 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Place of Text Data in Lifelogs, and Text Analysis via Semantic Facets
Jun 08, 2016Current research in lifelog data has not paid enough attention to analysis of cognitive activities in comparison to physical activities. We argue that as we look into the future, wearable devices are going to be cheaper and more prevalent and textual data will play a more significant role. Data captured by lifelogging devices will increasingly include speech and text, potentially useful in analysis of intellectual activities. Analyzing what a person hears, reads, and sees, we should be able to measure the extent of cognitive activity devoted to a certain topic or subject by a learner. Test-based lifelog records can benefit from semantic analysis tools developed for natural language processing. We show how semantic analysis of such text data can be achieved through the use of taxonomic subject facets and how these facets might be useful in quantifying cognitive activity devoted to various topics in a person's day. We are currently developing a method to automatically create taxonomic topic vocabularies that can be applied to this detection of intellectual activity.
Determining the Characteristic Vocabulary for a Specialized Dictionary using Word2vec and a Directed Crawler
May 31, 2016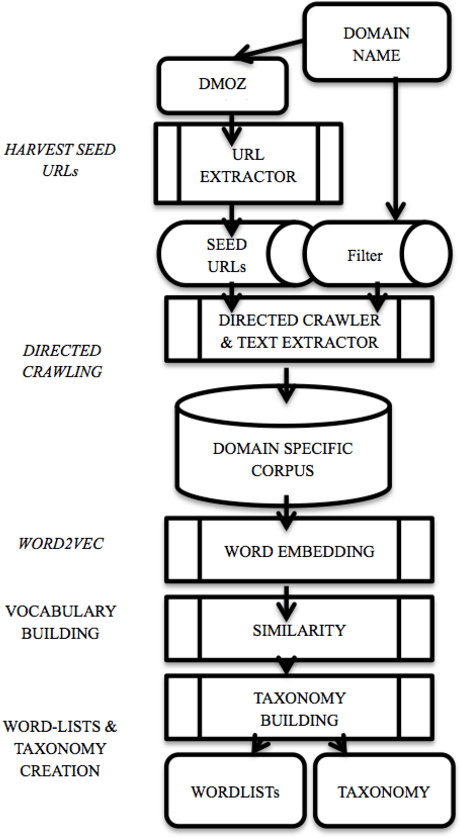
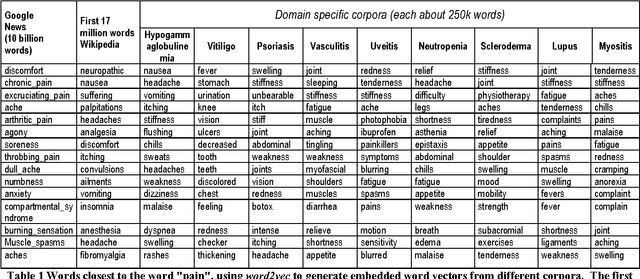
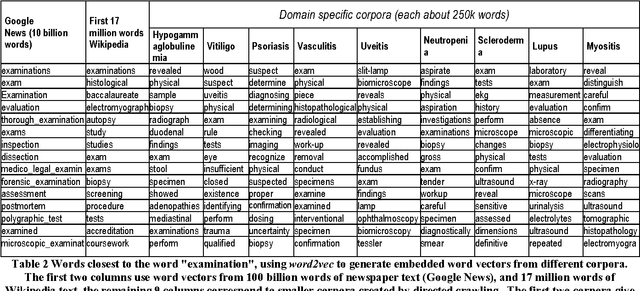
Specialized dictionaries are used to understand concepts in specific domains, especially where those concepts are not part of the general vocabulary, or having meanings that differ from ordinary languages. The first step in creating a specialized dictionary involves detecting the characteristic vocabulary of the domain in question. Classical methods for detecting this vocabulary involve gathering a domain corpus, calculating statistics on the terms found there, and then comparing these statistics to a background or general language corpus. Terms which are found significantly more often in the specialized corpus than in the background corpus are candidates for the characteristic vocabulary of the domain. Here we present two tools, a directed crawler, and a distributional semantics package, that can be used together, circumventing the need of a background corpus. Both tools are available on the web.
