 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKL-Regularised Q-Learning: A Token-level Action-Value perspective on Online RLHF
Aug 23, 2025



Proximal Policy Optimisation (PPO) is an established and effective policy gradient algorithm used for Language Model Reinforcement Learning from Human Feedback (LM-RLHF). PPO performs well empirically but has a heuristic motivation and handles the KL-divergence constraint used in LM-RLHF in an ad-hoc manner. In this paper, we develop a a new action-value RL method for the LM-RLHF setting, KL-regularised Q-Learning (KLQ). We then show that our method is equivalent to a version of PPO in a certain specific sense, despite its very different motivation. Finally, we benchmark KLQ on two key language generation tasks -- summarisation and single-turn dialogue. We demonstrate that KLQ performs on-par with PPO at optimising the LM-RLHF objective, and achieves a consistently higher win-rate against PPO on LLM-as-a-judge evaluations.
Some Notes on the Sample Complexity of Approximate Channel Simulation
May 14, 2024Channel simulation algorithms can efficiently encode random samples from a prescribed target distribution $Q$ and find applications in machine learning-based lossy data compression. However, algorithms that encode exact samples usually have random runtime, limiting their applicability when a consistent encoding time is desirable. Thus, this paper considers approximate schemes with a fixed runtime instead. First, we strengthen a result of Agustsson and Theis and show that there is a class of pairs of target distribution $Q$ and coding distribution $P$, for which the runtime of any approximate scheme scales at least super-polynomially in $D_\infty[Q \Vert P]$. We then show, by contrast, that if we have access to an unnormalised Radon-Nikodym derivative $r \propto dQ/dP$ and knowledge of $D_{KL}[Q \Vert P]$, we can exploit global-bound, depth-limited A* coding to ensure $\mathrm{TV}[Q \Vert P] \leq \epsilon$ and maintain optimal coding performance with a sample complexity of only $\exp_2\big((D_{KL}[Q \Vert P] + o(1)) \big/ \epsilon\big)$.
Efficient Algorithms for the CCA Family: Unconstrained Objectives with Unbiased Gradients
Oct 02, 2023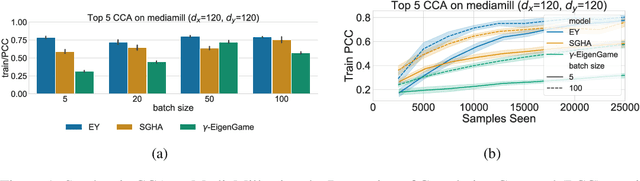

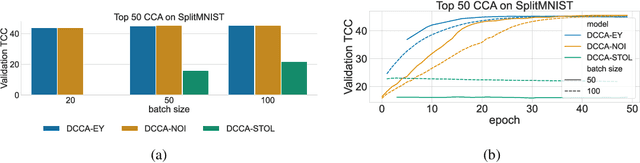

The Canonical Correlation Analysis (CCA) family of methods is foundational in multi-view learning. Regularised linear CCA methods can be seen to generalise Partial Least Squares (PLS) and unified with a Generalized Eigenvalue Problem (GEP) framework. However, classical algorithms for these linear methods are computationally infeasible for large-scale data. Extensions to Deep CCA show great promise, but current training procedures are slow and complicated. First we propose a novel unconstrained objective that characterizes the top subspace of GEPs. Our core contribution is a family of fast algorithms for stochastic PLS, stochastic CCA, and Deep CCA, simply obtained by applying stochastic gradient descent (SGD) to the corresponding CCA objectives. These methods show far faster convergence and recover higher correlations than the previous state-of-the-art on all standard CCA and Deep CCA benchmarks. This speed allows us to perform a first-of-its-kind PLS analysis of an extremely large biomedical dataset from the UK Biobank, with over 33,000 individuals and 500,000 variants. Finally, we not only match the performance of `CCA-family' Self-Supervised Learning (SSL) methods on CIFAR-10 and CIFAR-100 with minimal hyper-parameter tuning, but also establish the first solid theoretical links to classical CCA, laying the groundwork for future insights.
A Generalized EigenGame with Extensions to Multiview Representation Learning
Nov 21, 2022Generalized Eigenvalue Problems (GEPs) encompass a range of interesting dimensionality reduction methods. Development of efficient stochastic approaches to these problems would allow them to scale to larger datasets. Canonical Correlation Analysis (CCA) is one example of a GEP for dimensionality reduction which has found extensive use in problems with two or more views of the data. Deep learning extensions of CCA require large mini-batch sizes, and therefore large memory consumption, in the stochastic setting to achieve good performance and this has limited its application in practice. Inspired by the Generalized Hebbian Algorithm, we develop an approach to solving stochastic GEPs in which all constraints are softly enforced by Lagrange multipliers. Then by considering the integral of this Lagrangian function, its pseudo-utility, and inspired by recent formulations of Principal Components Analysis and GEPs as games with differentiable utilities, we develop a game-theory inspired approach to solving GEPs. We show that our approaches share much of the theoretical grounding of the previous Hebbian and game theoretic approaches for the linear case but our method permits extension to general function approximators like neural networks for certain GEPs for dimensionality reduction including CCA which means our method can be used for deep multiview representation learning. We demonstrate the effectiveness of our method for solving GEPs in the stochastic setting using canonical multiview datasets and demonstrate state-of-the-art performance for optimizing Deep CCA.