 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithm for Semantic Network Generation from Texts of Low Resource Languages Such as Kiswahili
Jan 16, 2025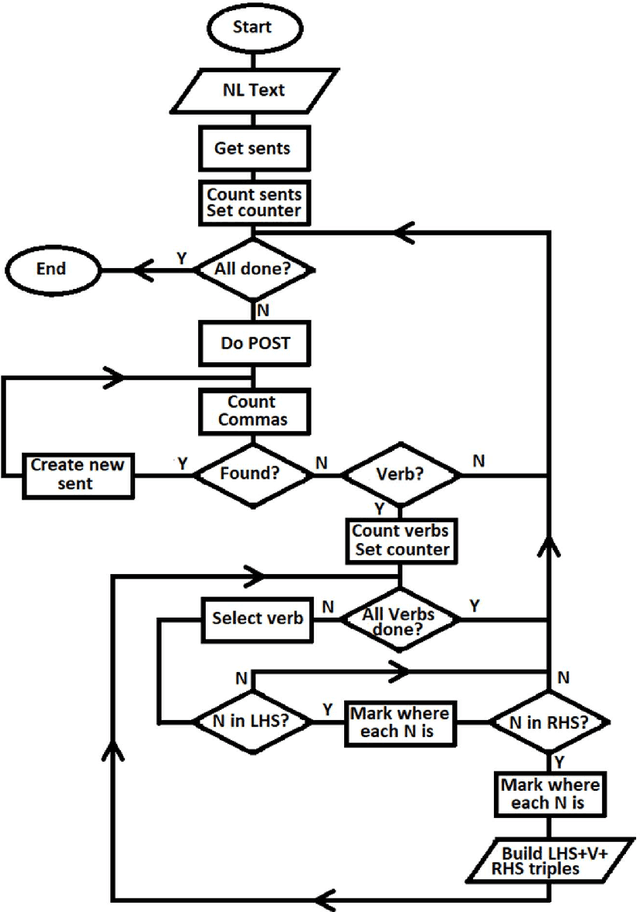
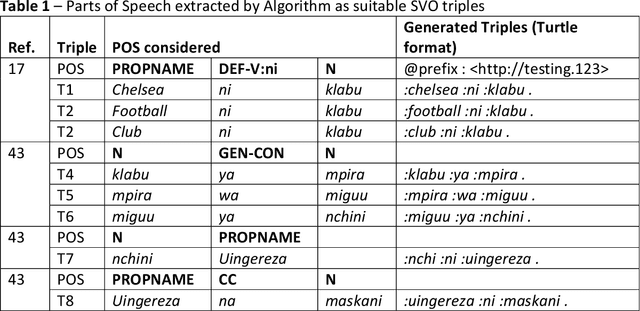


Processing low-resource languages, such as Kiswahili, using machine learning is difficult due to lack of adequate training data. However, such low-resource languages are still important for human communication and are already in daily use and users need practical machine processing tasks such as summarization, disambiguation and even question answering (QA). One method of processing such languages, while bypassing the need for training data, is the use semantic networks. Some low resource languages, such as Kiswahili, are of the subject-verb-object (SVO) structure, and similarly semantic networks are a triple of subject-predicate-object, hence SVO parts of speech tags can map into a semantic network triple. An algorithm to process raw natural language text and map it into a semantic network is therefore necessary and desirable in structuring low resource languages texts. This algorithm tested on the Kiswahili QA task with upto 78.6% exact match.
