 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Hyperparameter Tuning Through Visualization and Inference
May 24, 2021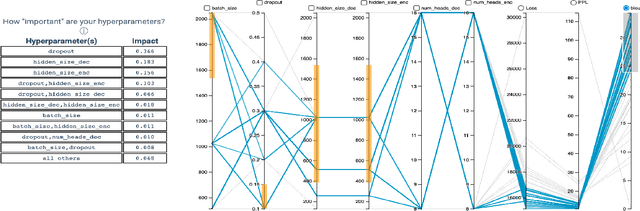
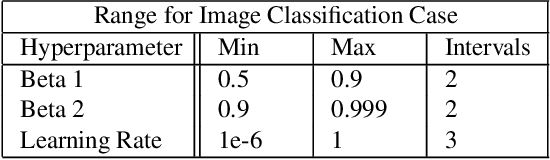
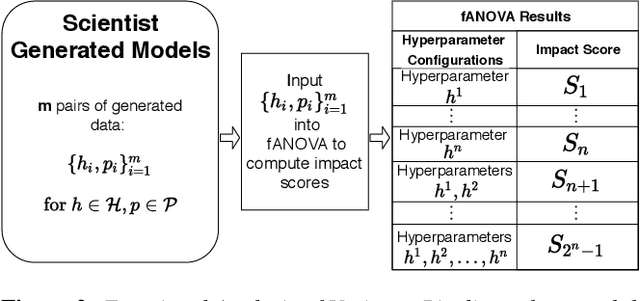
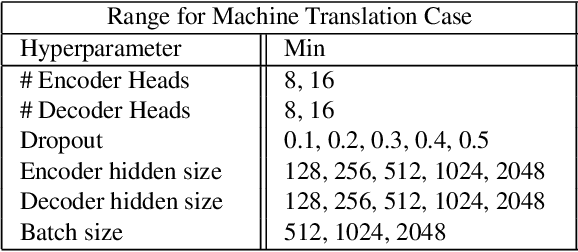
For deep learning practitioners, hyperparameter tuning for optimizing model performance can be a computationally expensive task. Though visualization can help practitioners relate hyperparameter settings to overall model performance, significant manual inspection is still required to guide the hyperparameter settings in the next batch of experiments. In response, we present a streamlined visualization system enabling deep learning practitioners to more efficiently explore, tune, and optimize hyperparameters in a batch of experiments. A key idea is to directly suggest more optimal hyperparameter values using a predictive mechanism. We then integrate this mechanism with current visualization practices for deep learning. Moreover, an analysis on the variance in a selected performance metric in the context of the model hyperparameters shows the impact that certain hyperparameters have on the performance metric. We evaluate the tool with a user study on deep learning model builders, finding that our participants have little issue adopting the tool and working with it as part of their workflow.
Indexing Cost Sensitive Prediction
Aug 15, 2014


Predictive models are often used for real-time decision making. However, typical machine learning techniques ignore feature evaluation cost, and focus solely on the accuracy of the machine learning models obtained utilizing all the features available. We develop algorithms and indexes to support cost-sensitive prediction, i.e., making decisions using machine learning models taking feature evaluation cost into account. Given an item and a online computation cost (i.e., time) budget, we present two approaches to return an appropriately chosen machine learning model that will run within the specified time on the given item. The first approach returns the optimal machine learning model, i.e., one with the highest accuracy, that runs within the specified time, but requires significant up-front precomputation time. The second approach returns a possibly sub- optimal machine learning model, but requires little up-front precomputation time. We study these two algorithms in detail and characterize the scenarios (using real and synthetic data) in which each performs well. Unlike prior work that focuses on a narrow domain or a specific algorithm, our techniques are very general: they apply to any cost-sensitive prediction scenario on any machine learning algorithm.