Transforming Wikipedia into an Ontology-based Information Retrieval Search Engine for Local Experts using a Third-Party Taxonomy
May 30, 2016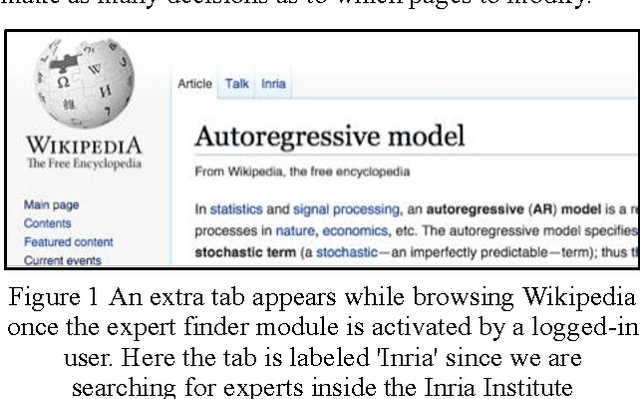
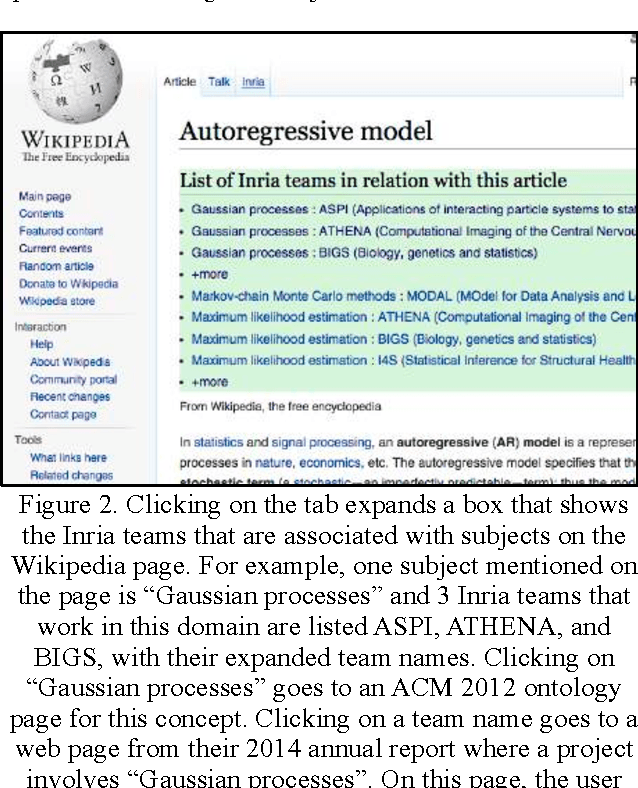
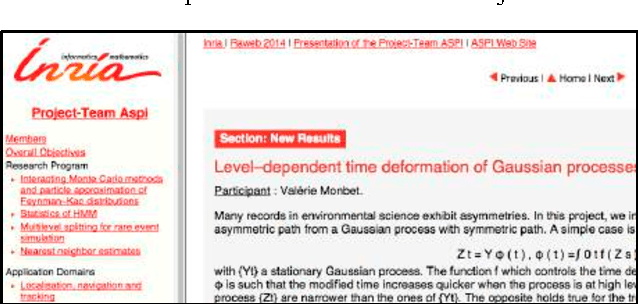
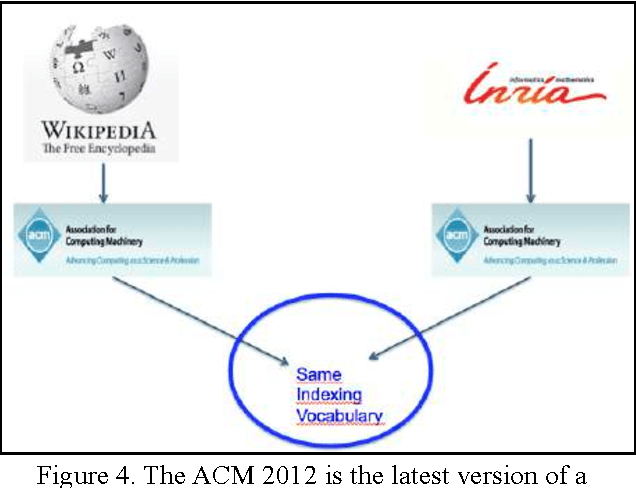
Wikipedia is widely used for finding general information about a wide variety of topics. Its vocation is not to provide local information. For example, it provides plot, cast, and production information about a given movie, but not showing times in your local movie theatre. Here we describe how we can connect local information to Wikipedia, without altering its content. The case study we present involves finding local scientific experts. Using a third-party taxonomy, independent from Wikipedia's category hierarchy, we index information connected to our local experts, present in their activity reports, and we re-index Wikipedia content using the same taxonomy. The connections between Wikipedia pages and local expert reports are stored in a relational database, accessible through as public