions with quantifiable uncertainty. Existing methods for motion forecasting or motion generation rely solely on either prior motions or text prompts, facing limitations with precision or control, particularly over extended durations. The multi-modal nature of our approach enhances the contextual understanding of human motion, while our graph-based transformer framework effectively capture both spatial and temporal motion dynamics. As a result, our model consistently outperforms existing generative techniques in accurately predicting long-term motions. Additionally, by leveraging diffusion models' ability to capture different modes of prediction, we estimate uncertainty, significantly improving spatial awareness in human-robot interactions by incorporating zones of presence with varying confidence levels for each body joint.