 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetinotopic Mapping Enhances the Robustness of Convolutional Neural Networks
Feb 23, 2024Foveated vision, a trait shared by many animals, including humans, has not been fully utilized in machine learning applications, despite its significant contributions to biological visual function. This study investigates whether retinotopic mapping, a critical component of foveated vision, can enhance image categorization and localization performance when integrated into deep convolutional neural networks (CNNs). Retinotopic mapping was integrated into the inputs of standard off-the-shelf convolutional neural networks (CNNs), which were then retrained on the ImageNet task. As expected, the logarithmic-polar mapping improved the network's ability to handle arbitrary image zooms and rotations, particularly for isolated objects. Surprisingly, the retinotopically mapped network achieved comparable performance in classification. Furthermore, the network demonstrated improved classification localization when the foveated center of the transform was shifted. This replicates a crucial ability of the human visual system that is absent in typical convolutional neural networks (CNNs). These findings suggest that retinotopic mapping may be fundamental to significant preattentive visual processes.
Concurrent Credit Assignment for Data-efficient Reinforcement Learning
May 24, 2022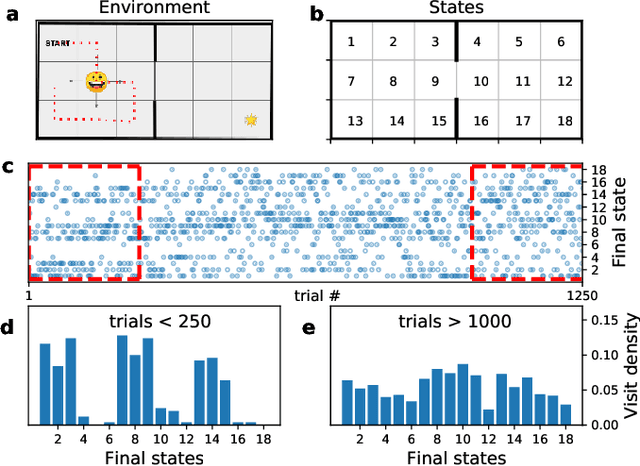
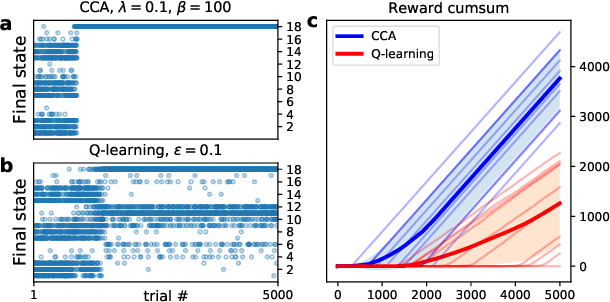
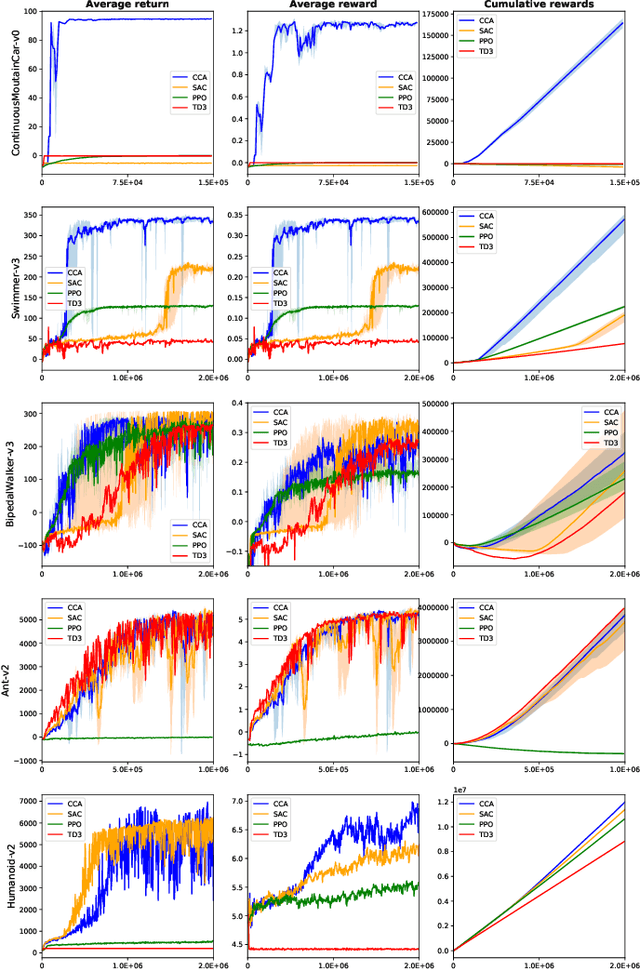
The capability to widely sample the state and action spaces is a key ingredient toward building effective reinforcement learning algorithms. The variational optimization principles exposed in this paper emphasize the importance of an occupancy model to synthesizes the general distribution of the agent's environmental states over which it can act (defining a virtual ``territory''). The occupancy model is the subject of frequent updates as the exploration progresses and that new states are undisclosed during the course of the training. By making a uniform prior assumption, the resulting objective expresses a balance between two concurrent tendencies, namely the widening of the occupancy space and the maximization of the rewards, reminding of the classical exploration/exploitation trade-off. Implemented on an actor-critic off-policy on classic continuous action benchmarks, it is shown to provide significant increase in the sampling efficacy, that is reflected in a reduced training time and higher returns, in both the dense and the sparse rewards cases.