SPARQL endpoint. A Wikipedia gadget (or plugin) activated by the interested user, accesses the endpoint as each Wikipedia page is accessed. An additional tab on the Wikipedia page allows the user to open up a list of teams of local experts associated with the subject matter in the Wikipedia page. The technique, though presented here as a way to identify local experts, is generic, in that any third party taxonomy, can be used in this to connect Wikipedia to any non-Wikipedia data source.
INRIASAC: Simple Hypernym Extraction Methods
Jan 06, 2016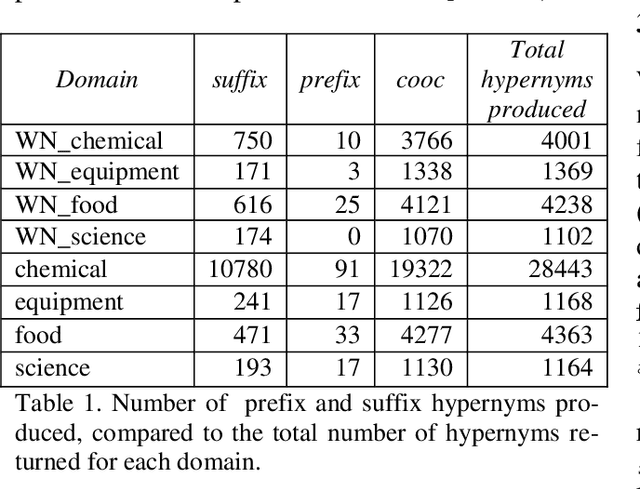


Given a set of terms from a given domain, how can we structure them into a taxonomy without manual intervention? This is the task 17 of SemEval 2015. Here we present our simple taxonomy structuring techniques which, despite their simplicity, ranked first in this 2015 benchmark. We use large quantities of text (English Wikipedia) and simple heuristics such as term overlap and document and sentence co-occurrence to produce hypernym lists. We describe these techniques and pre-sent an initial evaluation of results.