* 18 pages, 3 figures, published in Open Journal for Information Technology
Phonemic Representation and Transcription for Speech to Text Applications for Under-resourced Indigenous African Languages: The Case of Kiswahili
Oct 29, 2022


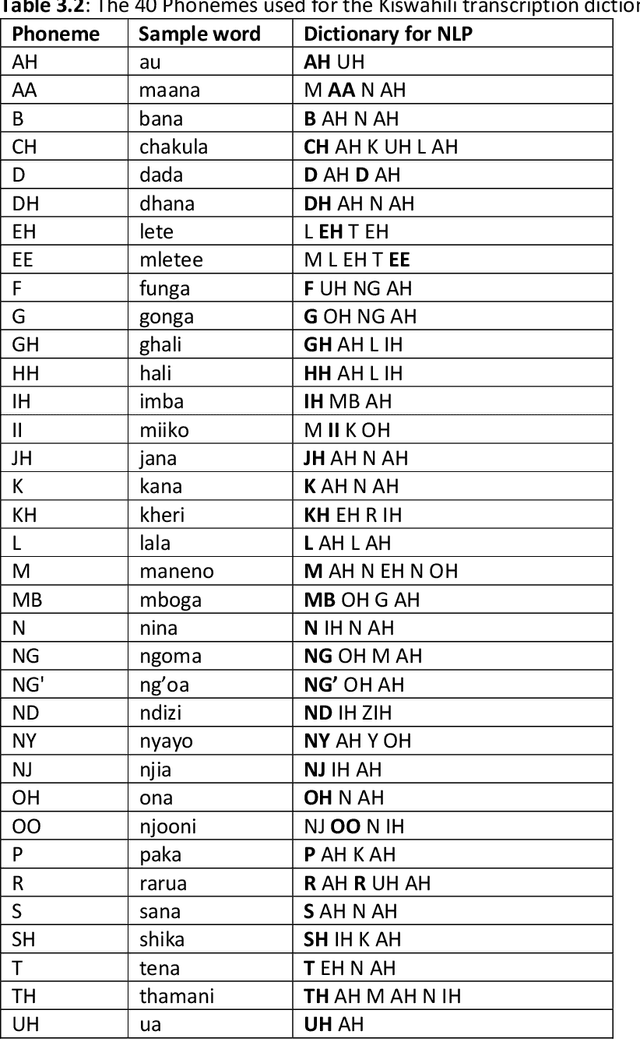
Building automatic speech recognition (ASR) systems is a challenging task, especially for under-resourced languages that need to construct corpora nearly from scratch and lack sufficient training data. It has emerged that several African indigenous languages, including Kiswahili, are technologically under-resourced. ASR systems are crucial, particularly for the hearing-impaired persons who can benefit from having transcripts in their native languages. However, the absence of transcribed speech datasets has complicated efforts to develop ASR models for these indigenous languages. This paper explores the transcription process and the development of a Kiswahili speech corpus, which includes both read-out texts and spontaneous speech data from native Kiswahili speakers. The study also discusses the vowels and consonants in Kiswahili and provides an updated Kiswahili phoneme dictionary for the ASR model that was created using the CMU Sphinx speech recognition toolbox, an open-source speech recognition toolkit. The ASR model was trained using an extended phonetic set that yielded a WER and SER of 18.87% and 49.5%, respectively, an improved performance than previous similar research for under-resourced languages.
Kencorpus: A Kenyan Language Corpus of Swahili, Dholuo and Luhya for Natural Language Processing Tasks
Aug 25, 2022

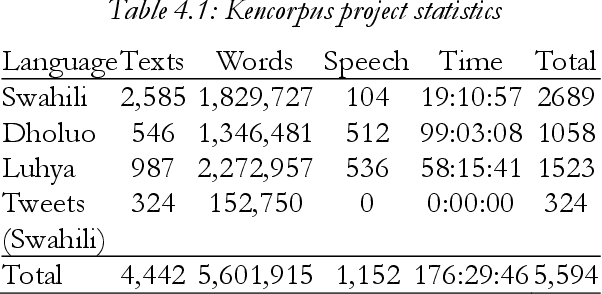
Indigenous African languages are categorized as under-served in Artificial Intelligence and suffer poor digital inclusivity and information access. The challenge has been how to use machine learning and deep learning models without the requisite data. Kencorpus is a Kenyan Language corpus that intends to bridge the gap on how to collect, and store text and speech data that is good enough to enable data-driven solutions in applications such as machine translation, question answering and transcription in multilingual communities. Kencorpus is a corpus (text and speech) for three languages predominantly spoken in Kenya: Swahili, Dholuo and Luhya (dialects Lumarachi, Lulogooli and Lubukusu). This corpus intends to fill the gap of developing a dataset that can be used for Natural Language Processing and Machine Learning tasks for low-resource languages. Each of these languages contributed text and speech data for the language corpus. Data collection was done by researchers from communities, schools and collaborating partners (media, publishers). Kencorpus has a collection of 5,594 items, being 4,442 texts (5.6million words) and 1,152 speech files (177hrs). Based on this data, other datasets were also developed e.g POS tagging sets for Dholuo and Luhya (50,000 and 93,000 words tagged respectively), Question-Answer pairs from Swahili texts (7,537 QA pairs) and Translation of texts into Swahili (12,400 sentences). The datasets are useful for machine learning tasks such as text processing, annotation and translation. The project also undertook proof of concept systems in speech to text and machine learning for QA task, with initial results confirming the usability of the Kencorpus to the machine learning community. Kencorpus is the first such corpus of its kind for these low resource languages and forms a basis of learning and sharing experiences for similar works.
