 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetinotopic Mapping Enhances the Robustness of Convolutional Neural Networks
Feb 23, 2024Foveated vision, a trait shared by many animals, including humans, has not been fully utilized in machine learning applications, despite its significant contributions to biological visual function. This study investigates whether retinotopic mapping, a critical component of foveated vision, can enhance image categorization and localization performance when integrated into deep convolutional neural networks (CNNs). Retinotopic mapping was integrated into the inputs of standard off-the-shelf convolutional neural networks (CNNs), which were then retrained on the ImageNet task. As expected, the logarithmic-polar mapping improved the network's ability to handle arbitrary image zooms and rotations, particularly for isolated objects. Surprisingly, the retinotopically mapped network achieved comparable performance in classification. Furthermore, the network demonstrated improved classification localization when the foveated center of the transform was shifted. This replicates a crucial ability of the human visual system that is absent in typical convolutional neural networks (CNNs). These findings suggest that retinotopic mapping may be fundamental to significant preattentive visual processes.
Ultra-fast image categorization in vivo and in silico
May 12, 2022
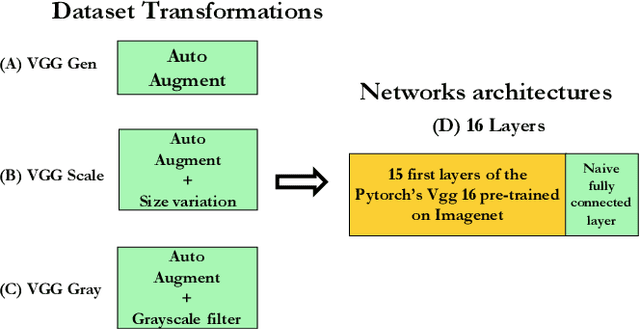
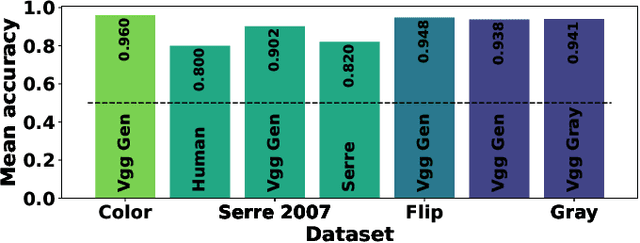
Humans are able to robustly categorize images and can, for instance, detect the presence of an animal in a briefly flashed image in as little as 120 ms. Initially inspired by neuroscience, deep-learning algorithms literally bloomed up in the last decade such that the accuracy of machines is at present superior to humans for visual recognition tasks. However, these artificial networks are usually trained and evaluated on very specific tasks, for instance on the 1000 separate categories of ImageNet. In that regard, biological visual systems are more flexible and efficient compared to artificial systems on generic ecological tasks. In order to deepen this comparison, we re-trained the standard VGG Convolutional Neural Network (CNN) on two independent tasks which are ecologically relevant for humans: one task defined as detecting the presence of an animal and the other as detecting the presence of an artifact. We show that retraining the network achieves human-like performance level which is reported in psychophysical tasks. We also compare the accuracy of the detection on an image-by-image basis. This showed in particular that the two models perform better when combining their outputs. Indeed, animals (e.g. lions) tend to be less present in photographs containing artifacts (e.g. buildings). These re-trained models could reproduce some unexpected behavioral observations from humans psychophysics such as the robustness to rotations (e.g. upside-down or slanted image) or to a grayscale transformation.
Biologically Inspired Dynamic Textures for Probing Motion Perception
Nov 09, 2015



Perception is often described as a predictive process based on an optimal inference with respect to a generative model. We study here the principled construction of a generative model specifically crafted to probe motion perception. In that context, we first provide an axiomatic, biologically-driven derivation of the model. This model synthesizes random dynamic textures which are defined by stationary Gaussian distributions obtained by the random aggregation of warped patterns. Importantly, we show that this model can equivalently be described as a stochastic partial differential equation. Using this characterization of motion in images, it allows us to recast motion-energy models into a principled Bayesian inference framework. Finally, we apply these textures in order to psychophysically probe speed perception in humans. In this framework, while the likelihood is derived from the generative model, the prior is estimated from the observed results and accounts for the perceptual bias in a principled fashion.