Estimation of English and non-English Language Use on the WWW
Jun 23, 2000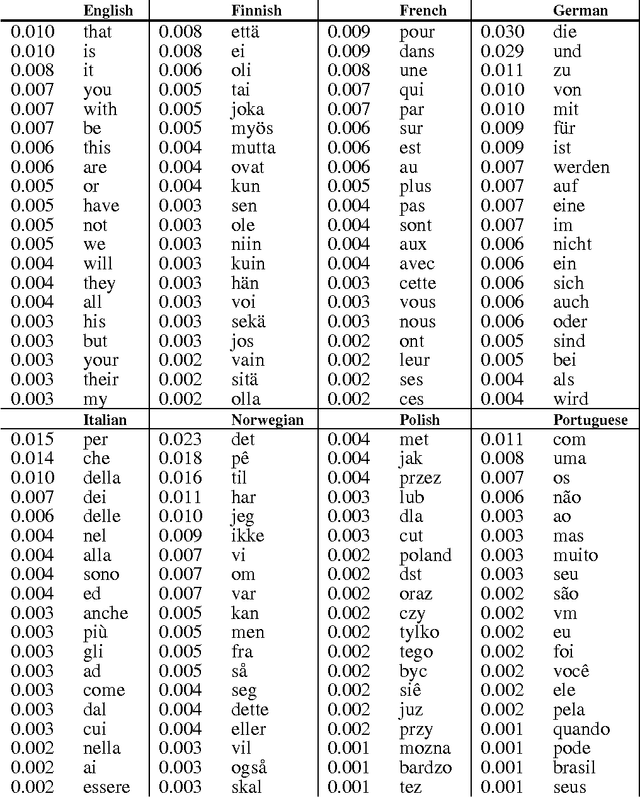
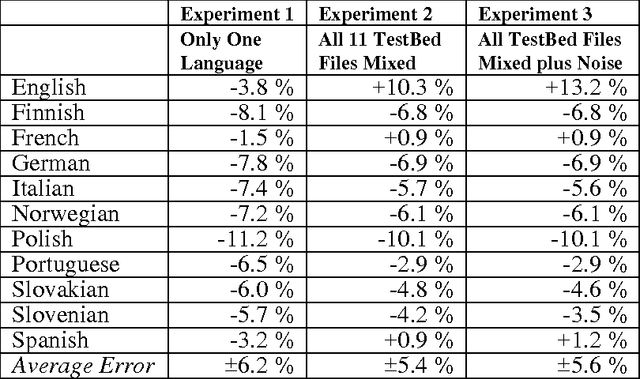
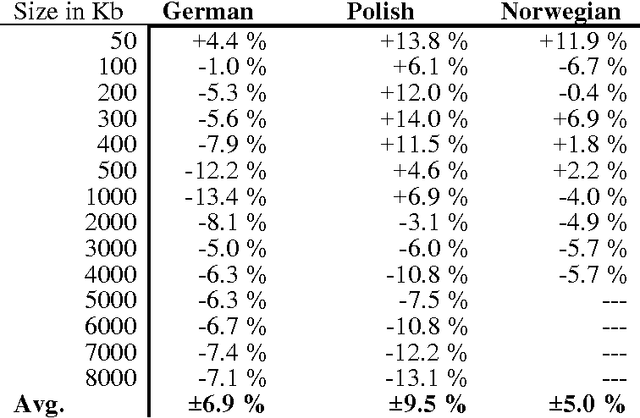

The World Wide Web has grown so big, in such an anarchic fashion, that it is difficult to describe. One of the evident intrinsic characteristics of the World Wide Web is its multilinguality. Here, we present a technique for estimating the size of a language-specific corpus given the frequency of commonly occurring words in the corpus. We apply this technique to estimating the number of words available through Web browsers for given languages. Comparing data from 1996 to data from 1999 and 2000, we calculate the growth of a number of European languages on the Web. As expected, non-English languages are growing at a faster pace than English, though the position of English is still dominant.
Corpus-based Method for Automatic Identification of Support Verbs for Nominalizations
Mar 09, 1995Nominalization is a highly productive phenomena in most languages. The process of nominalization ejects a verb from its syntactic role into a nominal position. The original verb is often replaced by a semantically emptied support verb (e.g., "make a proposal"). The choice of a support verb for a given nominalization is unpredictable, causing a problem for language learners as well as for natural language processing systems. We present here a method of discovering support verbs from an untagged corpus via low-level syntactic processing and comparison of arguments attached to verbal forms and potential nominalized forms. The result of the process is a list of potential support verbs for the nominalized form of a given predicate.