KenSwQuAD -- A Question Answering Dataset for Swahili Low Resource Language
May 04, 2022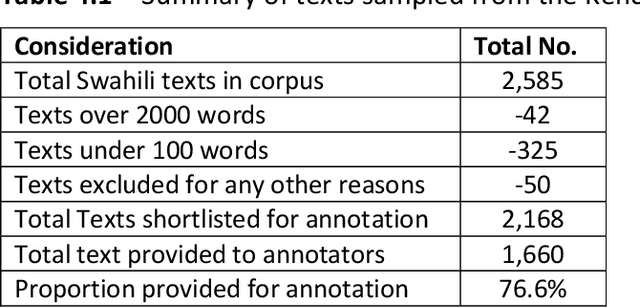
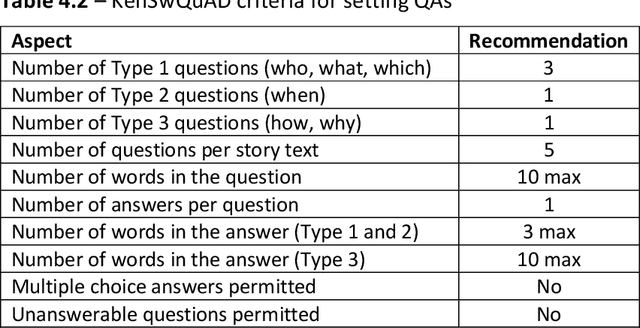


This research developed a Kencorpus Swahili Question Answering Dataset KenSwQuAD from raw data of Swahili language, which is a low resource language predominantly spoken in Eastern African and also has speakers in other parts of the world. Question Answering datasets are important for machine comprehension of natural language processing tasks such as internet search and dialog systems. However, before such machine learning systems can perform these tasks, they need training data such as the gold standard Question Answering (QA) set that is developed in this research. The research engaged annotators to formulate question answer pairs from Swahili texts that had been collected by the Kencorpus project, a Kenyan languages corpus that collected data from three Kenyan languages. The total Swahili data collection had 2,585 texts, out of which we annotated 1,445 story texts with at least 5 QA pairs each, resulting into a final dataset of 7,526 QA pairs. A quality assurance set of 12.5% of the annotated texts was subjected to re-evaluation by different annotators who confirmed that the QA pairs were all correctly annotated. A proof of concept on applying the set to machine learning on the question answering task confirmed that the dataset can be used for such practical tasks. The research therefore developed KenSwQuAD, a question-answer dataset for Swahili that is useful to the natural language processing community who need training and gold standard sets for their machine learning applications. The research also contributed to the resourcing of the Swahili language which is important for communication around the globe. Updating this set and providing similar sets for other low resource languages is an important research area that is worthy of further research.