End-Effect Exploration Drive for Effective Motor Learning
Jun 29, 2020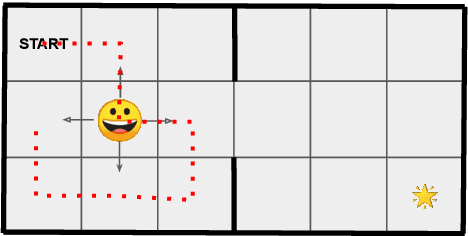
End-effect drives are proposed here as an effective way to implement goal-directed motor learning, in the absence of an explicit forward model. An end-effect model relies on a simple statistical recording of the effect of the current policy, here used as a substitute for the more resource-demanding forward models. When combined with a reward structure, it forms the core of a lightweight variational free energy minimization setup. The main difficulty lies in the maintenance of this simplified effect model together with the online update of the policy. When the prior target distribution is uniform, it provides a ways to learn an efficient exploration policy, consistently with the intrinsic curiosity principles. When combined with an extrinsic reward, our approach is finally shown to provide a faster training than traditional off-policy techniques.
Toward predictive machine learning for active vision
Jan 08, 2018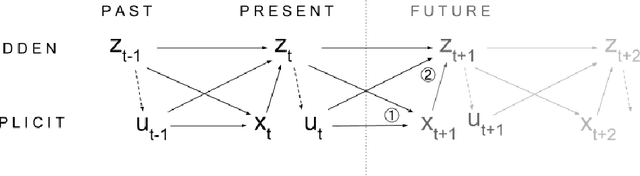
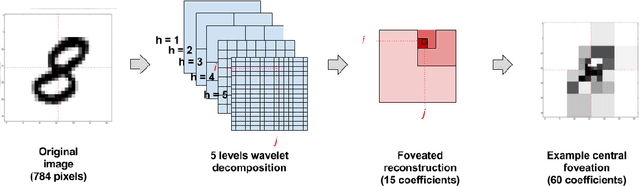
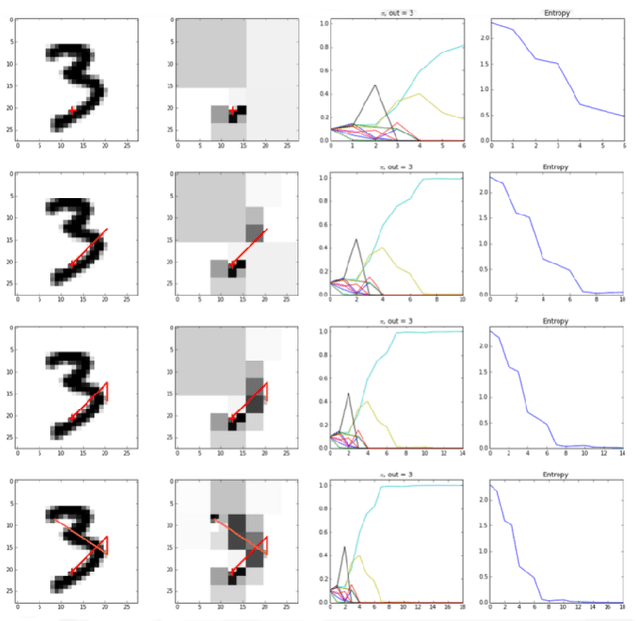
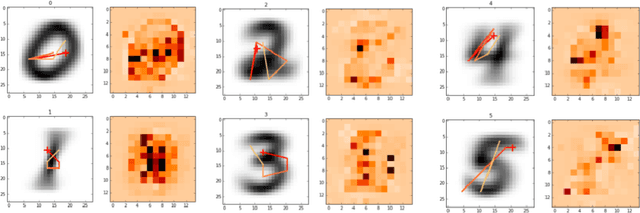
We develop a comprehensive description of the active inference framework, as proposed by Friston (2010), under a machine-learning compliant perspective. Stemming from a biological inspiration and the auto-encoding principles, the sketch of a cognitive architecture is proposed that should provide ways to implement estimation-oriented control policies. Computer simulations illustrate the effectiveness of the approach through a foveated inspection of the input data. The pros and cons of the control policy are analyzed in detail, showing interesting promises in terms of processing compression. Though optimizing future posterior entropy over the actions set is shown enough to attain locally optimal action selection, offline calculation using class-specific saliency maps is shown better for it saves processing costs through saccades pathways pre-processing, with a negligible effect on the recognition/compression rates.
Predicting the consequence of action in digital control state spaces
Sep 30, 2016The objective of this dissertation is to shed light on some fundamental impediments in learning control laws in continuous state spaces. In particular, if one wants to build artificial devices capable to learn motor tasks the same way they learn to classify signals and images, one needs to establish control rules that do not necessitate comparisons between quantities of the surrounding space. We propose, in that context, to take inspiration from the "end effector control" principle, as suggested by neuroscience studies, as opposed to the "displacement control" principle used in the classical control theory.