On the Place of Text Data in Lifelogs, and Text Analysis via Semantic Facets
Jun 08, 2016Current research in lifelog data has not paid enough attention to analysis of cognitive activities in comparison to physical activities. We argue that as we look into the future, wearable devices are going to be cheaper and more prevalent and textual data will play a more significant role. Data captured by lifelogging devices will increasingly include speech and text, potentially useful in analysis of intellectual activities. Analyzing what a person hears, reads, and sees, we should be able to measure the extent of cognitive activity devoted to a certain topic or subject by a learner. Test-based lifelog records can benefit from semantic analysis tools developed for natural language processing. We show how semantic analysis of such text data can be achieved through the use of taxonomic subject facets and how these facets might be useful in quantifying cognitive activity devoted to various topics in a person's day. We are currently developing a method to automatically create taxonomic topic vocabularies that can be applied to this detection of intellectual activity.
Determining the Characteristic Vocabulary for a Specialized Dictionary using Word2vec and a Directed Crawler
May 31, 2016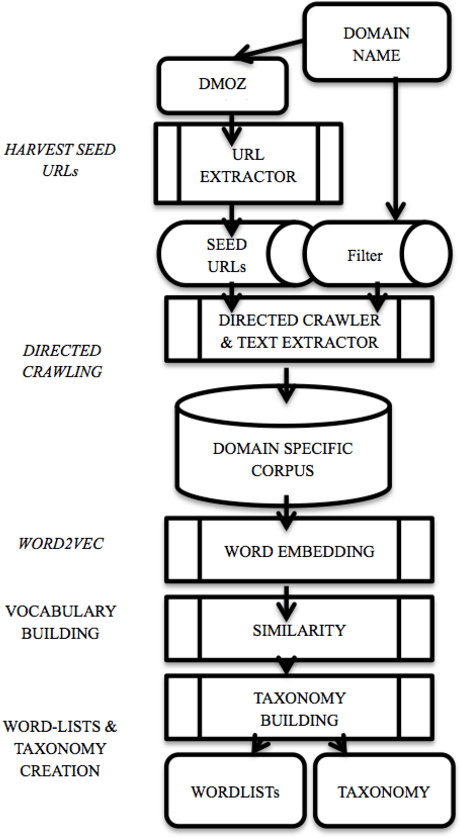
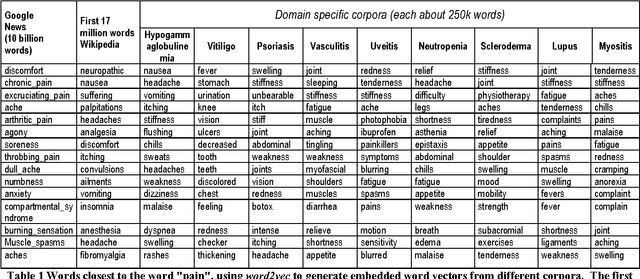
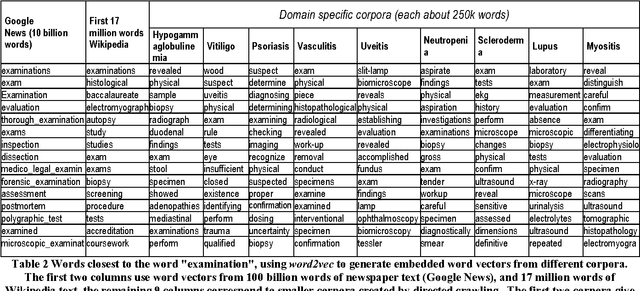
Specialized dictionaries are used to understand concepts in specific domains, especially where those concepts are not part of the general vocabulary, or having meanings that differ from ordinary languages. The first step in creating a specialized dictionary involves detecting the characteristic vocabulary of the domain in question. Classical methods for detecting this vocabulary involve gathering a domain corpus, calculating statistics on the terms found there, and then comparing these statistics to a background or general language corpus. Terms which are found significantly more often in the specialized corpus than in the background corpus are candidates for the characteristic vocabulary of the domain. Here we present two tools, a directed crawler, and a distributional semantics package, that can be used together, circumventing the need of a background corpus. Both tools are available on the web.